 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
SJD++: Improved Speculative Jacobi Decoding for Training-free Acceleration of Discrete Auto-regressive Text-to-Image Generation
Dec 08, 2025Large autoregressive models can generate high-quality, high-resolution images but suffer from slow generation speed, because these models require hundreds to thousands of sequential forward passes for next-token prediction during inference. To accelerate autoregressive text-to-image generation, we propose Speculative Jacobi Decoding++ (SJD++), a training-free probabilistic parallel decoding algorithm. Unlike traditional next-token prediction, SJD++ performs multi-token prediction in each forward pass, drastically reducing generation steps. Specifically, it integrates the iterative multi-token prediction mechanism from Jacobi decoding, with the probabilistic drafting-and-verification mechanism from speculative sampling. More importantly, for further acceleration, SJD++ reuses high-confidence draft tokens after each verification phase instead of resampling them all. We conduct extensive experiments on several representative autoregressive text-to-image generation models and demonstrate that SJD++ achieves $2\times$ to $3\times$ inference latency reduction and $2\times$ to $7\times$ step compression, while preserving visual quality with no observable degradation.
Masked Diffusion Models as Energy Minimization
Sep 17, 2025
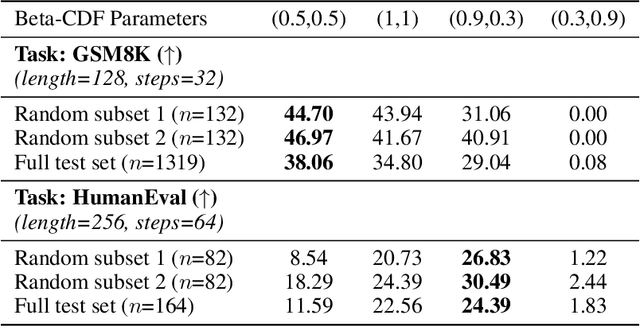
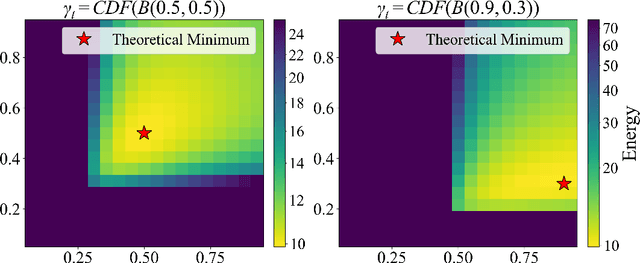
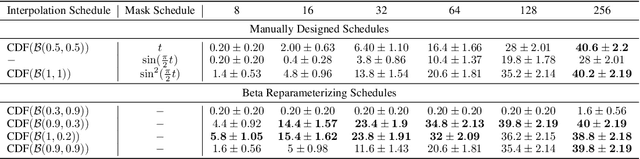
We present a systematic theoretical framework that interprets masked diffusion models (MDMs) as solutions to energy minimization problems in discrete optimal transport. Specifically, we prove that three distinct energy formulations--kinetic, conditional kinetic, and geodesic energy--are mathematically equivalent under the structure of MDMs, and that MDMs minimize all three when the mask schedule satisfies a closed-form optimality condition. This unification not only clarifies the theoretical foundations of MDMs, but also motivates practical improvements in sampling. By parameterizing interpolation schedules via Beta distributions, we reduce the schedule design space to a tractable 2D search, enabling efficient post-training tuning without model modification. Experiments on synthetic and real-world benchmarks demonstrate that our energy-inspired schedules outperform hand-crafted baselines, particularly in low-step sampling settings.
MESH -- Understanding Videos Like Human: Measuring Hallucinations in Large Video Models
Sep 10, 2025Large Video Models (LVMs) build on the semantic capabilities of Large Language Models (LLMs) and vision modules by integrating temporal information to better understand dynamic video content. Despite their progress, LVMs are prone to hallucinations-producing inaccurate or irrelevant descriptions. Current benchmarks for video hallucination depend heavily on manual categorization of video content, neglecting the perception-based processes through which humans naturally interpret videos. We introduce MESH, a benchmark designed to evaluate hallucinations in LVMs systematically. MESH uses a Question-Answering framework with binary and multi-choice formats incorporating target and trap instances. It follows a bottom-up approach, evaluating basic objects, coarse-to-fine subject features, and subject-action pairs, aligning with human video understanding. We demonstrate that MESH offers an effective and comprehensive approach for identifying hallucinations in videos. Our evaluations show that while LVMs excel at recognizing basic objects and features, their susceptibility to hallucinations increases markedly when handling fine details or aligning multiple actions involving various subjects in longer videos.
Mathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
Perceptual Decoupling for Scalable Multi-modal Reasoning via Reward-Optimized Captioning
Jun 05, 2025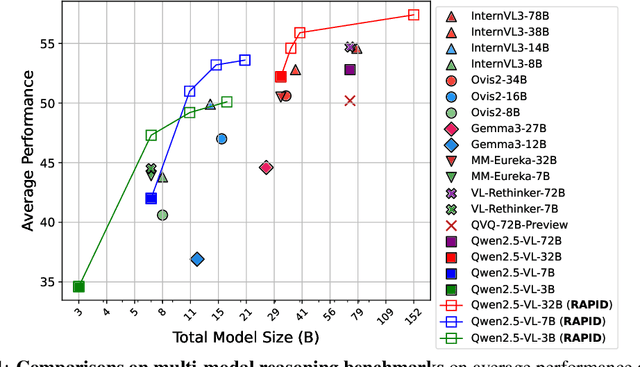
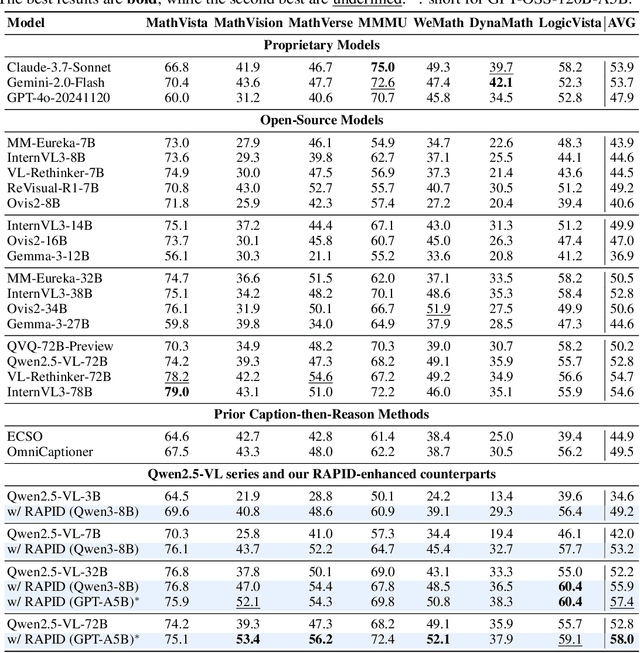
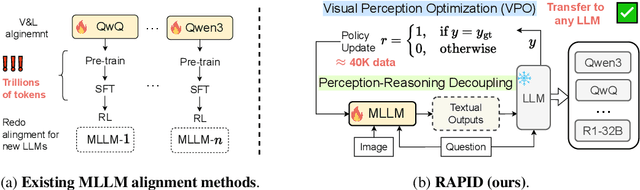
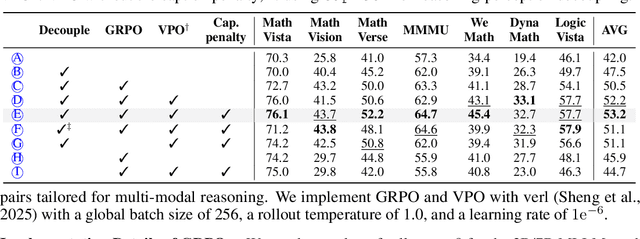
Recent advances in slow-thinking language models (e.g., OpenAI-o1 and DeepSeek-R1) have demonstrated remarkable abilities in complex reasoning tasks by emulating human-like reflective cognition. However, extending such capabilities to multi-modal large language models (MLLMs) remains challenging due to the high cost of retraining vision-language alignments when upgrading the underlying reasoner LLMs. A straightforward solution is to decouple perception from reasoning, i.e., converting visual inputs into language representations (e.g., captions) that are then passed to a powerful text-only reasoner. However, this decoupling introduces a critical challenge: the visual extractor must generate descriptions that are both faithful to the image and informative enough to support accurate downstream reasoning. To address this, we propose Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization (RACRO) - a reasoning-guided reinforcement learning strategy that aligns the extractor's captioning behavior with the reasoning objective. By closing the perception-reasoning loop via reward-based optimization, RACRO significantly enhances visual grounding and extracts reasoning-optimized representations. Experiments on multi-modal math and science benchmarks show that the proposed RACRO method achieves state-of-the-art average performance while enabling superior scalability and plug-and-play adaptation to more advanced reasoning LLMs without the necessity for costly multi-modal re-alignment.
FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
May 26, 2025The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify visual understanding and image generation within a single framework. However, most existing MLLMs rely on autoregressive (AR) architectures, which impose inherent limitations on future development, such as the raster-scan order in image generation and restricted reasoning abilities in causal context modeling. In this work, we challenge the dominance of AR-based approaches by introducing FUDOKI, a unified multimodal model purely based on discrete flow matching, as an alternative to conventional AR paradigms. By leveraging metric-induced probability paths with kinetic optimal velocities, our framework goes beyond the previous masking-based corruption process, enabling iterative refinement with self-correction capability and richer bidirectional context integration during generation. To mitigate the high cost of training from scratch, we initialize FUDOKI from pre-trained AR-based MLLMs and adaptively transition to the discrete flow matching paradigm. Experimental results show that FUDOKI achieves performance comparable to state-of-the-art AR-based MLLMs across both visual understanding and image generation tasks, highlighting its potential as a foundation for next-generation unified multimodal models. Furthermore, we show that applying test-time scaling techniques to FUDOKI yields significant performance gains, further underscoring its promise for future enhancement through reinforcement learning.
Variational Autoencoding Discrete Diffusion with Enhanced Dimensional Correlations Modeling
May 23, 2025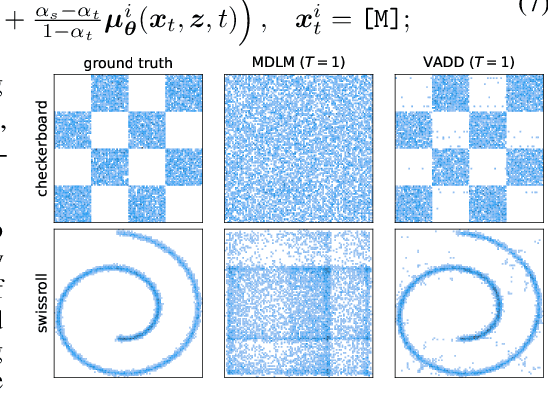
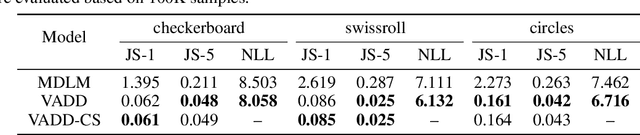
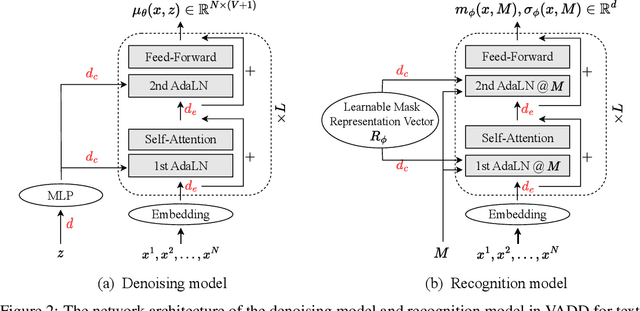

Discrete diffusion models have recently shown great promise for modeling complex discrete data, with masked diffusion models (MDMs) offering a compelling trade-off between quality and generation speed. MDMs denoise by progressively unmasking multiple dimensions from an all-masked input, but their performance can degrade when using few denoising steps due to limited modeling of inter-dimensional dependencies. In this paper, we propose Variational Autoencoding Discrete Diffusion (VADD), a novel framework that enhances discrete diffusion with latent variable modeling to implicitly capture correlations among dimensions. By introducing an auxiliary recognition model, VADD enables stable training via variational lower bounds maximization and amortized inference over the training set. Our approach retains the efficiency of traditional MDMs while significantly improving sample quality, especially when the number of denoising steps is small. Empirical results on 2D toy data, pixel-level image generation, and text generation demonstrate that VADD consistently outperforms MDM baselines.
