 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRACE: Designing Generative Face Video Codec via Agile Hardware-Centric Workflow
Nov 12, 2025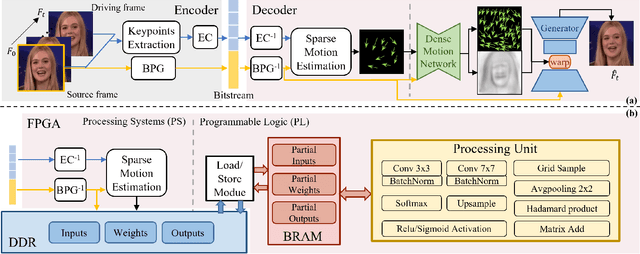


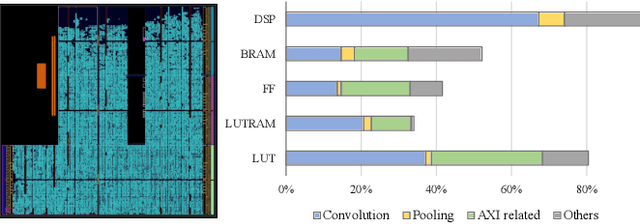
The Animation-based Generative Codec (AGC) is an emerging paradigm for talking-face video compression. However, deploying its intricate decoder on resource and power-constrained edge devices presents challenges due to numerous parameters, the inflexibility to adapt to dynamically evolving algorithms, and the high power consumption induced by extensive computations and data transmission. This paper for the first time proposes a novel field programmable gate arrays (FPGAs)-oriented AGC deployment scheme for edge-computing video services. Initially, we analyze the AGC algorithm and employ network compression methods including post-training static quantization and layer fusion techniques. Subsequently, we design an overlapped accelerator utilizing the co-processor paradigm to perform computations through software-hardware co-design. The hardware processing unit comprises engines such as convolution, grid sampling, upsample, etc. Parallelization optimization strategies like double-buffered pipelines and loop unrolling are employed to fully exploit the resources of FPGA. Ultimately, we establish an AGC FPGA prototype on the PYNQ-Z1 platform using the proposed scheme, achieving \textbf{24.9$\times$} and \textbf{4.1$\times$} higher energy efficiency against commercial Central Processing Unit (CPU) and Graphic Processing Unit (GPU), respectively. Specifically, only \textbf{11.7} microjoules ($\upmu$J) are required for one pixel reconstructed by this FPGA system.
Adaptive Sampling Scheduler
Sep 16, 2025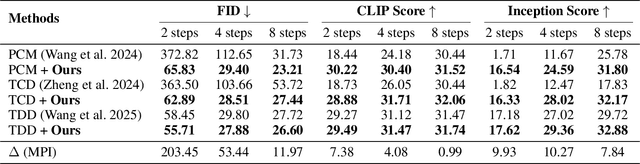
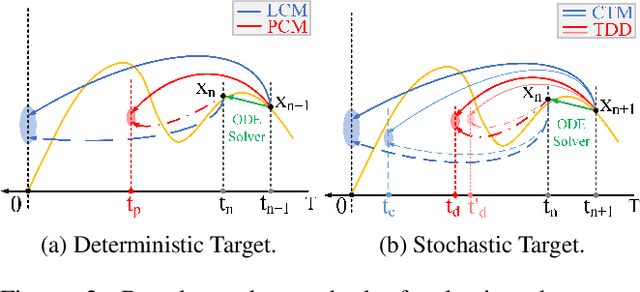
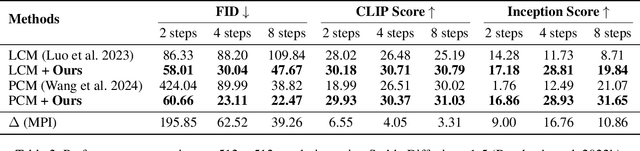
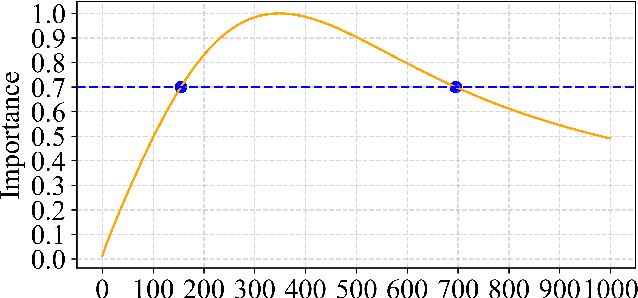
Consistent distillation methods have evolved into effective techniques that significantly accelerate the sampling process of diffusion models. Although existing methods have achieved remarkable results, the selection of target timesteps during distillation mainly relies on deterministic or stochastic strategies, which often require sampling schedulers to be designed specifically for different distillation processes. Moreover, this pattern severely limits flexibility, thereby restricting the full sampling potential of diffusion models in practical applications. To overcome these limitations, this paper proposes an adaptive sampling scheduler that is applicable to various