 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning as Nonparametric Conditional Probability Estimation: Risk Bounds and Optimality
Aug 12, 2025This paper investigates the expected excess risk of In-Context Learning (ICL) for multiclass classification. We model each task as a sequence of labeled prompt samples and a query input, where a pre-trained model estimates the conditional class probabilities of the query. The expected excess risk is defined as the average truncated Kullback-Leibler (KL) divergence between the predicted and ground-truth conditional class distributions, averaged over a specified family of tasks. We establish a new oracle inequality for the expected excess risk based on KL divergence in multiclass classification. This allows us to derive tight upper and lower bounds for the expected excess risk in transformer-based models, demonstrating that the ICL estimator achieves the minimax optimal rate - up to a logarithmic factor - for conditional probability estimation. From a technical standpoint, our results introduce a novel method for controlling generalization error using the uniform empirical covering entropy of the log-likelihood function class. Furthermore, we show that multilayer perceptrons (MLPs) can also perform ICL and achieve this optimal rate under specific assumptions, suggesting that transformers may not be the exclusive architecture capable of effective ICL.
DSDE: Using Proportion Estimation to Improve Model Selection for Out-of-Distribution Detection
Nov 03, 2024
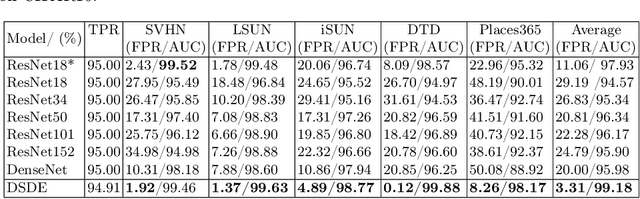

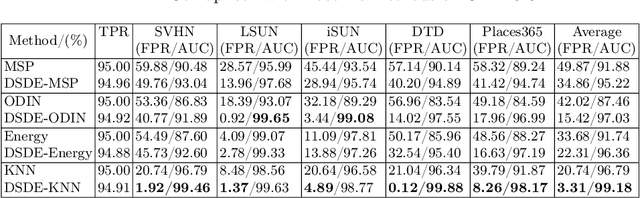
Model library is an effective tool for improving the performance of single-model Out-of-Distribution (OoD) detector, mainly through model selection and detector fusion. However, existing methods in the literature do not provide uncertainty quantification for model selection results. Additionally, the model ensemble process primarily focuses on controlling the True Positive Rate (TPR) while neglecting the False Positive Rate (FPR). In this paper, we emphasize the significance of the proportion of models in the library that identify the test sample as an OoD sample. This proportion holds crucial information and directly influences the error rate of OoD detection.To address this, we propose inverting the commonly-used sequential p-value strategies. We define the rejection region initially and then estimate the error rate. Furthermore, we introduce a novel perspective from change-point detection and propose an approach for proportion estimation with automatic hyperparameter selection. We name the proposed approach as DOS-Storey-based Detector Ensemble (DSDE). Experimental results on CIFAR10 and CIFAR100 demonstrate the effectiveness of our approach in tackling OoD detection challenges. Specifically, the CIFAR10 experiments show that DSDE reduces the FPR from 11.07% to 3.31% compared to the top-performing single-model detector.
