 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025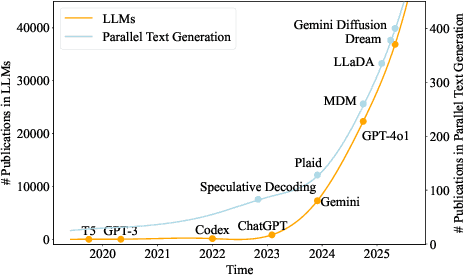
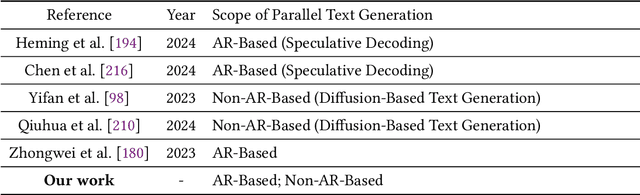
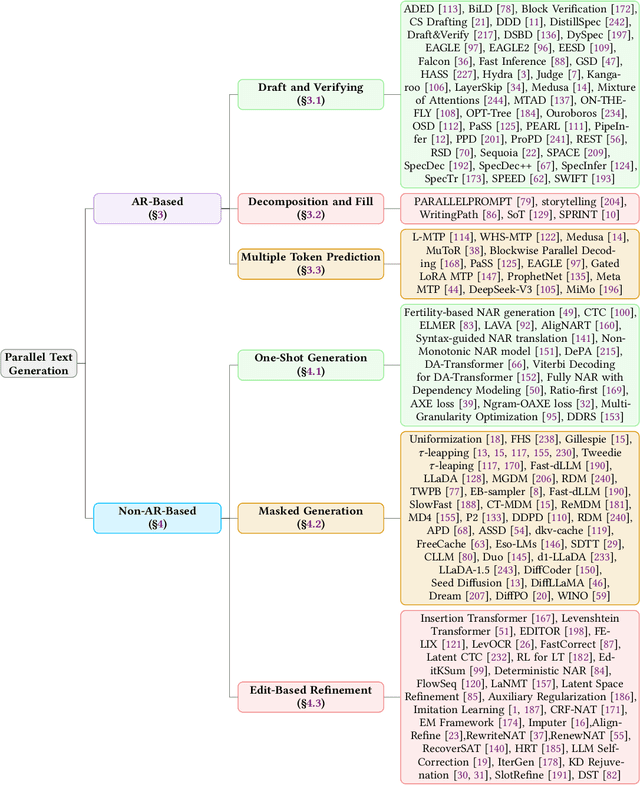
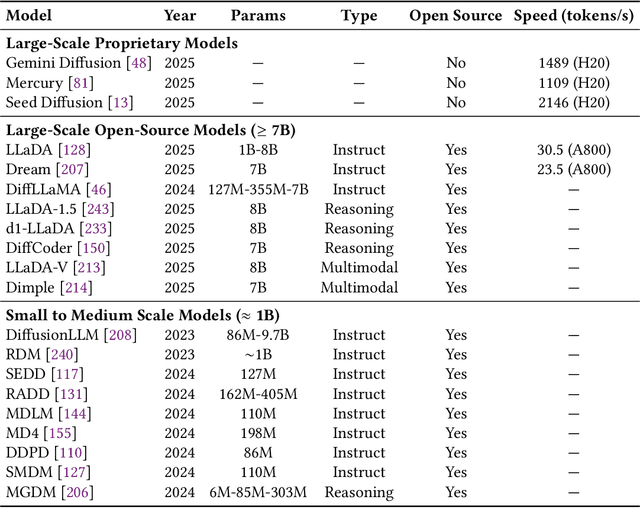
As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025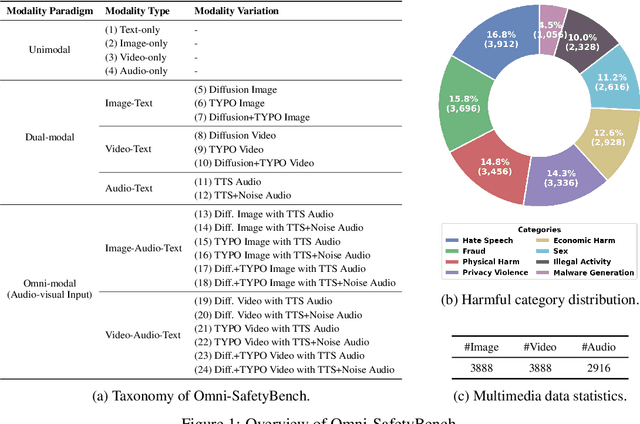
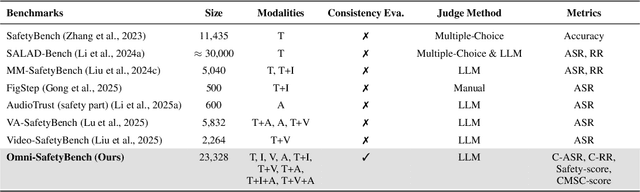
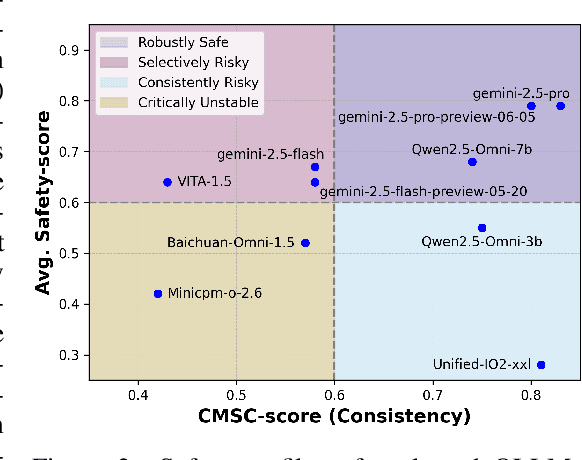
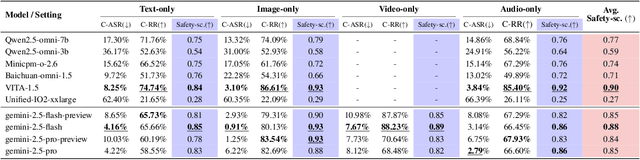
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?