consistency distillation frameworks. The scheduler introduces three innovative strategies: (i) dynamic target timestep selection, which adapts to different consistency distillation frameworks by selecting timesteps based on their computed importance; (ii) Optimized alternating sampling along the solution trajectory by guiding forward denoising and backward noise addition based on the proposed time step importance, enabling more effective exploration of the solution space to enhance generation performance; and (iii) Utilization of smoothing clipping and color balancing techniques to achieve stable and high-quality generation results at high guidance scales, thereby expanding the applicability of consistency distillation models in complex generation scenarios. We validated the effectiveness and flexibility of the adaptive sampling scheduler across various consistency distillation methods through comprehensive experimental evaluations. Experimental results consistently demonstrated significant improvements in generative performance, highlighting the strong adaptability achieved by our method.
TopKD: Top-scaled Knowledge Distillation
Aug 06, 2025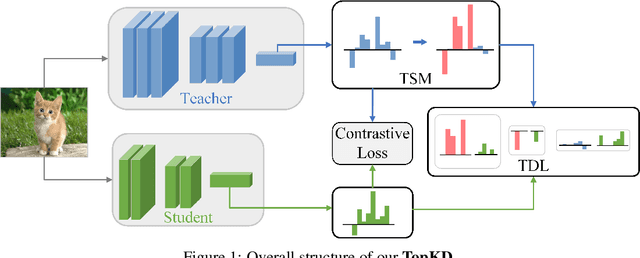
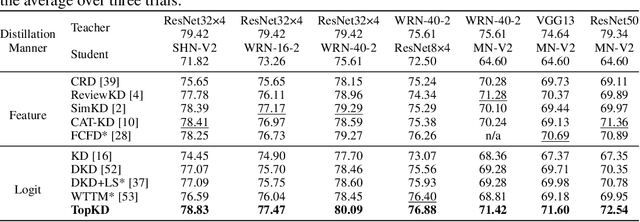
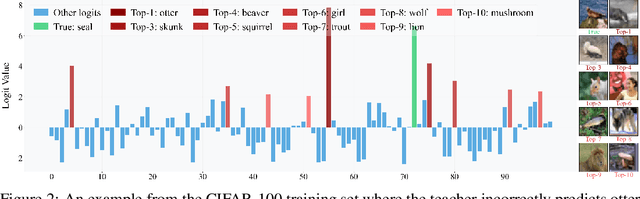
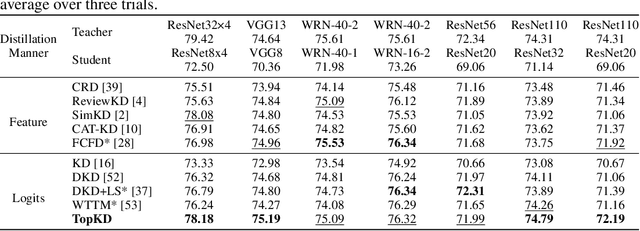
Recent advances in knowledge distillation (KD) predominantly emphasize feature-level knowledge transfer, frequently overlooking critical information embedded within the teacher's logit distributions. In this paper, we revisit logit-based distillation and reveal an underexplored yet critical element: Top-K knowledge. Motivated by this insight, we propose Top-scaled Knowledge Distillation (TopKD), a simple, efficient, and architecture-agnostic framework that significantly enhances logit-based distillation. TopKD consists of two main components: (1) a Top-K Scaling Module (TSM), which adaptively amplifies the most informative logits, and (2) a Top-K Decoupled Loss (TDL), which offers targeted and effective supervision. Notably, TopKD integrates seamlessly into existing KD methods without introducing extra modules or requiring architectural changes. Extensive experiments on CIFAR-100, ImageNet, STL-10, and Tiny-ImageNet demonstrate that TopKD consistently surpasses state-of-the-art distillation methods. Moreover, our method demonstrates substantial effectiveness when distilling Vision Transformers, underscoring its versatility across diverse network architectures. These findings highlight the significant potential of logits to advance knowledge distillation.
