 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable Process Rewards for Agentic Reasoning
May 11, 2026Reinforcement learning from verifiable rewards (RLVR) has improved the reasoning abilities of large language models (LLMs), but most existing approaches rely on sparse outcome-level feedback. This sparsity creates a credit assignment challenge in long-horizon agentic reasoning: a trajectory may fail despite containing many correct intermediate decisions, or succeed despite containing flawed ones. In this work, we study a class of densely-verifiable agentic reasoning problems, where intermediate actions can be objectively checked by symbolic or algorithmic oracles. We propose Verifiable Process Rewards (VPR), a framework that converts such oracles into dense turn-level supervision for reinforcement learning, and instantiate it in three representative settings: search-based verification for dynamic deduction, constraint-based verification for logical reasoning, and posterior-based verification for probabilistic inference. We further provide a theoretical analysis showing that dense verifier-grounded rewards can improve long-horizon credit assignment by providing more localized learning signals, with the benefit depending on the reliability of the verifier. Empirically, VPR outperforms outcome-level reward and rollout-based process reward baselines across controlled environments, and more importantly, transfers to both general and agentic reasoning benchmarks, suggesting that verifiable process supervision can foster general reasoning skills applicable beyond the training environments. Our results indicate that VPR is a promising approach for enhancing LLM agents whenever reliable intermediate verification is available, while also highlighting its dependence on oracle quality and the open challenge of extending VPR to less structured, open-ended environments.
MAGE: Meta-Reinforcement Learning for Language Agents toward Strategic Exploration and Exploitation
Mar 04, 2026Large Language Model (LLM) agents have demonstrated remarkable proficiency in learned tasks, yet they often struggle to adapt to non-stationary environments with feedback. While In-Context Learning and external memory offer some flexibility, they fail to internalize the adaptive ability required for long-term improvement. Meta-Reinforcement Learning (meta-RL) provides an alternative by embedding the learning process directly within the model. However, existing meta-RL approaches for LLMs focus primarily on exploration in single-agent settings, neglecting the strategic exploitation necessary for multi-agent environments. We propose MAGE, a meta-RL framework that empowers LLM agents for strategic exploration and exploitation. MAGE utilizes a multi-episode training regime where interaction histories and reflections are integrated into the context window. By using the final episode reward as the objective, MAGE incentivizes the agent to refine its strategy based on past experiences. We further combine population-based training with an agent-specific advantage normalization technique to enrich agent diversity and ensure stable learning. Experiment results show that MAGE outperforms existing baselines in both exploration and exploitation tasks. Furthermore, MAGE exhibits strong generalization to unseen opponents, suggesting it has internalized the ability for strategic exploration and exploitation. Code is available at https://github.com/Lu-Yang666/MAGE.
WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
Feb 04, 2026Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent-subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Mastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning
May 07, 2025In this paper, we tackle the problem of learning to play 3v3 multi-drone volleyball, a new embodied competitive task that requires both high-level strategic coordination and low-level agile control. The task is turn-based, multi-agent, and physically grounded, posing significant challenges due to its long-horizon dependencies, tight inter-agent coupling, and the underactuated dynamics of quadrotors. To address this, we propose Hierarchical Co-Self-Play (HCSP), a hierarchical reinforcement learning framework that separates centralized high-level strategic decision-making from decentralized low-level motion control. We design a three-stage population-based training pipeline to enable both strategy and skill to emerge from scratch without expert demonstrations: (I) training diverse low-level skills, (II) learning high-level strategy via self-play with fixed low-level controllers, and (III) joint fine-tuning through co-self-play. Experiments show that HCSP achieves superior performance, outperforming non-hierarchical self-play and rule-based hierarchical baselines with an average 82.9\% win rate and a 71.5\% win rate against the two-stage variant. Moreover, co-self-play leads to emergent team behaviors such as role switching and coordinated formations, demonstrating the effectiveness of our hierarchical design and training scheme.
