 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Multi-Domain Chinese User Simulation via Self-Evolving Profiles and Rubric-Guided Alignment
Apr 15, 2026User simulators are essential for the scalable training and evaluation of interactive AI systems. However, existing approaches often rely on shallow user profiling, struggle to maintain persona consistency over long interactions, and are largely limited to English or single-domain settings. We present MUSE, a multi-domain Chinese user simulation framework designed to generate human-like, controllable, and behaviorally consistent responses. First, we propose Iterative Profile Self-Evolution (IPSE), which gradually optimizes user profiles by comparing and reasoning discrepancies between simulated trajectories and real dialogue behaviors. We then apply Role-Reversal Supervised Fine-Tuning to improve local response realism and human-like expression. To enable fine-grained behavioral alignment, we further train a specialized rubric-based reward model and incorporate it into rubric-guided multi-turn reinforcement learning, which optimizes the simulator at the dialogue level and enhances long-horizon behavioral consistency. Experiments show that MUSE consistently outperforms strong baselines in both utterance-level and session-level evaluations, generating responses that are more realistic, coherent, and persona-consistent over extended interactions.
ESOM: Efficiently Understanding Streaming Video Anomalies with Open-world Dynamic Definitions
Apr 09, 2026Open-world video anomaly detection (OWVAD) aims to detect and explain abnormal events under different anomaly definitions, which is important for applications such as intelligent surveillance and live-streaming content moderation. Recent MLLM-based methods have shown promising open-world generalization, but still suffer from three major limitations: inefficiency for practical deployment, lack of streaming processing adaptation, and limited support for dynamic anomaly definitions in both modeling and evaluation. To address these issues, this paper proposes ESOM, an efficient streaming OWVAD model that operates in a training-free manner. ESOM includes a Definition Normalization module to structure user prompts for reducing hallucination, an Inter-frame-matched Intra-frame Token Merging module to compress redundant visual tokens, a Hybrid Streaming Memory module for efficient causal inference, and a Probabilistic Scoring module that converts interval-level textual outputs into frame-level anomaly scores. In addition, this paper introduces OpenDef-Bench, a new benchmark with clean surveillance videos and diverse natural anomaly definitions for evaluating performance under varying conditions. Extensive experiments show that ESOM achieves real-time efficiency on a single GPU and state-of-the-art performance in anomaly temporal localization, classification, and description generation. The code and benchmark will be released at https://github.com/Kamino666/ESOM_OpenDef-Bench.
Learning Smooth and Robust Space Robotic Manipulation of Dynamic Target via Inter-frame Correlation
Mar 29, 2026On-orbit servicing represents a critical frontier in future aerospace engineering, with the manipulation of dynamic non-cooperative targets serving as a key technology. In microgravity environments, objects are typically free-floating, lacking the support and frictional constraints found on Earth, which significantly escalates the complexity of tasks involving space robotic manipulation. Conventional planning and control-based methods are primarily limited to known, static scenarios and lack real-time responsiveness. To achieve precise robotic manipulation of dynamic targets in unknown and unstructured space environments, this letter proposes a data-driven space robotic manipulation approach that integrates historical temporal information and inter-frame correlation mechanisms. By exploiting the temporal correlation between historical and current frames, the system can effectively capture motion features within the scene, thereby producing stable and smooth manipulation trajectories for dynamic targets. To validate the effectiveness of the proposed method, we developed a ground-based experimental platform consisting of a PIPER X robotic arm and a dual-axis linear stage, which accurately simulates micro-gravity free-floating motion in a 2D plane.
TED: Training-Free Experience Distillation for Multimodal Reasoning
Mar 25, 2026Knowledge distillation is typically realized by transferring a teacher model's knowledge into a student's parameters through supervised or reinforcement-based optimization. While effective, such approaches require repeated parameter updates and large-scale training data, limiting their applicability in resource-constrained environments. In this work, we propose TED, a training-free, context-based distillation framework that shifts the update target of distillation from model parameters to an in-context experience injected into the student's prompt. For each input, the student generates multiple reasoning trajectories, while a teacher independently produces its own solution. The teacher then compares the student trajectories with its reasoning and the ground-truth answer, extracting generalized experiences that capture effective reasoning patterns. These experiences are continuously refined and updated over time. A key challenge of context-based distillation is unbounded experience growth and noise accumulation. TED addresses this with an experience compression mechanism that tracks usage statistics and selectively merges, rewrites, or removes low-utility experiences. Experiments on multimodal reasoning benchmarks MathVision and VisualPuzzles show that TED consistently improves performance. On MathVision, TED raises the performance of Qwen3-VL-8B from 0.627 to 0.702, and on VisualPuzzles from 0.517 to 0.561 with just 100 training samples. Under this low-data, no-update setting, TED achieves performance competitive with fully trained parameter-based distillation while reducing training cost by over 5x, demonstrating that meaningful knowledge transfer can be achieved through contextual experience.
RoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Mar 13, 2026Scalable Embodied AI faces fundamental constraints due to prohibitive costs and safety risks of real-world interaction. While Embodied World Models (EWMs) offer promise through imagined rollouts, existing approaches suffer from geometric hallucinations and lack unified optimization frameworks for practical policy improvement. We introduce RoboStereo, a symmetric dual-tower 4D world model that employs bidirectional cross-modal enhancement to ensure spatiotemporal geometric consistency and alleviate physics hallucinations. Building upon this high-fidelity 4D simulator, we present the first unified framework for world-model-based policy optimization: (1) Test-Time Policy Augmentation (TTPA) for pre-execution verification, (2) Imitative-Evolutionary Policy Learning (IEPL) leveraging visual perceptual rewards to learn from expert demonstrations, and (3) Open-Exploration Policy Learning (OEPL) enabling autonomous skill discovery and self-correction. Comprehensive experiments demonstrate RoboStereo achieves state-of-the-art generation quality, with our unified framework delivering >97% average relative improvement on fine-grained manipulation tasks.
DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025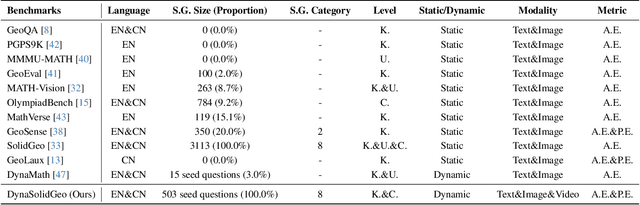
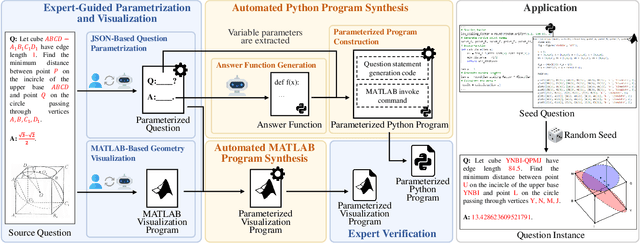
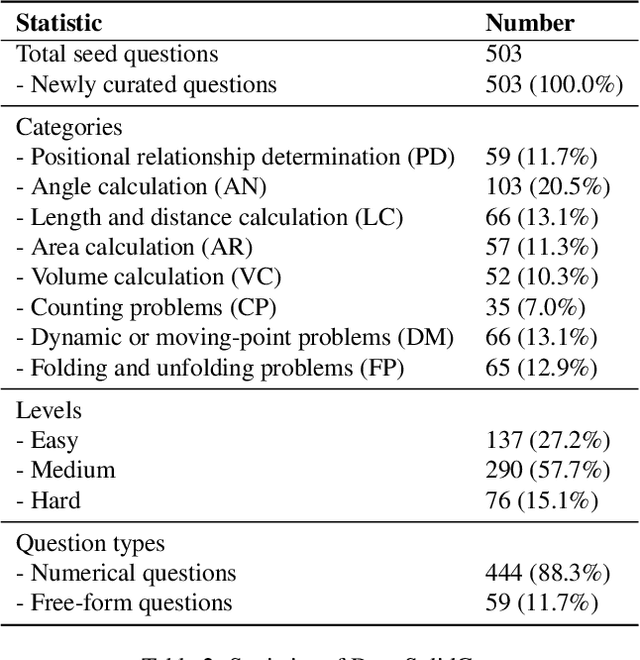
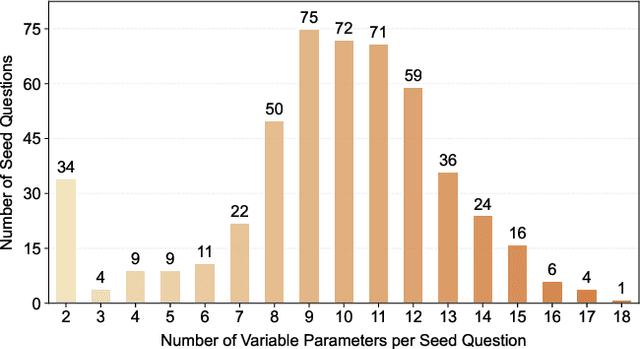
Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.