Audio-Visual Driven Compression for Low-Bitrate Talking Head Videos
Jun 16, 2025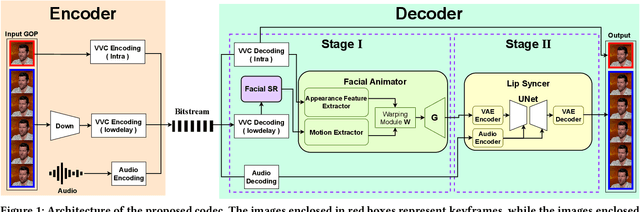
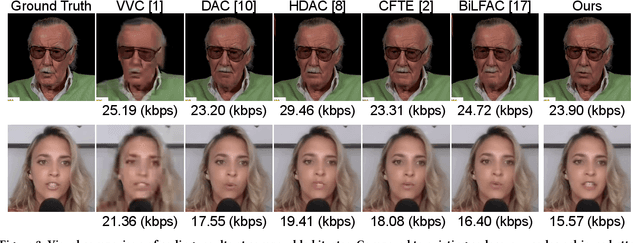

Talking head video compression has advanced with neural rendering and keypoint-based methods, but challenges remain, especially at low bit rates, including handling large head movements, suboptimal lip synchronization, and distorted facial reconstructions. To address these problems, we propose a novel audio-visual driven video codec that integrates compact 3D motion features and audio signals. This approach robustly models significant head rotations and aligns lip movements with speech, improving both compression efficiency and reconstruction quality. Experiments on the CelebV-HQ dataset show that our method reduces bitrate by 22% compared to VVC and by 8.5% over state-of-the-art learning-based codec. Furthermore, it provides superior lip-sync accuracy and visual fidelity at comparable bitrates, highlighting its effectiveness in bandwidth-constrained scenarios.
Bidirectional Learned Facial Animation Codec for Low Bitrate Talking Head Videos
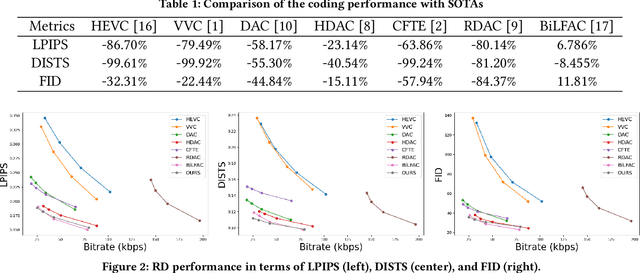
Mar 12, 2025Existing deep facial animation coding techniques efficiently compress talking head videos by applying deep generative models. Instead of compressing the entire video sequence, these methods focus on compressing only the keyframe and the keypoints of non-keyframes (target frames). The target frames are then reconstructed by utilizing a single keyframe, and the keypoints of the target frame. Although these unidirectional methods can reduce the bitrate, they rely on a single keyframe and often struggle to capture large head movements accurately, resulting in distortions in the facial region. In this paper, we propose a novel bidirectional learned animation codec that generates natural facial videos using past and future keyframes. First, in the Bidirectional Reference-Guided Auxiliary Stream Enhancement (BRG-ASE) process, we introduce a compact auxiliary stream for non-keyframes, which is enhanced by adaptively selecting one of two keyframes (past and future). This stream improves video quality with a slight increase in bitrate. Then, in the Bidirectional Reference-Guided Video Reconstruction (BRG-VRec) process, we animate the adaptively selected keyframe and reconstruct the target frame using both the animated keyframe and the auxiliary frame. Extensive experiments demonstrate a 55% bitrate reduction compared to the latest animation based video codec, and a 35% bitrate reduction compared to the latest video coding standard, Versatile Video Coding (VVC) on a talking head video dataset. It showcases the efficiency of our approach in improving video quality while simultaneously decreasing bitrate.
