 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Critical Branching Mechanism in Recurrent Neural Networks
Jun 09, 2026Criticality has been proposed as a key organizing principle in biological neural systems, yet its origin and relevance in artificial neural networks remain unclear. We analyze hidden-state dynamics in trained long short-term memory (LSTM) networks and show that small networks near their optimal training epochs (steps) exhibit scale-free avalanche statistics and branching parameters close to unity, indicative of near-critical dynamics, while larger models remain subcritical. To explain the coexistence of subcritical branching with robust $1/f^β$ noise, we introduce a mixture branching process framework that links heterogeneous branching dynamics to long-range temporal correlations. These results identify critical-like behavior in LSTMs as an emergent, capacity-dependent dynamical regime.
A Unified Graph Language Model for Multi-Domain Multi-Task Graph Alignment Instruction Tuning
May 12, 2026Leveraging Graph Neural Networks (GNNs) as graph encoders and aligning the resulting representations with Large Language Models (LLMs) through alignment instruction tuning has become a mainstream paradigm for constructing Graph Language Models (GLMs), combining the generalization ability of LLMs with the structural modeling capacity of GNNs. However, existing GLMs that adopt GNNs as graph encoders largely overlook the problem of aligning GNN-encoded representations across domains and tasks with the LLM token space to obtain unified graph tokens, thereby limiting their ability to generalize across diverse graph data. To bridge this gap, we aim to incorporate a multi-domain, multi-task GNN encoder into GLMs and align its representations with LLMs to enable multi-domain, multi-task graph alignment instruction tuning. This alignment problem remains underexplored and poses two key challenges: 1) learning GNN-encoded representations that are simultaneously generalizable across domains and tasks and well aligned with textual semantics is difficult, due to substantial variations in graph structures, feature distributions, and supervision signals, together with the lack of textual-semantic alignment guidance in task-specific GNN training; 2) diverse graph data and task-specific instructions can exhibit different degrees of compatibility with the LLM token space during instruction tuning, leading to varying alignment difficulty and rendering a fixed alignment strategy suboptimal. To tackle these challenges, we propose UniGraphLM, a Unified Graph Language Model that incorporates a multi-domain, multi-task GNN encoder to learn generalizable graph representations aligned with textual semantics, and then adaptively aligns these representations with the LLM.
Multi-Agent Causal Reasoning for Suicide Ideation Detection Through Online Conversations
Feb 27, 2026Suicide remains a pressing global public health concern. While social media platforms offer opportunities for early risk detection through online conversation trees, existing approaches face two major limitations: (1) They rely on predefined rules (e.g., quotes or relies) to log conversations that capture only a narrow spectrum of user interactions, and (2) They overlook hidden influences such as user conformity and suicide copycat behavior, which can significantly affect suicidal expression and propagation in online communities. To address these limitations, we propose a Multi-Agent Causal Reasoning (MACR) framework that collaboratively employs a Reasoning Agent to scale user interactions and a Bias-aware Decision-Making Agent to mitigate harmful biases arising from hidden influences. The Reasoning Agent integrates cognitive appraisal theory to generate counterfactual user reactions to posts, thereby scaling user interactions. It analyses these reactions through structured dimensions, i.e., cognitive, emotional, and behavioral patterns, with a dedicated sub-agent responsible for each dimension. The Bias-aware Decision-Making Agent mitigates hidden biases through a front-door adjustment strategy, leveraging the counterfactual user reactions produced by the Reasoning Agent. Through the collaboration of reasoning and bias-aware decision making, the proposed MACR framework not only alleviates hidden biases, but also enriches contextual information of user interactions with counterfactual knowledge. Extensive experiments on real-world conversational datasets demonstrate the effectiveness and robustness of MACR in identifying suicide risk.
Chaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards
Jan 09, 2026Reinforcement learning (RL) has emerged as a critical technique for enhancing LLM-based deep search agents. However, existing approaches primarily rely on binary outcome rewards, which fail to capture the comprehensiveness and factuality of agents' reasoning process, and often lead to undesirable behaviors such as shortcut exploitation and hallucinations. To address these limitations, we propose \textbf{Citation-aware Rubric Rewards (CaRR)}, a fine-grained reward framework for deep search agents that emphasizes reasoning comprehensiveness, factual grounding, and evidence connectivity. CaRR decomposes complex questions into verifiable single-hop rubrics and requires agents to satisfy these rubrics by explicitly identifying hidden entities, supporting them with correct citations, and constructing complete evidence chains that link to the predicted answer. We further introduce \textbf{Citation-aware Group Relative Policy Optimization (C-GRPO)}, which combines CaRR and outcome rewards for training robust deep search agents. Experiments show that C-GRPO consistently outperforms standard outcome-based RL baselines across multiple deep search benchmarks. Our analysis also validates that C-GRPO effectively discourages shortcut exploitation, promotes comprehensive, evidence-grounded reasoning, and exhibits strong generalization to open-ended deep research tasks. Our code and data are available at https://github.com/THUDM/CaRR.
Spatial-aware Vision Language Model for Autonomous Driving
Dec 30, 2025While Vision-Language Models (VLMs) show significant promise for end-to-end autonomous driving by leveraging the common sense embedded in language models, their reliance on 2D image cues for complex scene understanding and decision-making presents a critical bottleneck for safety and reliability. Current image-based methods struggle with accurate metric spatial reasoning and geometric inference, leading to unreliable driving policies. To bridge this gap, we propose LVLDrive (LiDAR-Vision-Language), a novel framework specifically designed to upgrade existing VLMs with robust 3D metric spatial understanding for autonomous driving by incoperating LiDAR point cloud as an extra input modality. A key challenge lies in mitigating the catastrophic disturbance introduced by disparate 3D data to the pre-trained VLMs. To this end, we introduce a Gradual Fusion Q-Former that incrementally injects LiDAR features, ensuring the stability and preservation of the VLM's existing knowledge base. Furthermore, we develop a spatial-aware question-answering (SA-QA) dataset to explicitly teach the model advanced 3D perception and reasoning capabilities. Extensive experiments on driving benchmarks demonstrate that LVLDrive achieves superior performance compared to vision-only counterparts across scene understanding, metric spatial perception, and reliable driving decision-making. Our work highlights the necessity of explicit 3D metric data for building trustworthy VLM-based autonomous systems.
Multiple Descents in Deep Learning as a Sequence of Order-Chaos Transitions
May 26, 2025We observe a novel 'multiple-descent' phenomenon during the training process of LSTM, in which the test loss goes through long cycles of up and down trend multiple times after the model is overtrained. By carrying out asymptotic stability analysis of the models, we found that the cycles in test loss are closely associated with the phase transition process between order and chaos, and the local optimal epochs are consistently at the critical transition point between the two phases. More importantly, the global optimal epoch occurs at the first transition from order to chaos, where the 'width' of the 'edge of chaos' is the widest, allowing the best exploration of better weight configurations for learning.
AdaptThink: Reasoning Models Can Learn When to Think
May 19, 2025Recently, large reasoning models have achieved impressive performance on various tasks by employing human-like deep thinking. However, the lengthy thinking process substantially increases inference overhead, making efficiency a critical bottleneck. In this work, we first demonstrate that NoThinking, which prompts the reasoning model to skip thinking and directly generate the final solution, is a better choice for relatively simple tasks in terms of both performance and efficiency. Motivated by this, we propose AdaptThink, a novel RL algorithm to teach reasoning models to choose the optimal thinking mode adaptively based on problem difficulty. Specifically, AdaptThink features two core components: (1) a constrained optimization objective that encourages the model to choose NoThinking while maintaining the overall performance; (2) an importance sampling strategy that balances Thinking and NoThinking samples during on-policy training, thereby enabling cold start and allowing the model to explore and exploit both thinking modes throughout the training process. Our experiments indicate that AdaptThink significantly reduces the inference costs while further enhancing performance. Notably, on three math datasets, AdaptThink reduces the average response length of DeepSeek-R1-Distill-Qwen-1.5B by 53% and improves its accuracy by 2.4%, highlighting the promise of adaptive thinking-mode selection for optimizing the balance between reasoning quality and efficiency. Our codes and models are available at https://github.com/THU-KEG/AdaptThink.
