 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Combined Problem of Online Task Assignment and Lifelong Path Finding in Logistics Warehouses: A Case Study
Feb 11, 2025



We study the combined problem of online task assignment and lifelong path finding, which is crucial for the logistics industries. However, most literature either (1) focuses on lifelong path finding assuming a given task assigner, or (2) studies the offline version of this problem where tasks are known in advance. We argue that, to maximize the system throughput, the online version that integrates these two components should be tackled directly. To this end, we introduce a formal framework of the combined problem and its solution concept. Then, we design a rule-based lifelong planner under a practical robot model that works well even in environments with severe local congestion. Upon that, we automate the search for the task assigner with respect to the underlying path planner. Simulation experiments conducted in warehouse scenarios at \textit{Meituan}, one of the largest shopping platforms in China, demonstrate that (a)~\textit{in terms of time efficiency}, our system requires only 83.77\% of the execution time needed for the currently deployed system at Meituan, outperforming other SOTA algorithms by 8.09\%; (b)~\textit{in terms of economic efficiency}, ours can achieve the same throughput with only 60\% of the agents currently in use.
Qwen2.5-1M Technical Report
Jan 26, 2025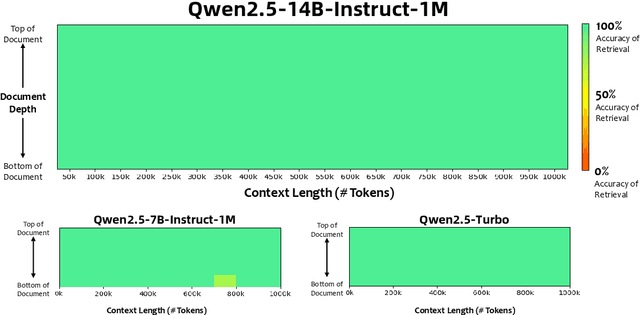

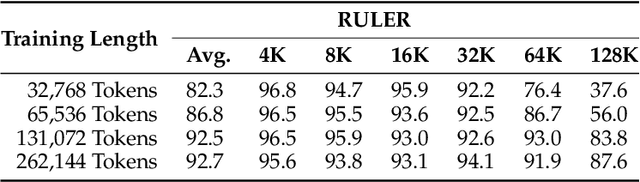
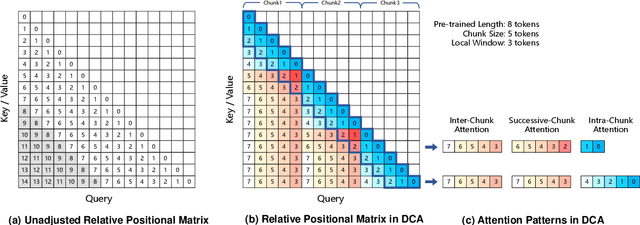
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Echoes in AI: Quantifying Lack of Plot Diversity in LLM Outputs
Dec 31, 2024With rapid advances in large language models (LLMs), there has been an increasing application of LLMs in creative content ideation and generation. A critical question emerges: can current LLMs provide ideas that are diverse enough to truly bolster the collective creativity? We examine two state-of-the-art LLMs, GPT-4 and LLaMA-3, on story generation and discover that LLM-generated stories often consist of plot elements that are echoed across a number of generations. To quantify this phenomenon, we introduce the Sui Generis score, which estimates how unlikely a plot element is to appear in alternative storylines generated by the same LLM. Evaluating on 100 short stories, we find that LLM-generated stories often contain combinations of idiosyncratic plot elements echoed frequently across generations, while the original human-written stories are rarely recreated or even echoed in pieces. Moreover, our human evaluation shows that the ranking of Sui Generis scores among story segments correlates moderately with human judgment of surprise level, even though score computation is completely automatic without relying on human judgment.
Game Plot Design with an LLM-powered Assistant: An Empirical Study with Game Designers
Nov 05, 2024We introduce GamePlot, an LLM-powered assistant that supports game designers in crafting immersive narratives for turn-based games, and allows them to test these games through a collaborative game play and refine the plot throughout the process. Our user study with 14 game designers shows high levels of both satisfaction with the generated game plots and sense of ownership over the narratives, but also reconfirms that LLM are limited in their ability to generate complex and truly innovative content. We also show that diverse user populations have different expectations from AI assistants, and encourage researchers to study how tailoring assistants to diverse user groups could potentially lead to increased job satisfaction and greater creativity and innovation over time.
fPLSA: Learning Semantic Structures in Document Collections Using Foundation Models
Oct 07, 2024