AED: Automatic Discovery of Effective and Diverse Vulnerabilities for Autonomous Driving Policy with Large Language Models
Mar 24, 2025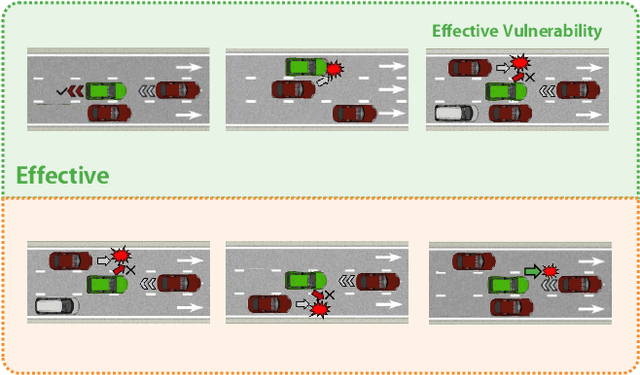


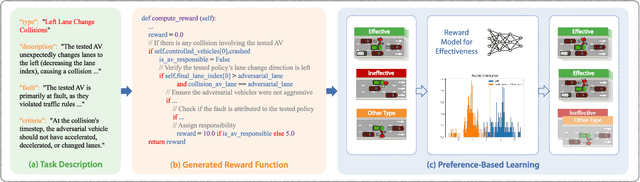
Assessing the safety of autonomous driving policy is of great importance, and reinforcement learning (RL) has emerged as a powerful method for discovering critical vulnerabilities in driving policies. However, existing RL-based approaches often struggle to identify vulnerabilities that are both effective-meaning the autonomous vehicle is genuinely responsible for the accidents-and diverse-meaning they span various failure types. To address these challenges, we propose AED, a framework that uses large language models (LLMs) to automatically discover effective and diverse vulnerabilities in autonomous driving policies. We first utilize an LLM to automatically design reward functions for RL training. Then we let the LLM consider a diverse set of accident types and train adversarial policies for different accident types in parallel. Finally, we use preference-based learning to filter ineffective accidents and enhance the effectiveness of each vulnerability. Experiments across multiple simulated traffic scenarios and tested policies show that AED uncovers a broader range of vulnerabilities and achieves higher attack success rates compared with expert-designed rewards, thereby reducing the need for manual reward engineering and improving the diversity and effectiveness of vulnerability discovery.
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Feb 07, 2025



Large language model (LLM)-based agents have recently shown impressive progress in a variety of domains, including open-ended conversation and multi-step decision-making. However, applying these agents to social deduction games such as Werewolf, which requires both strategic decision-making and free-form language interaction, remains non-trivial. Traditional methods based on Counterfactual Regret Minimization (CFR) or reinforcement learning (RL) typically depend on a predefined action space, making them unsuitable for language games with unconstrained text action space. Meanwhile, pure LLM-based agents often suffer from intrinsic biases and require prohibitively large datasets for fine-tuning. We propose Latent Space Policy Optimization (LSPO), an iterative framework that addresses these challenges by first mapping free-form text to a discrete latent space, where methods like CFR and RL can learn strategic policy more effectively. We then translate the learned policy back into natural language dialogues, which are used to fine-tune an LLM via Direct Preference Optimization (DPO). By iteratively alternating between these stages, our LSPO agent progressively enhances both strategic reasoning and language communication. Experiment results on the Werewolf game show that our method improves the agent's performance in each iteration and outperforms existing Werewolf agents, underscoring its promise for free-form language decision-making.
VolleyBots: A Testbed for Multi-Drone Volleyball Game Combining Motion Control and Strategic Play
Feb 04, 2025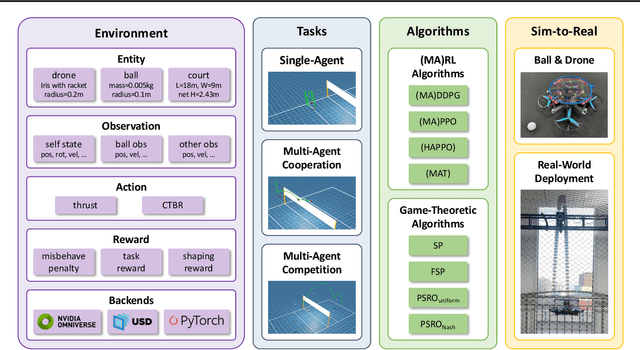
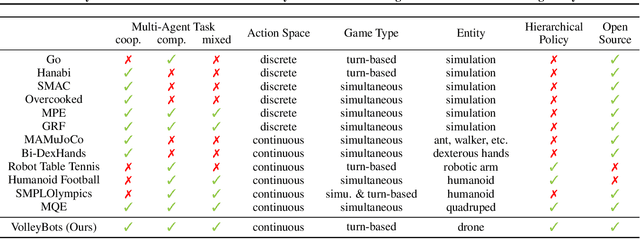
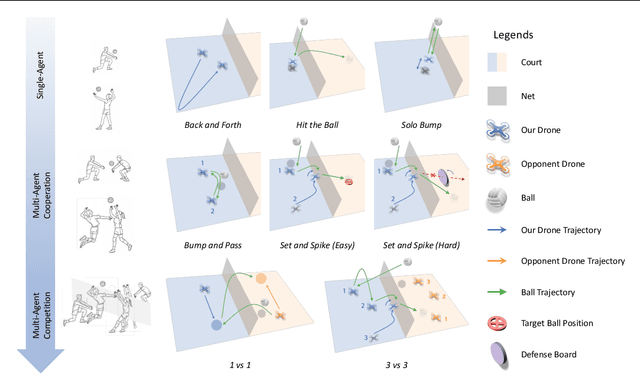

