 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagleVision: A Multi-Task Benchmark for Cross-Domain Perception in High-Speed Autonomous Racing
Apr 13, 2026High-speed autonomous racing presents extreme perception challenges, including large relative velocities and substantial domain shifts from conventional urban-driving datasets. Existing benchmarks do not adequately capture these high-dynamic conditions. We introduce EagleVision, a unified LiDAR-based multi-task benchmark for 3D detection and trajectory prediction in high-speed racing, providing newly annotated 3D bounding boxes for the Indy Autonomous Challenge dataset (14,893 frames) and the A2RL Real competition dataset (1,163 frames), together with 12,000 simulator-generated annotated frames, all standardized under a common evaluation protocol. Using a dataset-centric transfer framework, we quantify cross-domain generalization across urban, simulator, and real racing domains. Urban pretraining improves detection over scratch training (NDS 0.72 vs. 0.69), while intermediate pretraining on real racing data achieves the best transfer to A2RL (NDS 0.726), outperforming simulator-only adaptation. For trajectory prediction, Indy-trained models surpass in-domain A2RL training on A2RL test sequences (FDE 0.947 vs. 1.250), highlighting the role of motion-distribution coverage in cross-domain forecasting. EagleVision enables systematic study of perception generalization under extreme high-speed dynamics. The dataset and benchmark are publicly available at https://avlab.io/EagleVision
Implicit Strategic Optimization: Rethinking Long-Horizon Decision-Making in Adversarial Poker Environments
Feb 08, 2026Training large language model (LLM) agents for adversarial games is often driven by episodic objectives such as win rate. In long-horizon settings, however, payoffs are shaped by latent strategic externalities that evolve over time, so myopic optimization and variation-based regret analyses can become vacuous even when the dynamics are predictable. To solve this problem, we introduce Implicit Strategic Optimization (ISO), a prediction-aware framework in which each agent forecasts the current strategic context and uses it to update its policy online. ISO combines a Strategic Reward Model (SRM) that estimates the long-run strategic value of actions with iso-grpo, a context-conditioned optimistic learning rule. We prove sublinear contextual regret and equilibrium convergence guarantees whose dominant terms scale with the number of context mispredictions; when prediction errors are bounded, our bounds recover the static-game rates obtained when strategic externalities are known. Experiments in 6-player No-Limit Texas Hold'em and competitive Pokemon show consistent improvements in long-term return over strong LLM and RL baselines, and graceful degradation under controlled prediction noise.
ECHO-2: A Large-Scale Distributed Rollout Framework for Cost-Efficient Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) is a critical stage in post-training large language models (LLMs), involving repeated interaction between rollout generation, reward evaluation, and centralized learning. Distributing rollout execution offers opportunities to leverage more cost-efficient inference resources, but introduces challenges in wide-area coordination and policy dissemination. We present ECHO-2, a distributed RL framework for post-training with remote inference workers and non-negligible dissemination latency. ECHO-2 combines centralized learning with distributed rollouts and treats bounded policy staleness as a user-controlled parameter, enabling rollout generation, dissemination, and training to overlap. We introduce an overlap-based capacity model that relates training time, dissemination latency, and rollout throughput, yielding a practical provisioning rule for sustaining learner utilization. To mitigate dissemination bottlenecks and lower cost, ECHO-2 employs peer-assisted pipelined broadcast and cost-aware activation of heterogeneous workers. Experiments on GRPO post-training of 4B and 8B models under real wide-area bandwidth regimes show that ECHO-2 significantly improves cost efficiency while preserving RL reward comparable to strong baselines.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
SAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
May 28, 2025Leveraging multimodal large models for image segmentation has become a prominent research direction. However, existing approaches typically rely heavily on manually annotated datasets that include explicit reasoning processes, which are costly and time-consuming to produce. Recent advances suggest that reinforcement learning (RL) can endow large models with reasoning capabilities without requiring such reasoning-annotated data. In this paper, we propose SAM-R1, a novel framework that enables multimodal large models to perform fine-grained reasoning in image understanding tasks. Our approach is the first to incorporate fine-grained segmentation settings during the training of multimodal reasoning models. By integrating task-specific, fine-grained rewards with a tailored optimization objective, we further enhance the model's reasoning and segmentation alignment. We also leverage the Segment Anything Model (SAM) as a strong and flexible reward provider to guide the learning process. With only 3k training samples, SAM-R1 achieves strong performance across multiple benchmarks, demonstrating the effectiveness of reinforcement learning in equipping multimodal models with segmentation-oriented reasoning capabilities.
Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
Apr 14, 2025Automating the synthesis of coordinated bimanual piano performances poses significant challenges, particularly in capturing the intricate choreography between the hands while preserving their distinct kinematic signatures. In this paper, we propose a dual-stream neural framework designed to generate synchronized hand gestures for piano playing from audio input, addressing the critical challenge of modeling both hand independence and coordination. Our framework introduces two key innovations: (i) a decoupled diffusion-based generation framework that independently models each hand's motion via dual-noise initialization, sampling distinct latent noise for each while leveraging a shared positional condition, and (ii) a Hand-Coordinated Asymmetric Attention (HCAA) mechanism suppresses symmetric (common-mode) noise to highlight asymmetric hand-specific features, while adaptively enhancing inter-hand coordination during denoising. The system operates hierarchically: it first predicts 3D hand positions from audio features and then generates joint angles through position-aware diffusion models, where parallel denoising streams interact via HCAA. Comprehensive evaluations demonstrate that our framework outperforms existing state-of-the-art methods across multiple metrics.
MetaFold: Language-Guided Multi-Category Garment Folding Framework via Trajectory Generation and Foundation Model
Mar 11, 2025
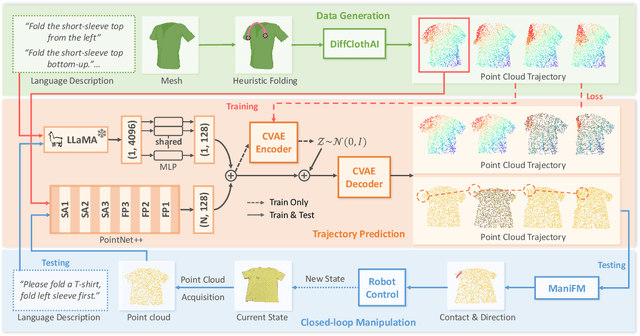

Garment folding is a common yet challenging task in robotic manipulation. The deformability of garments leads to a vast state space and complex dynamics, which complicates precise and fine-grained manipulation. Previous approaches often rely on predefined key points or demonstrations, limiting their generalization across diverse garment categories. This paper presents a framework, MetaFold, that disentangles task planning from action prediction, learning each independently to enhance model generalization. It employs language-guided point cloud trajectory generation for task planning and a low-level foundation model for action prediction. This structure facilitates multi-category learning, enabling the model to adapt flexibly to various user instructions and folding tasks. Experimental results demonstrate the superiority of our proposed framework. Supplementary materials are available on our website: https://meta-fold.github.io/.
Detecting Backdoor Attacks via Similarity in Semantic Communication Systems
Feb 06, 2025Semantic communication systems, which leverage Generative AI (GAI) to transmit semantic meaning rather than raw data, are poised to revolutionize modern communications. However, they are vulnerable to backdoor attacks, a type of poisoning manipulation that embeds malicious triggers into training datasets. As a result, Backdoor attacks mislead the inference for poisoned samples while clean samples remain unaffected. The existing defenses may alter the model structure (such as neuron pruning that potentially degrades inference performance on clean inputs, or impose strict requirements on data formats (such as ``Semantic Shield" that requires image-text pairs). To address these limitations, this work proposes a defense mechanism that leverages semantic similarity to detect backdoor attacks without modifying the model structure or imposing data format constraints. By analyzing deviations in semantic feature space and establishing a threshold-based detection framework, the proposed approach effectively identifies poisoned samples. The experimental results demonstrate high detection accuracy and recall across varying poisoning ratios, underlining the significant effectiveness of our proposed solution.