Adding Additional Control to One-Step Diffusion with Joint Distribution Matching
Mar 09, 2025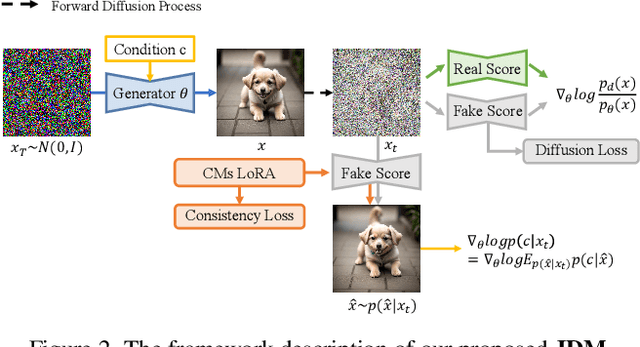
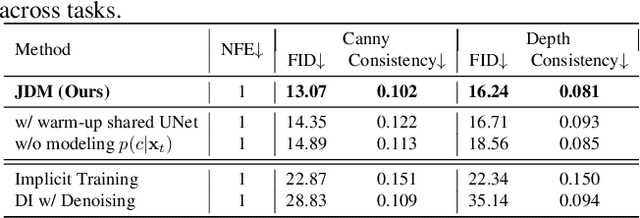

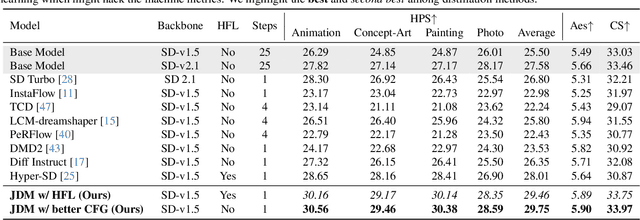
While diffusion distillation has enabled one-step generation through methods like Variational Score Distillation, adapting distilled models to emerging new controls -- such as novel structural constraints or latest user preferences -- remains challenging. Conventional approaches typically requires modifying the base diffusion model and redistilling it -- a process that is both computationally intensive and time-consuming. To address these challenges, we introduce Joint Distribution Matching (JDM), a novel approach that minimizes the reverse KL divergence between image-condition joint distributions. By deriving a tractable upper bound, JDM decouples fidelity learning from condition learning. This asymmetric distillation scheme enables our one-step student to handle controls unknown to the teacher model and facilitates improved classifier-free guidance (CFG) usage and seamless integration of human feedback learning (HFL). Experimental results demonstrate that JDM surpasses baseline methods such as multi-step ControlNet by mere one-step in most cases, while achieving state-of-the-art performance in one-step text-to-image synthesis through improved usage of CFG or HFL integration.
Empowering Sparse-Input Neural Radiance Fields with Dual-Level Semantic Guidance from Dense Novel Views
Mar 04, 2025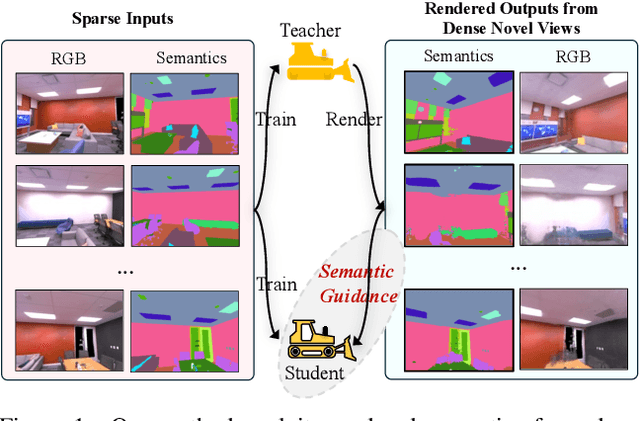

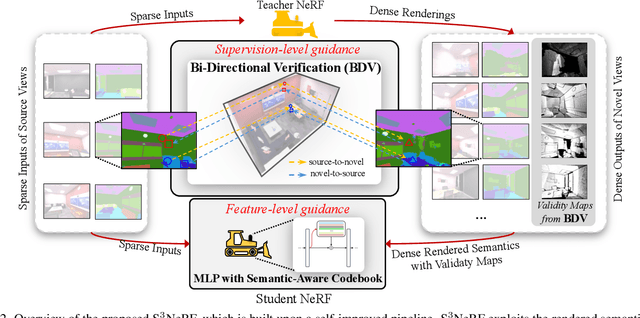

Neural Radiance Fields (NeRF) have shown remarkable capabilities for photorealistic novel view synthesis. One major deficiency of NeRF is that dense inputs are typically required, and the rendering quality will drop drastically given sparse inputs. In this paper, we highlight the effectiveness of rendered semantics from dense novel views, and show that rendered semantics can be treated as a more robust form of augmented data than rendered RGB. Our method enhances NeRF's performance by incorporating guidance derived from the rendered semantics. The rendered semantic guidance encompasses two levels: the supervision level and the feature level. The supervision-level guidance incorporates a bi-directional verification module that decides the validity of each rendered semantic label, while the feature-level guidance integrates a learnable codebook that encodes semantic-aware information, which is queried by each point via the attention mechanism to obtain semantic-relevant predictions. The overall semantic guidance is embedded into a self-improved pipeline. We also introduce a more challenging sparse-input indoor benchmark, where the number of inputs is limited to as few as 6. Experiments demonstrate the effectiveness of our method and it exhibits superior performance compared to existing approaches.