MISE: Meta-knowledge Inheritance for Social Media-Based Stressor Estimation
May 03, 2025Stress haunts people in modern society, which may cause severe health issues if left unattended. With social media becoming an integral part of daily life, leveraging social media to detect stress has gained increasing attention. While the majority of the work focuses on classifying stress states and stress categories, this study introduce a new task aimed at estimating more specific stressors (like exam, writing paper, etc.) through users' posts on social media. Unfortunately, the diversity of stressors with many different classes but a few examples per class, combined with the consistent arising of new stressors over time, hinders the machine understanding of stressors. To this end, we cast the stressor estimation problem within a practical scenario few-shot learning setting, and propose a novel meta-learning based stressor estimation framework that is enhanced by a meta-knowledge inheritance mechanism. This model can not only learn generic stressor context through meta-learning, but also has a good generalization ability to estimate new stressors with little labeled data. A fundamental breakthrough in our approach lies in the inclusion of the meta-knowledge inheritance mechanism, which equips our model with the ability to prevent catastrophic forgetting when adapting to new stressors. The experimental results show that our model achieves state-of-the-art performance compared with the baselines. Additionally, we construct a social media-based stressor estimation dataset that can help train artificial intelligence models to facilitate human well-being. The dataset is now public at \href{https://www.kaggle.com/datasets/xinwangcs/stressor-cause-of-mental-health-problem-dataset}{\underline{Kaggle}} and \href{https://huggingface.co/datasets/XinWangcs/Stressor}{\underline{Hugging Face}}.
DuckSegmentation: A segmentation model based on the AnYue Hemp Duck Dataset
Mar 27, 2025

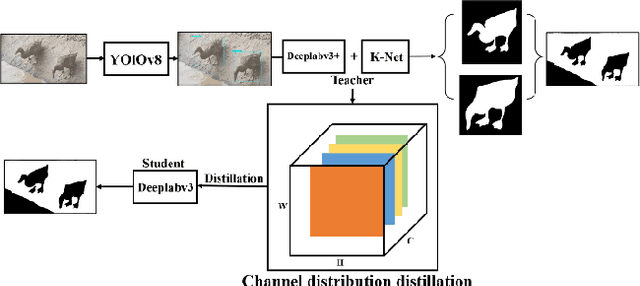

The modernization of smart farming is a way to improve agricultural production efficiency, and improve the agricultural production environment. Although many large models have achieved high accuracy in the task of object recognition and segmentation, they cannot really be put into use in the farming industry due to their own poor interpretability and limitations in computational volume. In this paper, we built AnYue Shelduck Dateset, which contains a total of 1951 Shelduck datasets, and performed target detection and segmentation annotation with the help of professional annotators. Based on AnYue ShelduckDateset, this paper describes DuckProcessing, an efficient and powerful module for duck identification based on real shelduckfarms. First of all, using the YOLOv8 module designed to divide the mahjong between them, Precision reached 98.10%, Recall reached 96.53% and F1 score reached 0.95 on the test set. Again using the DuckSegmentation segmentation model, DuckSegmentation reached 96.43% mIoU. Finally, the excellent DuckSegmentation was used as the teacher model, and through knowledge distillation, Deeplabv3 r50 was used as the student model, and the final student model achieved 94.49% mIoU on the test set. The method provides a new way of thinking in practical sisal duck smart farming.
Bezier Distillation
Mar 20, 2025
In Rectified Flow, by obtaining the rectified flow several times, the mapping relationship between distributions can be distilled into a neural network, and the target distribution can be directly predicted by the straight lines of the flow. However, during the pairing process of the mapping relationship, a large amount of error accumulation will occur, resulting in a decrease in performance after multiple rectifications. In the field of flow models, knowledge distillation of multi - teacher diffusion models is also a problem worthy of discussion in accelerating sampling. I intend to combine multi - teacher knowledge distillation with Bezier curves to solve the problem of error accumulation. Currently, the related paper is being written by myself.