Unicorn: Unified Neural Image Compression with One Number Reconstruction
Dec 11, 2024Prevalent lossy image compression schemes can be divided into: 1) explicit image compression (EIC), including traditional standards and neural end-to-end algorithms; 2) implicit image compression (IIC) based on implicit neural representations (INR). The former is encountering impasses of either leveling off bitrate reduction at a cost of tremendous complexity while the latter suffers from excessive smoothing quality as well as lengthy decoder models. In this paper, we propose an innovative paradigm, which we dub \textbf{Unicorn} (\textbf{U}nified \textbf{N}eural \textbf{I}mage \textbf{C}ompression with \textbf{O}ne \textbf{N}number \textbf{R}econstruction). By conceptualizing the images as index-image pairs and learning the inherent distribution of pairs in a subtle neural network model, Unicorn can reconstruct a visually pleasing image from a randomly generated noise with only one index number. The neural model serves as the unified decoder of images while the noises and indexes corresponds to explicit representations. As a proof of concept, we propose an effective and efficient prototype of Unicorn based on latent diffusion models with tailored model designs. Quantitive and qualitative experimental results demonstrate that our prototype achieves significant bitrates reduction compared with EIC and IIC algorithms. More impressively, benefitting from the unified decoder, our compression ratio escalates as the quantity of images increases. We envision that more advanced model designs will endow Unicorn with greater potential in image compression. We will release our codes in \url{https://github.com/uniqzheng/Unicorn-Laduree}.
TKG-DM: Training-free Chroma Key Content Generation Diffusion Model
Nov 23, 2024



Diffusion models have enabled the generation of high-quality images with a strong focus on realism and textual fidelity. Yet, large-scale text-to-image models, such as Stable Diffusion, struggle to generate images where foreground objects are placed over a chroma key background, limiting their ability to separate foreground and background elements without fine-tuning. To address this limitation, we present a novel Training-Free Chroma Key Content Generation Diffusion Model (TKG-DM), which optimizes the initial random noise to produce images with foreground objects on a specifiable color background. Our proposed method is the first to explore the manipulation of the color aspects in initial noise for controlled background generation, enabling precise separation of foreground and background without fine-tuning. Extensive experiments demonstrate that our training-free method outperforms existing methods in both qualitative and quantitative evaluations, matching or surpassing fine-tuned models. Finally, we successfully extend it to other tasks (e.g., consistency models and text-to-video), highlighting its transformative potential across various generative applications where independent control of foreground and background is crucial.
Multi-perspective Contrastive Logit Distillation
Nov 16, 2024



We propose a novel and efficient logit distillation method, Multi-perspective Contrastive Logit Distillation (MCLD), which leverages contrastive learning to distill logits from multiple perspectives in knowledge distillation. Recent research on logit distillation has primarily focused on maximizing the information learned from the teacher model's logits to enhance the performance of the student model. To this end, we propose MCLD, which consists of three key components: Instance-wise CLD, Sample-wise CLD, and Category-wise CLD. These components are designed to facilitate the transfer of more information from the teacher's logits to the student model. Comprehensive evaluations on image classification tasks using CIFAR-100 and ImageNet, alongside representation transferability assessments on STL-10 and Tiny-ImageNet, highlight the significant advantages of our method. The knowledge distillation with our MCLD, surpasses existing state-of-the-art methods.
