 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
Using Language Models For Knowledge Acquisition in Natural Language Reasoning Problems
Apr 04, 2023For a natural language problem that requires some non-trivial reasoning to solve, there are at least two ways to do it using a large language model (LLM). One is to ask it to solve it directly. The other is to use it to extract the facts from the problem text and then use a theorem prover to solve it. In this note, we compare the two methods using ChatGPT and GPT4 on a series of logic word puzzles, and conclude that the latter is the right approach.
XRJL-HKUST at SemEval-2021 Task 4: WordNet-Enhanced Dual Multi-head Co-Attention for Reading Comprehension of Abstract Meaning
Mar 30, 2021
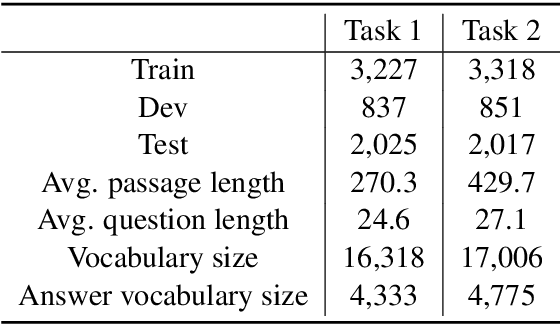
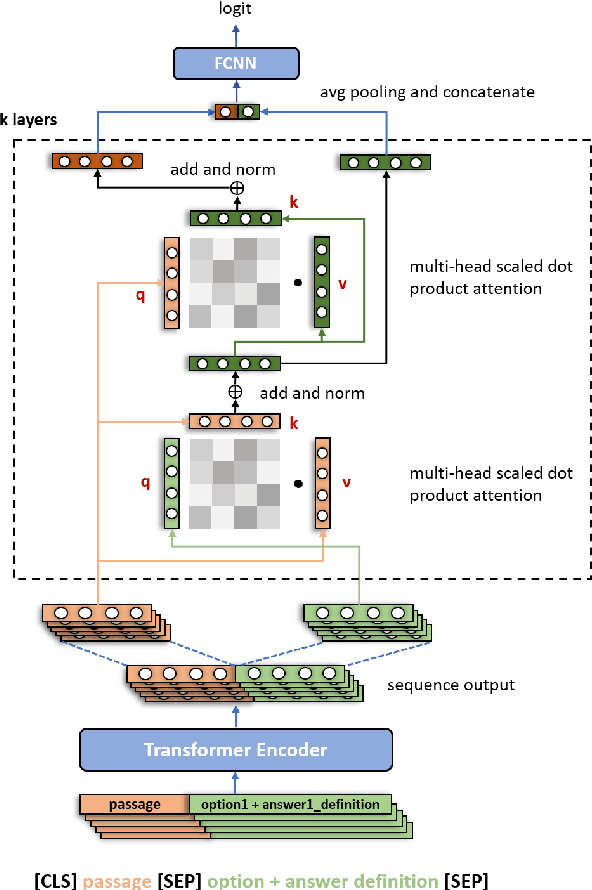

This paper presents our submitted system to SemEval 2021 Task 4: Reading Comprehension of Abstract Meaning. Our system uses a large pre-trained language model as the encoder and an additional dual multi-head co-attention layer to strengthen the relationship between passages and question-answer pairs, following the current state-of-the-art model DUMA. The main difference is that we stack the passage-question and question-passage attention modules instead of calculating parallelly to simulate re-considering process. We also add a layer normalization module to improve the performance of our model. Furthermore, to incorporate our known knowledge about abstract concepts, we retrieve the definitions of candidate answers from WordNet and feed them to the model as extra inputs. Our system, called WordNet-enhanced DUal Multi-head Co-Attention (WN-DUMA), achieves 86.67% and 89.99% accuracy on the official blind test set of subtask 1 and subtask 2 respectively.