 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarve to Perceive: Taming Lazy Perception in VLMs with Constrained Visual Bandwidth
May 18, 2026Vision-Language Models (VLMs) deployed as situated agents in high-resolution visual environments require active perception -- the ability to dynamically decide where to look through operations like zooming, cropping, and panning. However, current training paradigms produce models that mimic the surface form of such operations without functionally depending on their outputs, a phenomenon we term lazy perception. We trace this to a fundamental learning asymmetry: when coarse global views combined with language priors suffice for moderate accuracy, the model has no incentive to learn harder multi-step visual search. If a model can succeed without actively looking, it will never learn to look. This motivates Starve to Perceive, a training paradigm that constrains visual bandwidth -- restricting each observation to a tight token budget so that no single view suffices for task completion, making active perception the only viable strategy. Despite requiring no auxiliary losses, reward shaping, or architectural changes -- serving as a minimal, plug-in modification to standard post-training pipelines -- models trained under perceptual starvation achieve substantial gains of 5% average relative improvement across diverse benchmarks.
Bad Seeing or Bad Thinking? Rewarding Perception for Vision-Language Reasoning
May 13, 2026Achieving robust perception-reasoning synergy is a central goal for advanced Vision-Language Models (VLMs). Recent advancements have pursued this goal via architectural designs or agentic workflows. However, these approaches are often limited by static textual reasoning or complicated by the significant compute and engineering burden of external agentic complexity. Worse, this heavy investment does not yield proportional gains, often witnessing a "seesaw effect" on perception and reasoning. This motivates a fundamental rethinking of the true bottleneck. In this paper, we argue that the root cause of this trade-off is an ambiguity in modality credit assignment: when a VLM fails, is it due to flawed perception ("bad seeing") or flawed logic ("bad thinking")? To resolve this, we introduce a reinforcement learning framework that improves perception-reasoning synergy by reliably rewarding the perception fidelity. We explicitly decompose the generation process into interleaved perception and reasoning steps. This decoupling enables targeted supervision on perception. Crucially, we introduce Perception Verification (PV), leveraging a "blindfolded reasoning" proxy to reward perceptual fidelity independently of reasoning outcomes. Furthermore, to scale training across free-form VL tasks, we propose Structured Verbal Verification, which replaces high-variance LLM judging with structured algorithmic execution. These techniques are integrated into a Modality-Aware Credit Assignment (MoCA) mechanism, which routes rewards to the specific source of error -- either bad seeing or bad thinking -- enabling a single VLM to achieve simultaneous performance gains across a wide task spectrum.
RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
Apr 14, 2026Most reward models for visual generation reduce rich human judgments to a single unexplained score, discarding the reasoning that underlies preference. We show that teaching reward models to produce explicit, multi-dimensional critiques before scoring transforms them from passive evaluators into active optimization tools, improving generators in two complementary ways: at training time, structured rationales provide interpretable, fine-grained rewards for reinforcement learning; at test time, a Generate-Critique-Refine loop turns critiques into targeted prompt revisions that improve outputs without any parameter updates. To train such a reward model without costly rationale annotations, we introduce Preference-Anchored Rationalization (PARROT), a principled framework that recovers high-quality rationales from readily available preference data through anchored generation, consistency filtering, and distillation. The resulting model, RationalRewards (8B), achieves state-of-the-art preference prediction among open-source reward models, competitive with Gemini-2.5-Pro, while using 10-20x less training data than comparable baselines. As an RL reward, it consistently improves text-to-image and image-editing generators beyond scalar alternatives. Most strikingly, its test-time critique-and-refine loop matches or exceeds RL-based fine-tuning on several benchmarks, suggesting that structured reasoning can unlock latent capabilities in existing generators that suboptimal prompts fail to elicit.
ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
Feb 03, 2026While passive agents merely follow instructions, proactive agents align with higher-level objectives, such as assistance and safety by continuously monitoring the environment to determine when and how to act. However, developing proactive agents is hindered by the lack of specialized resources. To address this, we introduce ProAct-75, a benchmark designed to train and evaluate proactive agents across diverse domains, including assistance, maintenance, and safety monitoring. Spanning 75 tasks, our dataset features 91,581 step-level annotations enriched with explicit task graphs. These graphs encode step dependencies and parallel execution possibilities, providing the structural grounding necessary for complex decision-making. Building on this benchmark, we propose ProAct-Helper, a reference baseline powered by a Multimodal Large Language Model (MLLM) that grounds decision-making in state detection, and leveraging task graphs to enable entropy-driven heuristic search for action selection, allowing agents to execute parallel threads independently rather than mirroring the human's next step. Extensive experiments demonstrate that ProAct-Helper outperforms strong closed-source models, improving trigger detection mF1 by 6.21%, saving 0.25 more steps in online one-step decision, and increasing the rate of parallel actions by 15.58%.