Block based Adaptive Compressive Sensing with Sampling Rate Control
Nov 15, 2024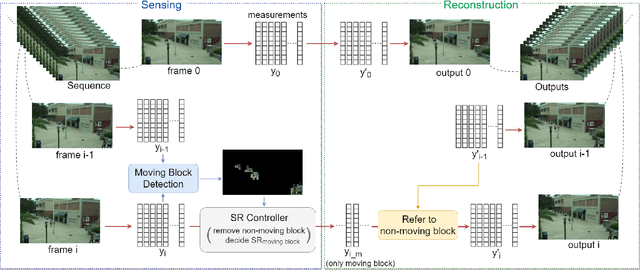
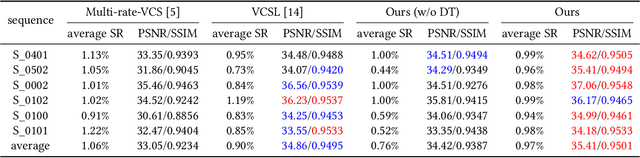
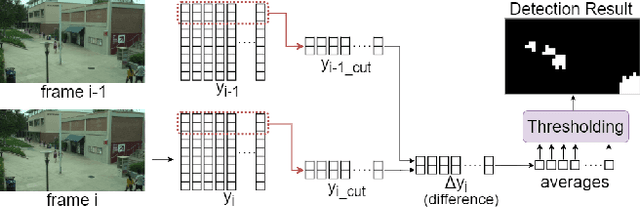
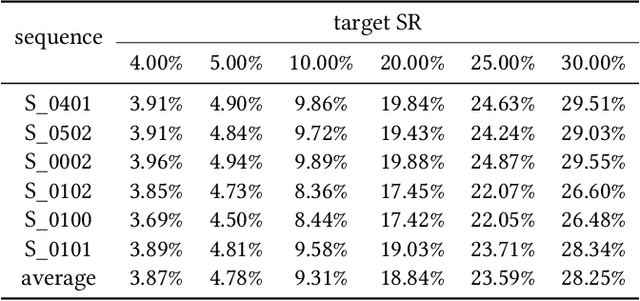
Compressive sensing (CS), acquiring and reconstructing signals below the Nyquist rate, has great potential in image and video acquisition to exploit data redundancy and greatly reduce the amount of sampled data. To further reduce the sampled data while keeping the video quality, this paper explores the temporal redundancy in video CS and proposes a block based adaptive compressive sensing framework with a sampling rate (SR) control strategy. To avoid redundant compression of non-moving regions, we first incorporate moving block detection between consecutive frames, and only transmit the measurements of moving blocks. The non-moving regions are reconstructed from the previous frame. In addition, we propose a block storage system and a dynamic threshold to achieve adaptive SR allocation to each frame based on the area of moving regions and target SR for controlling the average SR within the target SR. Finally, to reduce blocking artifacts and improve reconstruction quality, we adopt a cooperative reconstruction of the moving and non-moving blocks by referring to the measurements of the non-moving blocks from the previous frame. Extensive experiments have demonstrated that this work is able to control SR and obtain better performance than existing works.
Visual question answering based evaluation metrics for text-to-image generation
Nov 15, 2024Text-to-image generation and text-guided image manipulation have received considerable attention in the field of image generation tasks. However, the mainstream evaluation methods for these tasks have difficulty in evaluating whether all the information from the input text is accurately reflected in the generated images, and they mainly focus on evaluating the overall alignment between the input text and the generated images. This paper proposes new evaluation metrics that assess the alignment between input text and generated images for every individual object. Firstly, according to the input text, chatGPT is utilized to produce questions for the generated images. After that, we use Visual Question Answering(VQA) to measure the relevance of the generated images to the input text, which allows for a more detailed evaluation of the alignment compared to existing methods. In addition, we use Non-Reference Image Quality Assessment(NR-IQA) to evaluate not only the text-image alignment but also the quality of the generated images. Experimental results show that our proposed evaluation approach is the superior metric that can simultaneously assess finer text-image alignment and image quality while allowing for the adjustment of these ratios.