 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
Feb 03, 2026While passive agents merely follow instructions, proactive agents align with higher-level objectives, such as assistance and safety by continuously monitoring the environment to determine when and how to act. However, developing proactive agents is hindered by the lack of specialized resources. To address this, we introduce ProAct-75, a benchmark designed to train and evaluate proactive agents across diverse domains, including assistance, maintenance, and safety monitoring. Spanning 75 tasks, our dataset features 91,581 step-level annotations enriched with explicit task graphs. These graphs encode step dependencies and parallel execution possibilities, providing the structural grounding necessary for complex decision-making. Building on this benchmark, we propose ProAct-Helper, a reference baseline powered by a Multimodal Large Language Model (MLLM) that grounds decision-making in state detection, and leveraging task graphs to enable entropy-driven heuristic search for action selection, allowing agents to execute parallel threads independently rather than mirroring the human's next step. Extensive experiments demonstrate that ProAct-Helper outperforms strong closed-source models, improving trigger detection mF1 by 6.21%, saving 0.25 more steps in online one-step decision, and increasing the rate of parallel actions by 15.58%.
Diminution: On Reducing the Size of Grounding ASP Programs
Aug 12, 2025Answer Set Programming (ASP) is often hindered by the grounding bottleneck: large Herbrand universes generate ground programs so large that solving becomes difficult. Many methods employ ad-hoc heuristics to improve grounding performance, motivating the need for a more formal and generalizable strategy. We introduce the notion of diminution, defined as a selected subset of the Herbrand universe used to generate a reduced ground program before solving. We give a formal definition of diminution, analyze its key properties, and study the complexity of identifying it. We use a specific encoding that enables off-the-shelf ASP solver to evaluate candidate subsets. Our approach integrates seamlessly with existing grounders via domain predicates. In extensive experiments on five benchmarks, applying diminutions selected by our strategy yields significant performance improvements, reducing grounding time by up to 70% on average and decreasing the size of grounding files by up to 85%. These results demonstrate that leveraging diminutions constitutes a robust and general-purpose approach for alleviating the grounding bottleneck in ASP.
The Combined Problem of Online Task Assignment and Lifelong Path Finding in Logistics Warehouses: A Case Study
Feb 11, 2025



We study the combined problem of online task assignment and lifelong path finding, which is crucial for the logistics industries. However, most literature either (1) focuses on lifelong path finding assuming a given task assigner, or (2) studies the offline version of this problem where tasks are known in advance. We argue that, to maximize the system throughput, the online version that integrates these two components should be tackled directly. To this end, we introduce a formal framework of the combined problem and its solution concept. Then, we design a rule-based lifelong planner under a practical robot model that works well even in environments with severe local congestion. Upon that, we automate the search for the task assigner with respect to the underlying path planner. Simulation experiments conducted in warehouse scenarios at \textit{Meituan}, one of the largest shopping platforms in China, demonstrate that (a)~\textit{in terms of time efficiency}, our system requires only 83.77\% of the execution time needed for the currently deployed system at Meituan, outperforming other SOTA algorithms by 8.09\%; (b)~\textit{in terms of economic efficiency}, ours can achieve the same throughput with only 60\% of the agents currently in use.