Feb 17, 2025The radioactive nature of Large Language Model (LLM) watermarking enables the detection of watermarks inherited by student models when trained on the outputs of watermarked teacher models, making it a promising tool for preventing unauthorized knowledge distillation. However, the robustness of watermark radioactivity against adversarial actors remains largely unexplored. In this paper, we investigate whether student models can acquire the capabilities of teacher models through knowledge distillation while avoiding watermark inheritance. We propose two categories of watermark removal approaches: pre-distillation removal through untargeted and targeted training data paraphrasing (UP and TP), and post-distillation removal through inference-time watermark neutralization (WN). Extensive experiments across multiple model pairs, watermarking schemes and hyper-parameter settings demonstrate that both TP and WN thoroughly eliminate inherited watermarks, with WN achieving this while maintaining knowledge transfer efficiency and low computational overhead. Given the ongoing deployment of watermarking techniques in production LLMs, these findings emphasize the urgent need for more robust defense strategies. Our code is available at https://github.com/THU-BPM/Watermark-Radioactivity-Attack.
MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models
Jan 06, 2025
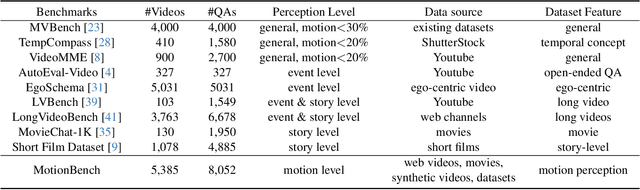


In recent years, vision language models (VLMs) have made significant advancements in video understanding. However, a crucial capability - fine-grained motion comprehension - remains under-explored in current benchmarks. To address this gap, we propose MotionBench, a comprehensive evaluation benchmark designed to assess the fine-grained motion comprehension of video understanding models. MotionBench evaluates models' motion-level perception through six primary categories of motion-oriented question types and includes data collected from diverse sources, ensuring a broad representation of real-world video content. Experimental results reveal that existing VLMs perform poorly in understanding fine-grained motions. To enhance VLM's ability to perceive fine-grained motion within a limited sequence length of LLM, we conduct extensive experiments reviewing VLM architectures optimized for video feature compression and propose a novel and efficient Through-Encoder (TE) Fusion method. Experiments show that higher frame rate inputs and TE Fusion yield improvements in motion understanding, yet there is still substantial room for enhancement. Our benchmark aims to guide and motivate the development of more capable video understanding models, emphasizing the importance of fine-grained motion comprehension. Project page: https://motion-bench.github.io .
VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation
Dec 30, 2024We present a general strategy to aligning visual generation models -- both image and video generation -- with human preference. To start with, we build VisionReward -- a fine-grained and multi-dimensional reward model. We decompose human preferences in images and videos into multiple dimensions, each represented by a series of judgment questions, linearly weighted and summed to an interpretable and accurate score. To address the challenges of video quality assessment, we systematically analyze various dynamic features of videos, which helps VisionReward surpass VideoScore by 17.2% and achieve top performance for video preference prediction. Based on VisionReward, we develop a multi-objective preference learning algorithm that effectively addresses the issue of confounding factors within preference data. Our approach significantly outperforms existing image and video scoring methods on both machine metrics and human evaluation. All code and datasets are provided at https://github.com/THUDM/VisionReward.