Humans have the ability to learn new tasks by inferring high-level concepts from existing solution, then manipulating these concepts in lieu of the raw data. Can we automate this process by deriving latent semantic structures in a document collection using foundation models? We introduce fPLSA, a foundation-model-based Probabilistic Latent Semantic Analysis (PLSA) method that iteratively clusters and tags document segments based on document-level contexts. These tags can be used to model the structure of given documents and for hierarchical sampling of new texts. Our experiments on story writing, math, and multi-step reasoning datasets demonstrate that fPLSA tags help reconstruct the original texts better than existing tagging methods. Moreover, when used for hierarchical sampling, fPLSA produces more diverse outputs with a higher likelihood of hitting the correct answer than direct sampling and hierarchical sampling with existing tagging methods.
Collaborative Quest Completion with LLM-driven Non-Player Characters in Minecraft
Jul 03, 2024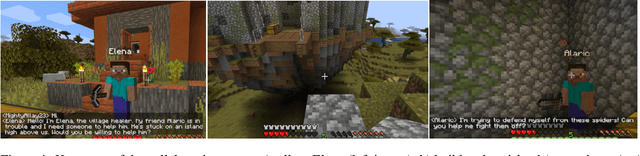


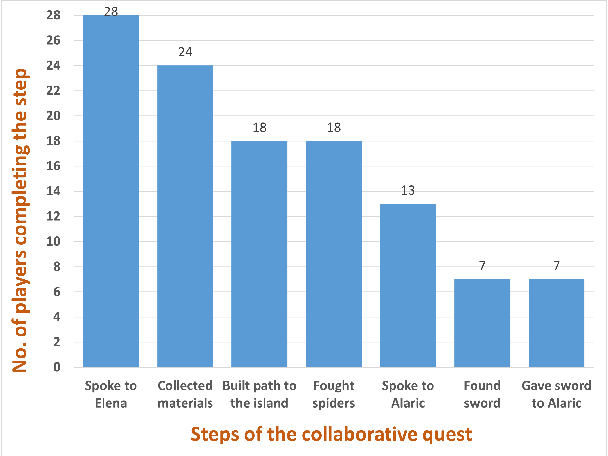
The use of generative AI in video game development is on the rise, and as the conversational and other capabilities of large language models continue to improve, we expect LLM-driven non-player characters (NPCs) to become widely deployed. In this paper, we seek to understand how human players collaborate with LLM-driven NPCs to accomplish in-game goals. We design a minigame within Minecraft where a player works with two GPT4-driven NPCs to complete a quest. We perform a user study in which 28 Minecraft players play this minigame and share their feedback. On analyzing the game logs and recordings, we find that several patterns of collaborative behavior emerge from the NPCs and the human players. We also report on the current limitations of language-only models that do not have rich game-state or visual understanding. We believe that this preliminary study and analysis will inform future game developers on how to better exploit these rapidly improving generative AI models for collaborative roles in games.
* Accepted at Wordplay workshop at ACL 2024
Player-Driven Emergence in LLM-Driven Game Narrative
Apr 25, 2024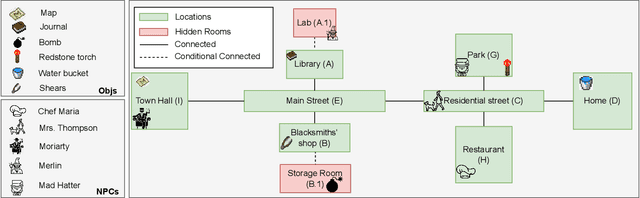
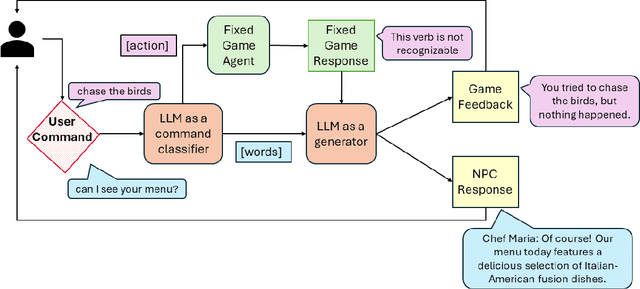
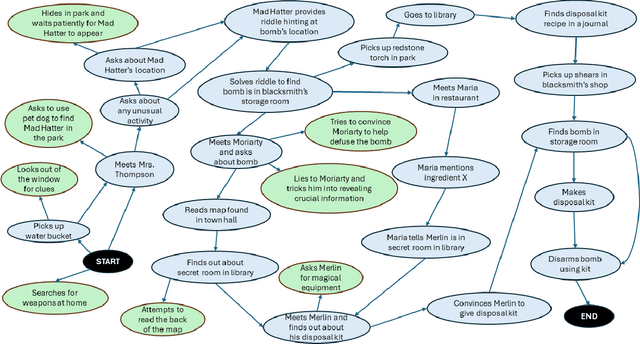