Reaching Consensus in Cooperative Multi-Agent Reinforcement Learning with Goal Imagination
Mar 05, 2024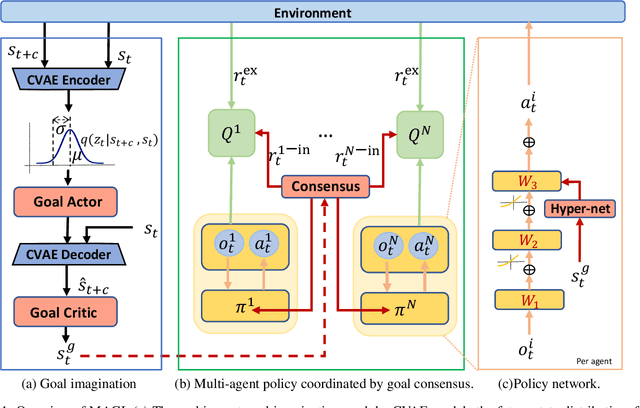
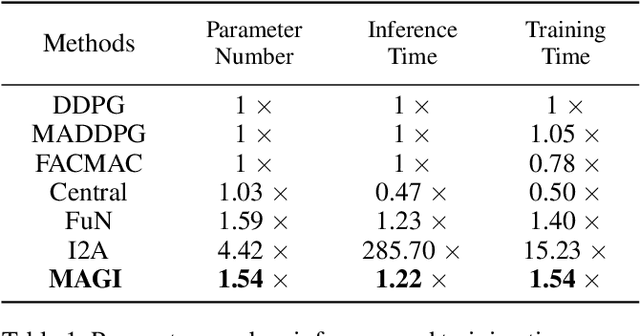
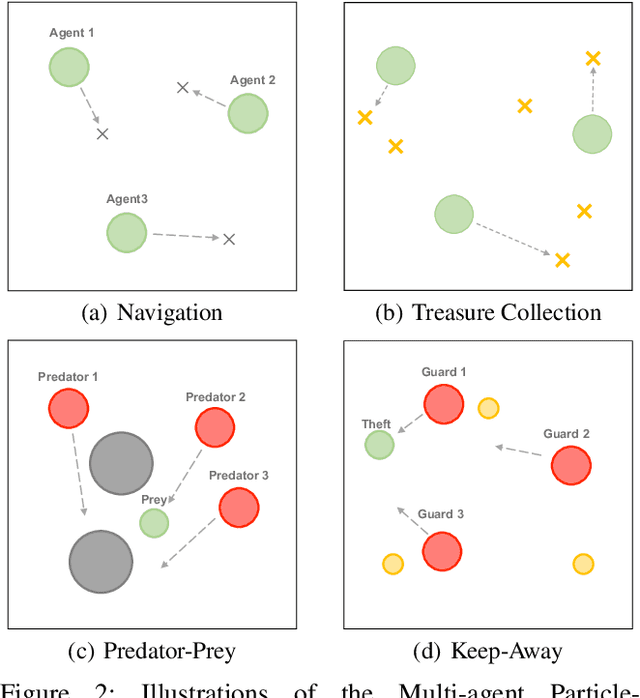

Reaching consensus is key to multi-agent coordination. To accomplish a cooperative task, agents need to coherently select optimal joint actions to maximize the team reward. However, current cooperative multi-agent reinforcement learning (MARL) methods usually do not explicitly take consensus into consideration, which may cause miscoordination problem. In this paper, we propose a model-based consensus mechanism to explicitly coordinate multiple agents. The proposed Multi-agent Goal Imagination (MAGI) framework guides agents to reach consensus with an Imagined common goal. The common goal is an achievable state with high value, which is obtained by sampling from the distribution of future states. We directly model this distribution with a self-supervised generative model, thus alleviating the "curse of dimensinality" problem induced by multi-agent multi-step policy rollout commonly used in model-based methods. We show that such efficient consensus mechanism can guide all agents cooperatively reaching valuable future states. Results on Multi-agent Particle-Environments and Google Research Football environment demonstrate the superiority of MAGI in both sample efficiency and performance.
On Computing Universal Plans for Partially Observable Multi-Agent Path Finding
May 25, 2023Multi-agent routing problems have drawn significant attention nowadays due to their broad industrial applications in, e.g., warehouse robots, logistics automation, and traffic control. Conventionally, they are modelled as classical planning problems. In this paper, we argue that it is beneficial to formulate them as universal planning problems. We therefore propose universal plans, also known as policies, as the solution concepts, and implement a system called ASP-MAUPF (Answer Set Programming for Multi-Agent Universal Plan Finding) for computing them. Given an arbitrary two-dimensional map and a profile of goals for the agents, the system finds a feasible universal plan for each agent that ensures no collision with others. We use the system to conduct some experiments, and make some observations on the types of goal profiles and environments that will have feasible policies, and how they may depend on agents' sensors. We also demonstrate how users can customize action preferences to compute more efficient policies, even (near-)optimal ones.