CogDoc: Towards Unified thinking in Documents
Dec 14, 2025Current document reasoning paradigms are constrained by a fundamental trade-off between scalability (processing long-context documents) and fidelity (capturing fine-grained, multimodal details). To bridge this gap, we propose CogDoc, a unified coarse-to-fine thinking framework that mimics human cognitive processes: a low-resolution "Fast Reading" phase for scalable information localization,followed by a high-resolution "Focused Thinking" phase for deep reasoning. We conduct a rigorous investigation into post-training strategies for the unified thinking framework, demonstrating that a Direct Reinforcement Learning (RL) approach outperforms RL with Supervised Fine-Tuning (SFT) initialization. Specifically, we find that direct RL avoids the "policy conflict" observed in SFT. Empirically, our 7B model achieves state-of-the-art performance within its parameter class, notably surpassing significantly larger proprietary models (e.g., GPT-4o) on challenging, visually rich document benchmarks.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025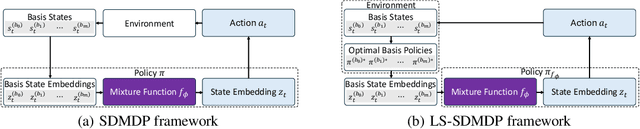
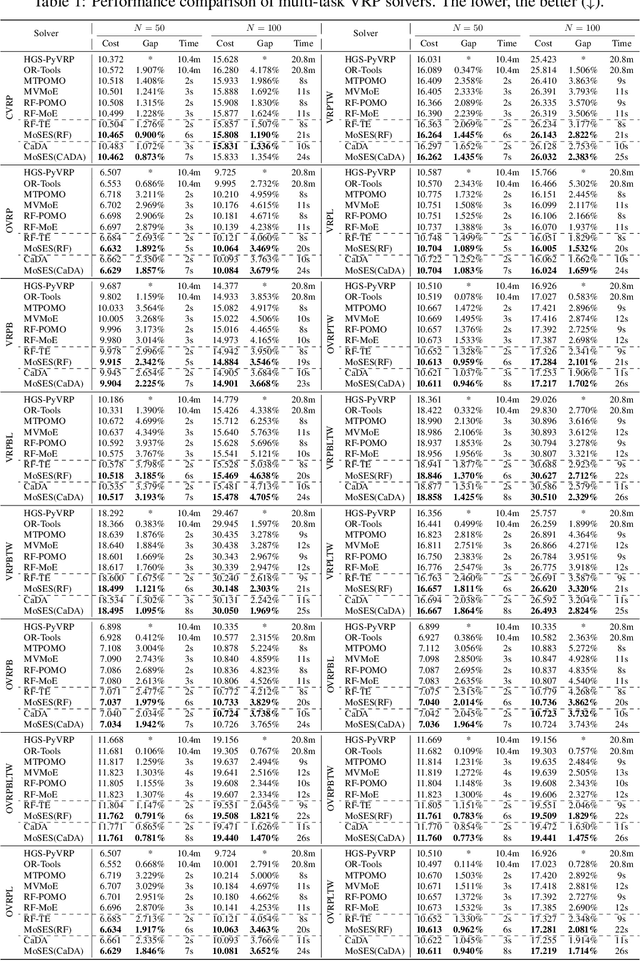
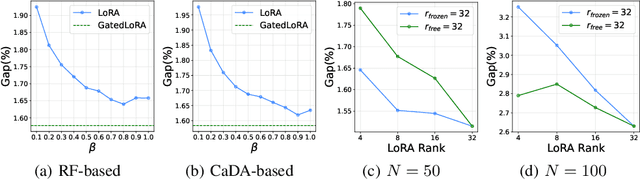
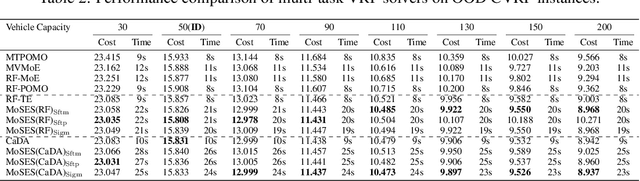
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Sep 03, 2025



Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like ``aha moments", ``length-scaling'' and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose HIerarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. HICRA significantly outperforms strong baselines, demonstrating that focusing on this strategic bottleneck is key to unlocking advanced reasoning. Furthermore, we validate semantic entropy as a superior compass for measuring strategic exploration over misleading metrics such as token-level entropy.