MLVTG: Mamba-Based Feature Alignment and LLM-Driven Purification for Multi-Modal Video Temporal Grounding
Jun 10, 2025Video Temporal Grounding (VTG), which aims to localize video clips corresponding to natural language queries, is a fundamental yet challenging task in video understanding. Existing Transformer-based methods often suffer from redundant attention and suboptimal multi-modal alignment. To address these limitations, we propose MLVTG, a novel framework that integrates two key modules: MambaAligner and LLMRefiner. MambaAligner uses stacked Vision Mamba blocks as a backbone instead of Transformers to model temporal dependencies and extract robust video representations for multi-modal alignment. LLMRefiner leverages the specific frozen layer of a pre-trained Large Language Model (LLM) to implicitly transfer semantic priors, enhancing multi-modal alignment without fine-tuning. This dual alignment strategy, temporal modeling via structured state-space dynamics and semantic purification via textual priors, enables more precise localization. Extensive experiments on QVHighlights, Charades-STA, and TVSum demonstrate that MLVTG achieves state-of-the-art performance and significantly outperforms existing baselines.
Rethinking Metrics and Benchmarks of Video Anomaly Detection
May 25, 2025Video Anomaly Detection (VAD), which aims to detect anomalies that deviate from expectation, has attracted increasing attention in recent years. Existing advancements in VAD primarily focus on model architectures and training strategies, while devoting insufficient attention to evaluation metrics and benchmarks. In this paper, we rethink VAD evaluation protocols through comprehensive experimental analyses, revealing three critical limitations in current practices: 1) existing metrics are significantly influenced by single annotation bias; 2) current metrics fail to reward early detection of anomalies; 3) available benchmarks lack the capability to evaluate scene overfitting. To address these limitations, we propose three novel evaluation methods: first, we establish averaged AUC/AP metrics over multi-round annotations to mitigate single annotation bias; second, we develop a Latency-aware Average Precision (LaAP) metric that rewards early and accurate anomaly detection; and finally, we introduce two hard normal benchmarks (UCF-HN, MSAD-HN) with videos specifically designed to evaluate scene overfitting. We report performance comparisons of ten state-of-the-art VAD approaches using our proposed evaluation methods, providing novel perspectives for future VAD model development.
Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
Apr 14, 2025Automating the synthesis of coordinated bimanual piano performances poses significant challenges, particularly in capturing the intricate choreography between the hands while preserving their distinct kinematic signatures. In this paper, we propose a dual-stream neural framework designed to generate synchronized hand gestures for piano playing from audio input, addressing the critical challenge of modeling both hand independence and coordination. Our framework introduces two key innovations: (i) a decoupled diffusion-based generation framework that independently models each hand's motion via dual-noise initialization, sampling distinct latent noise for each while leveraging a shared positional condition, and (ii) a Hand-Coordinated Asymmetric Attention (HCAA) mechanism suppresses symmetric (common-mode) noise to highlight asymmetric hand-specific features, while adaptively enhancing inter-hand coordination during denoising. The system operates hierarchically: it first predicts 3D hand positions from audio features and then generates joint angles through position-aware diffusion models, where parallel denoising streams interact via HCAA. Comprehensive evaluations demonstrate that our framework outperforms existing state-of-the-art methods across multiple metrics.
Curiosity-Diffuser: Curiosity Guide Diffusion Models for Reliability
Mar 19, 2025One of the bottlenecks in robotic intelligence is the instability of neural network models, which, unlike control models, lack a well-defined convergence domain and stability. This leads to risks when applying intelligence in the physical world. Specifically, imitation policy based on neural network may generate hallucinations, leading to inaccurate behaviors that impact the safety of real-world applications. To address this issue, this paper proposes the Curiosity-Diffuser, aimed at guiding the conditional diffusion model to generate trajectories with lower curiosity, thereby improving the reliability of policy. The core idea is to use a Random Network Distillation (RND) curiosity module to assess whether the model's behavior aligns with the training data, and then minimize curiosity by classifier guidance diffusion to reduce overgeneralization during inference. Additionally, we propose a computationally efficient metric for evaluating the reliability of the policy, measuring the similarity between the generated behaviors and the training dataset, to facilitate research about reliability learning. Finally, simulation verify the effectiveness and applicability of the proposed method to a variety of scenarios, showing that Curiosity-Diffuser significantly improves task performance and produces behaviors that are more similar to the training data. The code for this work is available at: github.com/CarlDegio/Curiosity-Diffuser