ICT: Image-Object Cross-Level Trusted Intervention for Mitigating Object Hallucination in Large Vision-Language Models
Nov 22, 2024Despite the recent breakthroughs achieved by Large Vision Language Models (LVLMs) in understanding and responding to complex visual-textual contexts, their inherent hallucination tendencies limit their practical application in real-world scenarios that demand high levels of precision. Existing methods typically either fine-tune the LVLMs using additional data, which incurs extra costs in manual annotation and computational resources or perform comparisons at the decoding stage, which may eliminate useful language priors for reasoning while introducing inference time overhead. Therefore, we propose ICT, a lightweight, training-free method that calculates an intervention direction to shift the model's focus towards different levels of visual information, enhancing its attention to high-level and fine-grained visual details. During the forward pass stage, the intervention is applied to the attention heads that encode the overall image information and the fine-grained object details, effectively mitigating the phenomenon of overly language priors, and thereby alleviating hallucinations. Extensive experiments demonstrate that ICT achieves strong performance with a small amount of data and generalizes well across different datasets and models. Our code will be public.
DreamPolish: Domain Score Distillation With Progressive Geometry Generation
Nov 03, 2024



We introduce DreamPolish, a text-to-3D generation model that excels in producing refined geometry and high-quality textures. In the geometry construction phase, our approach leverages multiple neural representations to enhance the stability of the synthesis process. Instead of relying solely on a view-conditioned diffusion prior in the novel sampled views, which often leads to undesired artifacts in the geometric surface, we incorporate an additional normal estimator to polish the geometry details, conditioned on viewpoints with varying field-of-views. We propose to add a surface polishing stage with only a few training steps, which can effectively refine the artifacts attributed to limited guidance from previous stages and produce 3D objects with more desirable geometry. The key topic of texture generation using pretrained text-to-image models is to find a suitable domain in the vast latent distribution of these models that contains photorealistic and consistent renderings. In the texture generation phase, we introduce a novel score distillation objective, namely domain score distillation (DSD), to guide neural representations toward such a domain. We draw inspiration from the classifier-free guidance (CFG) in textconditioned image generation tasks and show that CFG and variational distribution guidance represent distinct aspects in gradient guidance and are both imperative domains for the enhancement of texture quality. Extensive experiments show our proposed model can produce 3D assets with polished surfaces and photorealistic textures, outperforming existing state-of-the-art methods.
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024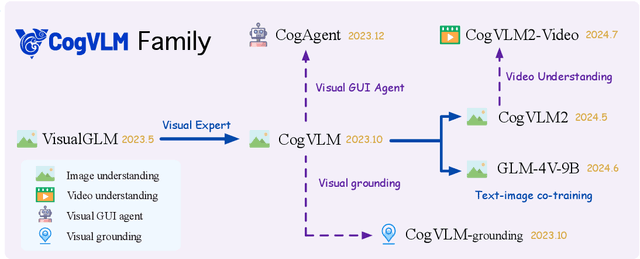

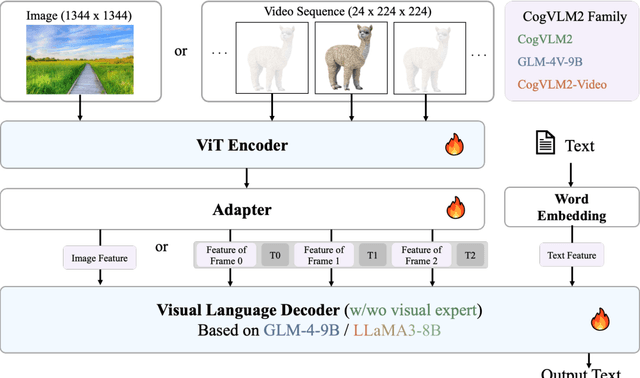
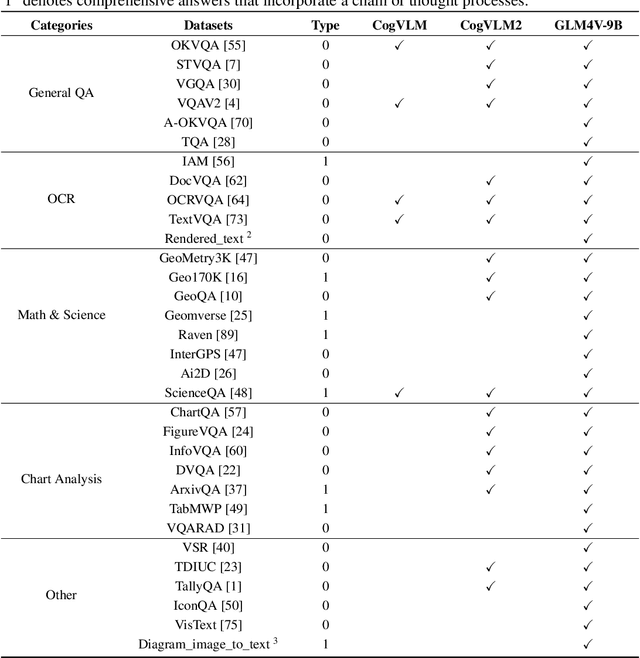
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Aug 12, 2024We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficently model video data, we propose to levearge a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions. To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions. In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method. It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations. The model weights of both the 3D Causal VAE and CogVideoX are publicly available at https://github.com/THUDM/CogVideo.