Beyond Distillation: Pushing the Limits of Medical LLM Reasoning with Minimalist Rule-Based RL
May 23, 2025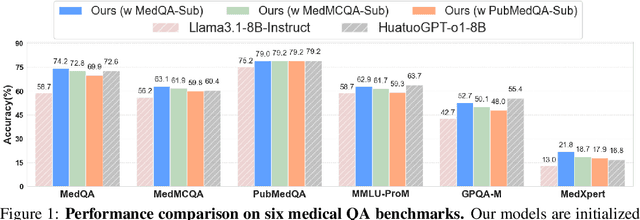
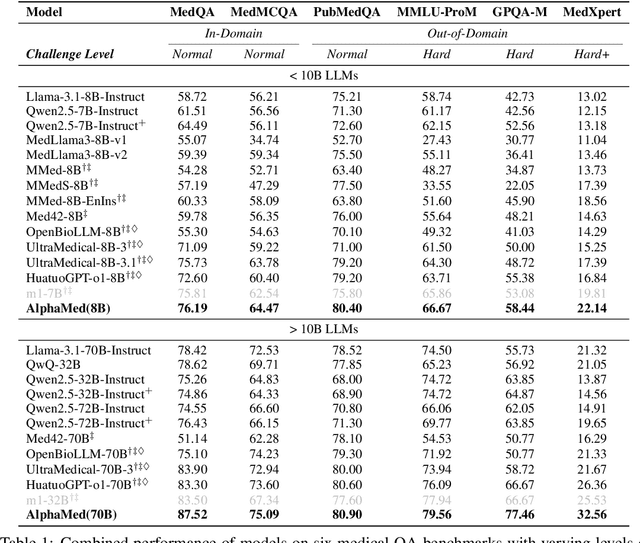
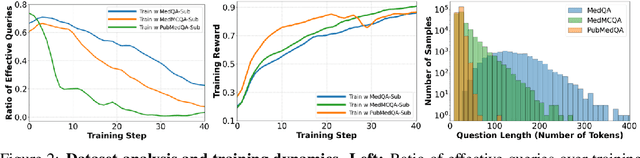

Improving performance on complex tasks and enabling interpretable decision making in large language models (LLMs), especially for clinical applications, requires effective reasoning. Yet this remains challenging without supervised fine-tuning (SFT) on costly chain-of-thought (CoT) data distilled from closed-source models (e.g., GPT-4o). In this work, we present AlphaMed, the first medical LLM to show that reasoning capability can emerge purely through reinforcement learning (RL), using minimalist rule-based rewards on public multiple-choice QA datasets, without relying on SFT or distilled CoT data. AlphaMed achieves state-of-the-art results on six medical QA benchmarks, outperforming models trained with conventional SFT+RL pipelines. On challenging benchmarks (e.g., MedXpert), AlphaMed even surpasses larger or closed-source models such as DeepSeek-V3-671B and Claude-3.5-Sonnet. To understand the factors behind this success, we conduct a comprehensive data-centric analysis guided by three questions: (i) Can minimalist rule-based RL incentivize reasoning without distilled CoT supervision? (ii) How do dataset quantity and diversity impact reasoning? (iii) How does question difficulty shape the emergence and generalization of reasoning? Our findings show that dataset informativeness is a key driver of reasoning performance, and that minimalist RL on informative, multiple-choice QA data is effective at inducing reasoning without CoT supervision. We also observe divergent trends across benchmarks, underscoring limitations in current evaluation and the need for more challenging, reasoning-oriented medical QA benchmarks.
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
May 21, 2025



Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model's initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84\% on V* bench, 74\% on TallyQA-Complex, and 84\% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Apr 10, 2025Recently, slow-thinking systems like GPT-o1 and DeepSeek-R1 have demonstrated great potential in solving challenging problems through explicit reflection. They significantly outperform the best fast-thinking models, such as GPT-4o, on various math and science benchmarks. However, their multimodal reasoning capabilities remain on par with fast-thinking models. For instance, GPT-o1's performance on benchmarks like MathVista, MathVerse, and MathVision is similar to fast-thinking models. In this paper, we aim to enhance the slow-thinking capabilities of vision-language models using reinforcement learning (without relying on distillation) to advance the state of the art. First, we adapt the GRPO algorithm with a novel technique called Selective Sample Replay (SSR) to address the vanishing advantages problem. While this approach yields strong performance, the resulting RL-trained models exhibit limited self-reflection or self-verification. To further encourage slow-thinking, we introduce Forced Rethinking, which appends a textual rethinking trigger to the end of initial rollouts in RL training, explicitly enforcing a self-reflection reasoning step. By combining these two techniques, our model, VL-Rethinker, advances state-of-the-art scores on MathVista, MathVerse, and MathVision to achieve 80.3%, 61.8%, and 43.9% respectively. VL-Rethinker also achieves open-source SoTA on multi-disciplinary benchmarks such as MMMU-Pro, EMMA, and MEGA-Bench, narrowing the gap with GPT-o1.