Multi-agent reinforcement learning (MARL) has made significant progress, largely fueled by the development of specialized testbeds that enable systematic evaluation of algorithms in controlled yet challenging scenarios. However, existing testbeds often focus on purely virtual simulations or limited robot morphologies such as robotic arms, quadrupeds, and humanoids, leaving high-mobility platforms with real-world physical constraints like drones underexplored. To bridge this gap, we present VolleyBots, a new MARL testbed where multiple drones cooperate and compete in the sport of volleyball under physical dynamics. VolleyBots features a turn-based interaction model under volleyball rules, a hierarchical decision-making process that combines motion control and strategic play, and a high-fidelity simulation for seamless sim-to-real transfer. We provide a comprehensive suite of tasks ranging from single-drone drills to multi-drone cooperative and competitive tasks, accompanied by baseline evaluations of representative MARL and game-theoretic algorithms. Results in simulation show that while existing algorithms handle simple tasks effectively, they encounter difficulty in complex tasks that require both low-level control and high-level strategy. We further demonstrate zero-shot deployment of a simulation-learned policy to real-world drones, highlighting VolleyBots' potential to propel MARL research involving agile robotic platforms. The project page is at https://sites.google.com/view/volleybots/home.
A Survey on Self-play Methods in Reinforcement Learning
Aug 02, 2024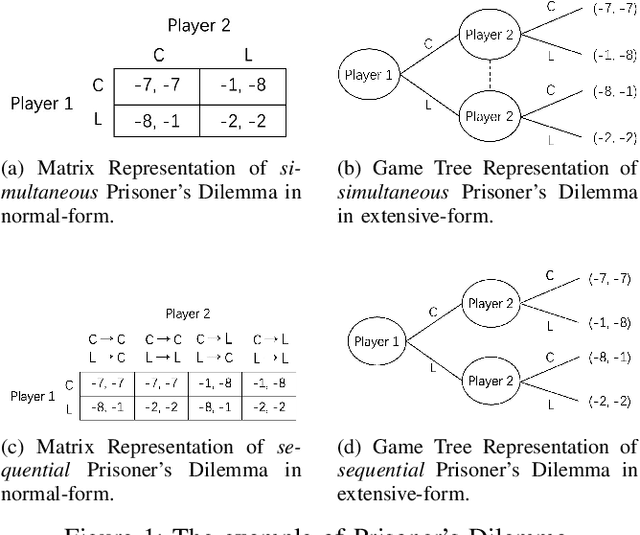
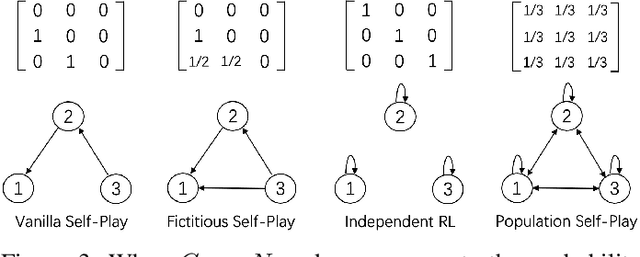
Self-play, characterized by agents' interactions with copies or past versions of itself, has recently gained prominence in reinforcement learning. This paper first clarifies the preliminaries of self-play, including the multi-agent reinforcement learning framework and basic game theory concepts. Then it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different scenarios. Finally, the survey highlights open challenges and future research directions in self-play. This paper is an essential guide map for understanding the multifaceted landscape of self-play in RL.
Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game
Oct 29, 2023



Agents built with large language models (LLMs) have recently achieved great advancements. However, most of the efforts focus on single-agent or cooperative settings, leaving more general multi-agent environments underexplored. We propose a new framework powered by reinforcement learning (RL) to develop strategic language agents, i.e., LLM-based agents with strategic thinking ability, for a popular language game, Werewolf. Werewolf is a social deduction game with hidden roles that involves both cooperation and competition and emphasizes deceptive communication and diverse gameplay. Our agent tackles this game by first using LLMs to reason about potential deceptions and generate a set of strategically diverse actions. Then an RL policy, which selects an action from the candidates, is learned by population-based training to enhance the agents' decision-making ability. By combining LLMs with the RL policy, our agent produces a variety of emergent strategies, achieves the highest win rate against other LLM-based agents, and stays robust against adversarial human players in the Werewolf game.