IDEA: Image Description Enhanced CLIP-Adapter
Jan 15, 2025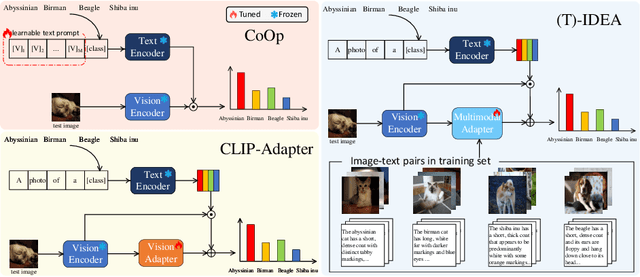
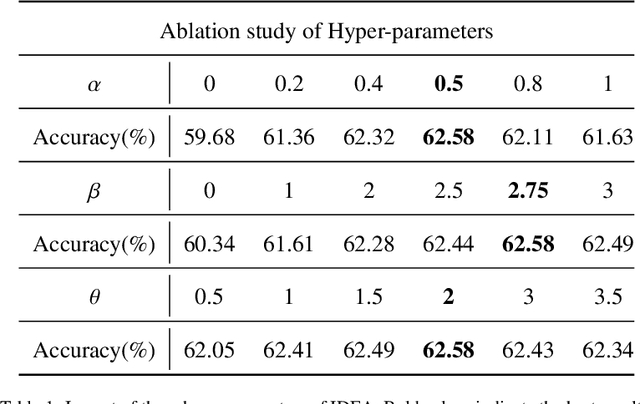
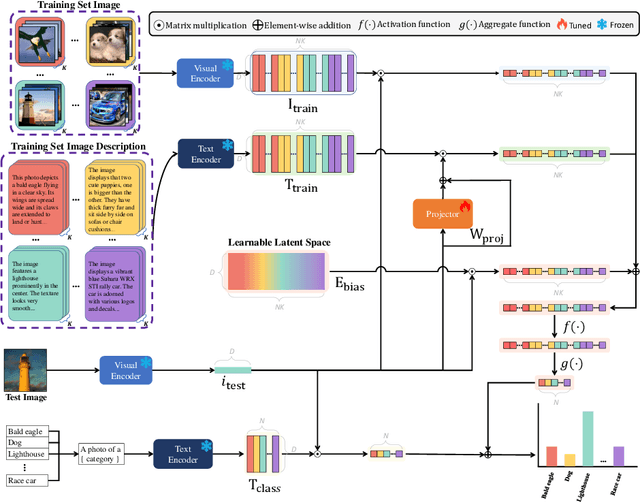

CLIP (Contrastive Language-Image Pre-training) has attained great success in pattern recognition and computer vision. Transferring CLIP to downstream tasks (e.g. zero- or few-shot classification) is a hot topic in multimodal learning. However, current studies primarily focus on either prompt learning for text or adapter tuning for vision, without fully exploiting the complementary information and correlations among image-text pairs. In this paper, we propose an Image Description Enhanced CLIP-Adapter (IDEA) method to adapt CLIP to few-shot image classification tasks. This method captures fine-grained features by leveraging both visual features and textual descriptions of images. IDEA is a training-free method for CLIP, and it can be comparable to or even exceeds state-of-the-art models on multiple tasks. Furthermore, we introduce Trainable-IDEA (T-IDEA), which extends IDEA by adding two lightweight learnable components (i.e., a projector and a learnable latent space), further enhancing the model's performance and achieving SOTA results on 11 datasets. As one important contribution, we employ the Llama model and design a comprehensive pipeline to generate textual descriptions for images of 11 datasets, resulting in a total of 1,637,795 image-text pairs, named "IMD-11". Our code and data are released at https://github.com/FourierAI/IDEA.