TiKick: Towards Playing Multi-agent Football Full Games from Single-agent Demonstrations
Oct 19, 2021

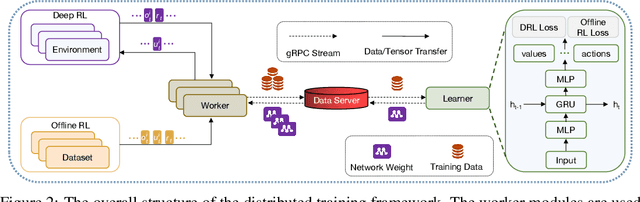
Deep reinforcement learning (DRL) has achieved super-human performance on complex video games (e.g., StarCraft II and Dota II). However, current DRL systems still suffer from challenges of multi-agent coordination, sparse rewards, stochastic environments, etc. In seeking to address these challenges, we employ a football video game, e.g., Google Research Football (GRF), as our testbed and develop an end-to-end learning-based AI system (denoted as TiKick) to complete this challenging task. In this work, we first generated a large replay dataset from the self-playing of single-agent experts, which are obtained from league training. We then developed a distributed learning system and new offline algorithms to learn a powerful multi-agent AI from the fixed single-agent dataset. To the best of our knowledge, Tikick is the first learning-based AI system that can take over the multi-agent Google Research Football full game, while previous work could either control a single agent or experiment on toy academic scenarios. Extensive experiments further show that our pre-trained model can accelerate the training process of the modern multi-agent algorithm and our method achieves state-of-the-art performances on various academic scenarios.
Modeling Varying Camera-IMU Time Offset in Optimization-Based Visual-Inertial Odometry
Oct 12, 2018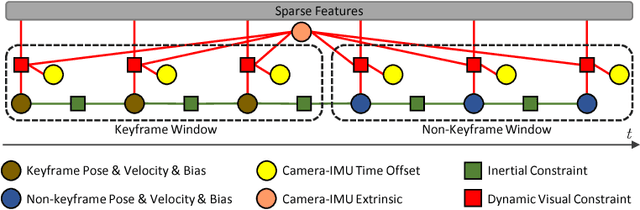
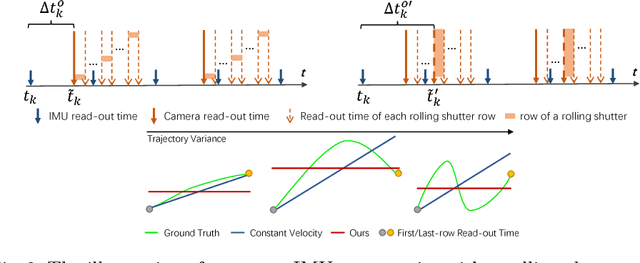
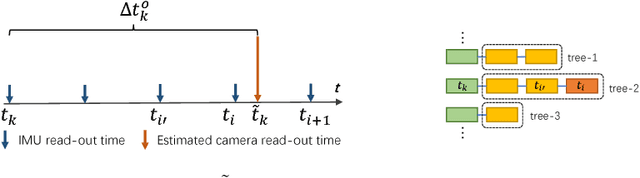
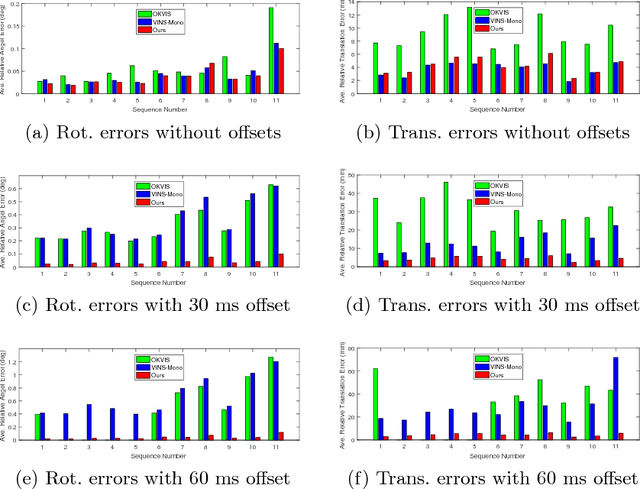
Combining cameras and inertial measurement units (IMUs) has been proven effective in motion tracking, as these two sensing modalities offer complementary characteristics that are suitable for fusion. While most works focus on global-shutter cameras and synchronized sensor measurements, consumer-grade devices are mostly equipped with rolling-shutter cameras and suffer from imperfect sensor synchronization. In this work, we propose a nonlinear optimization-based monocular visual inertial odometry (VIO) with varying camera-IMU time offset modeled as an unknown variable. Our approach is able to handle the rolling-shutter effects and imperfect sensor synchronization in a unified way. Additionally, we introduce an efficient algorithm based on dynamic programming and red-black tree to speed up IMU integration over variable-length time intervals during the optimization. An uncertainty-aware initialization is also presented to launch the VIO robustly. Comparisons with state-of-the-art methods on the Euroc dataset and mobile phone data are shown to validate the effectiveness of our approach.