 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Feb 07, 2025



Large language model (LLM)-based agents have recently shown impressive progress in a variety of domains, including open-ended conversation and multi-step decision-making. However, applying these agents to social deduction games such as Werewolf, which requires both strategic decision-making and free-form language interaction, remains non-trivial. Traditional methods based on Counterfactual Regret Minimization (CFR) or reinforcement learning (RL) typically depend on a predefined action space, making them unsuitable for language games with unconstrained text action space. Meanwhile, pure LLM-based agents often suffer from intrinsic biases and require prohibitively large datasets for fine-tuning. We propose Latent Space Policy Optimization (LSPO), an iterative framework that addresses these challenges by first mapping free-form text to a discrete latent space, where methods like CFR and RL can learn strategic policy more effectively. We then translate the learned policy back into natural language dialogues, which are used to fine-tune an LLM via Direct Preference Optimization (DPO). By iteratively alternating between these stages, our LSPO agent progressively enhances both strategic reasoning and language communication. Experiment results on the Werewolf game show that our method improves the agent's performance in each iteration and outperforms existing Werewolf agents, underscoring its promise for free-form language decision-making.
LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA
Sep 04, 2024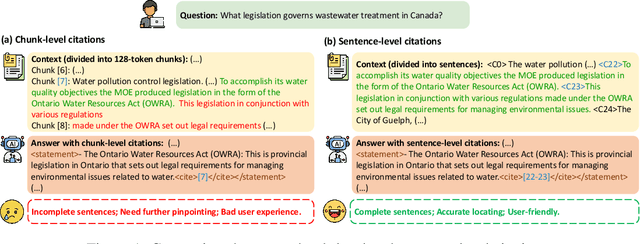


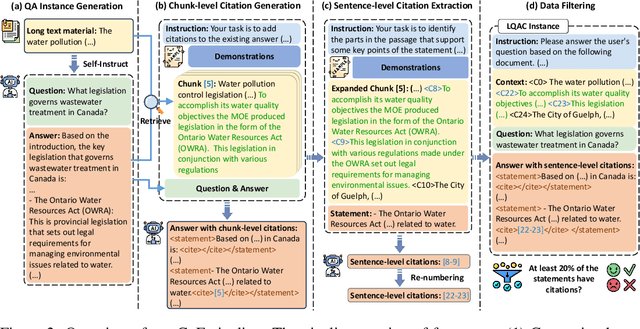
Though current long-context large language models (LLMs) have demonstrated impressive capacities in answering user questions based on extensive text, the lack of citations in their responses makes user verification difficult, leading to concerns about their trustworthiness due to their potential hallucinations. In this work, we aim to enable long-context LLMs to generate responses with fine-grained sentence-level citations, improving their faithfulness and verifiability. We first introduce LongBench-Cite, an automated benchmark for assessing current LLMs' performance in Long-Context Question Answering with Citations (LQAC), revealing considerable room for improvement. To this end, we propose CoF (Coarse to Fine), a novel pipeline that utilizes off-the-shelf LLMs to automatically generate long-context QA instances with precise sentence-level citations, and leverage this pipeline to construct LongCite-45k, a large-scale SFT dataset for LQAC. Finally, we train LongCite-8B and LongCite-9B using the LongCite-45k dataset, successfully enabling their generation of accurate responses and fine-grained sentence-level citations in a single output. The evaluation results on LongBench-Cite show that our trained models achieve state-of-the-art citation quality, surpassing advanced proprietary models including GPT-4o.