We explore how interaction with large language models (LLMs) can give rise to emergent behaviors, empowering players to participate in the evolution of game narratives. Our testbed is a text-adventure game in which players attempt to solve a mystery under a fixed narrative premise, but can freely interact with non-player characters generated by GPT-4, a large language model. We recruit 28 gamers to play the game and use GPT-4 to automatically convert the game logs into a node-graph representing the narrative in the player's gameplay. We find that through their interactions with the non-deterministic behavior of the LLM, players are able to discover interesting new emergent nodes that were not a part of the original narrative but have potential for being fun and engaging. Players that created the most emergent nodes tended to be those that often enjoy games that facilitate discovery, exploration and experimentation.
GRIM: GRaph-based Interactive narrative visualization for gaMes
Nov 15, 2023Dialogue-based Role Playing Games (RPGs) require powerful storytelling. The narratives of these may take years to write and typically involve a large creative team. In this work, we demonstrate the potential of large generative text models to assist this process. \textbf{GRIM}, a prototype \textbf{GR}aph-based \textbf{I}nteractive narrative visualization system for ga\textbf{M}es, generates a rich narrative graph with branching storylines that match a high-level narrative description and constraints provided by the designer. Game designers can interactively edit the graph by automatically generating new sub-graphs that fit the edits within the original narrative and constraints. We illustrate the use of \textbf{GRIM} in conjunction with GPT-4, generating branching narratives for four well-known stories with different contextual constraints.
Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling
May 17, 2023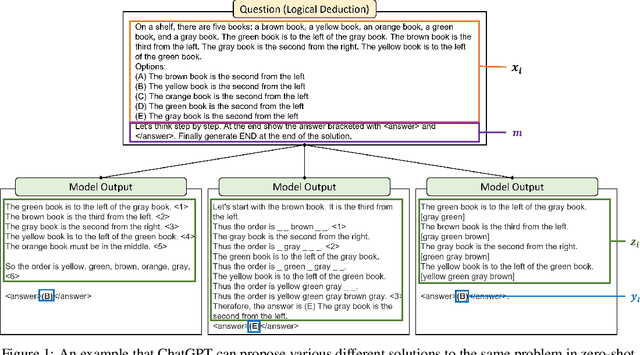
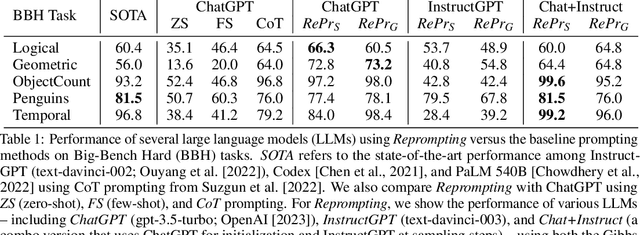
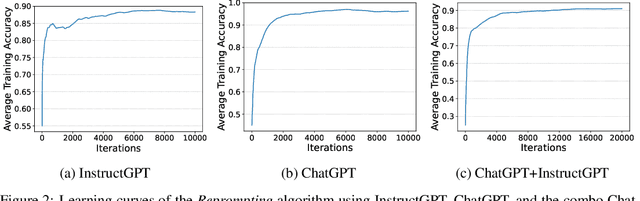

We introduce Reprompting, an iterative sampling algorithm that searches for the Chain-of-Thought (CoT) recipes for a given task without human intervention. Through Gibbs sampling, we infer CoT recipes that work consistently well for a set of training samples. Our method iteratively samples new recipes using previously sampled solutions as parent prompts to solve other training problems. On five Big-Bench Hard tasks that require multi-step reasoning, Reprompting achieves consistently better performance than the zero-shot, few-shot, and human-written CoT baselines. Reprompting can also facilitate transfer of knowledge from a stronger model to a weaker model leading to substantially improved performance of the weaker model. Overall, Reprompting brings up to +17 point improvements over the previous state-of-the-art method that uses human-written CoT prompts.
Understanding and Detecting Hallucinations in Neural Machine Translation via Model Introspection
Jan 18, 2023Neural sequence generation models are known to "hallucinate", by producing outputs that are unrelated to the source text. These hallucinations are potentially harmful, yet it remains unclear in what conditions they arise and how to mitigate their impact. In this work, we first identify internal model symptoms of hallucinations by analyzing the relative token contributions to the generation in contrastive hallucinated vs. non-hallucinated outputs generated via source perturbations. We then show that these symptoms are reliable indicators of natural hallucinations, by using them to design a lightweight hallucination detector which outperforms both model-free baselines and strong classifiers based on quality estimation or large pre-trained models on manually annotated English-Chinese and German-English translation test beds.