Enhancing Out-of-Distribution Detection with Multitesting-based Layer-wise Feature Fusion
Mar 16, 2024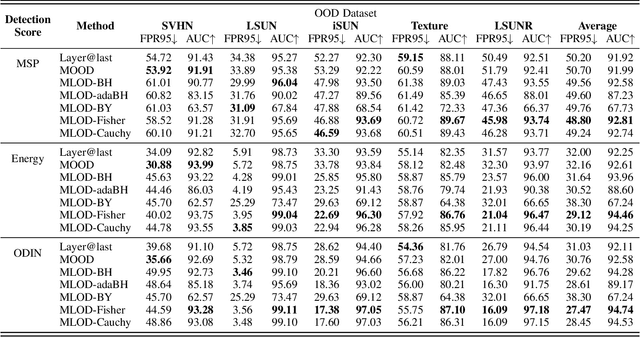
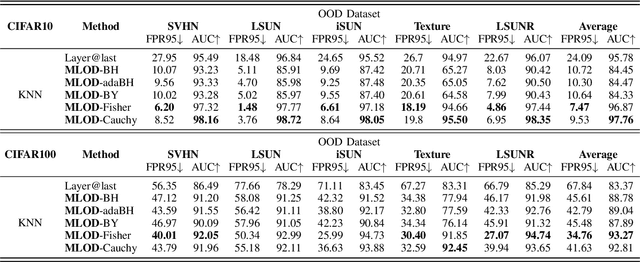
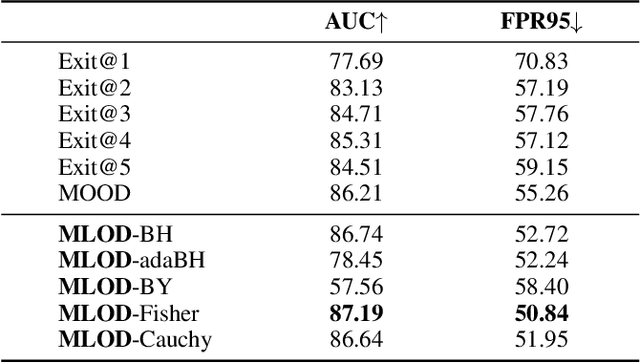
Deploying machine learning in open environments presents the challenge of encountering diverse test inputs that differ significantly from the training data. These out-of-distribution samples may exhibit shifts in local or global features compared to the training distribution. The machine learning (ML) community has responded with a number of methods aimed at distinguishing anomalous inputs from original training data. However, the majority of previous studies have primarily focused on the output layer or penultimate layer of pre-trained deep neural networks. In this paper, we propose a novel framework, Multitesting-based Layer-wise Out-of-Distribution (OOD) Detection (MLOD), to identify distributional shifts in test samples at different levels of features through rigorous multiple testing procedure. Our approach distinguishes itself from existing methods as it does not require modifying the structure or fine-tuning of the pre-trained classifier. Through extensive experiments, we demonstrate that our proposed framework can seamlessly integrate with any existing distance-based inspection method while efficiently utilizing feature extractors of varying depths. Our scheme effectively enhances the performance of out-of-distribution detection when compared to baseline methods. In particular, MLOD-Fisher achieves superior performance in general. When trained using KNN on CIFAR10, MLOD-Fisher significantly lowers the false positive rate (FPR) from 24.09% to 7.47% on average compared to merely utilizing the features of the last layer.
Boosting Out-of-Distribution Detection with Multiple Pre-trained Models
Dec 24, 2022



Out-of-Distribution (OOD) detection, i.e., identifying whether an input is sampled from a novel distribution other than the training distribution, is a critical task for safely deploying machine learning systems in the open world. Recently, post hoc detection utilizing pre-trained models has shown promising performance and can be scaled to large-scale problems. This advance raises a natural question: Can we leverage the diversity of multiple pre-trained models to improve the performance of post hoc detection methods? In this work, we propose a detection enhancement method by ensembling multiple detection decisions derived from a zoo of pre-trained models. Our approach uses the p-value instead of the commonly used hard threshold and leverages a fundamental framework of multiple hypothesis testing to control the true positive rate of In-Distribution (ID) data. We focus on the usage of model zoos and provide systematic empirical comparisons with current state-of-the-art methods on various OOD detection benchmarks. The proposed ensemble scheme shows consistent improvement compared to single-model detectors and significantly outperforms the current competitive methods. Our method substantially improves the relative performance by 65.40% and 26.96% on the CIFAR10 and ImageNet benchmarks.