 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
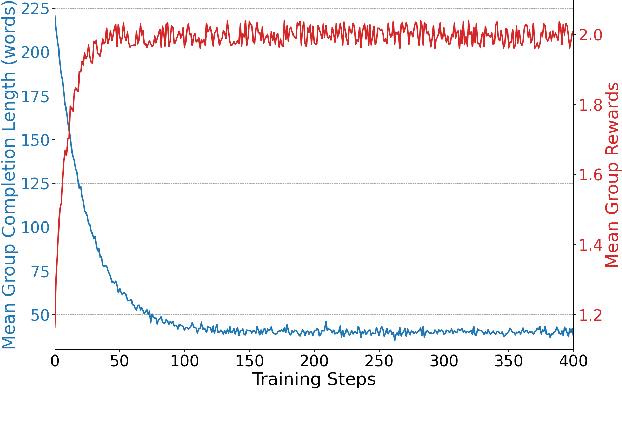
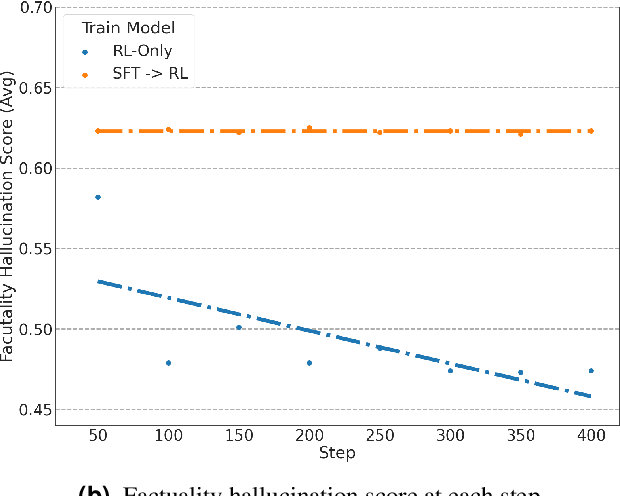
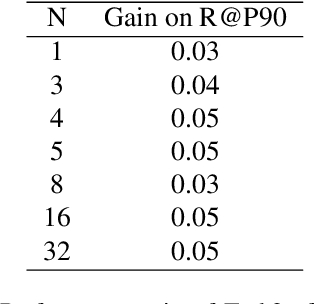
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
Staggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference
Dec 18, 2025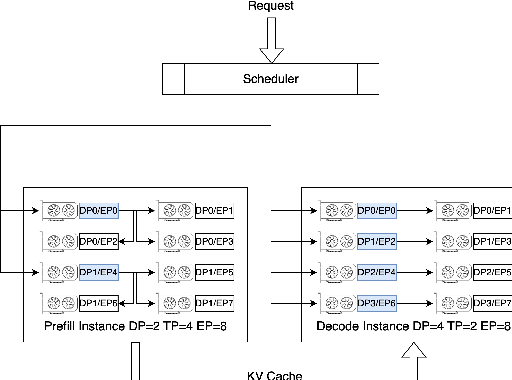
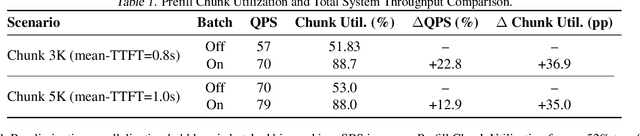
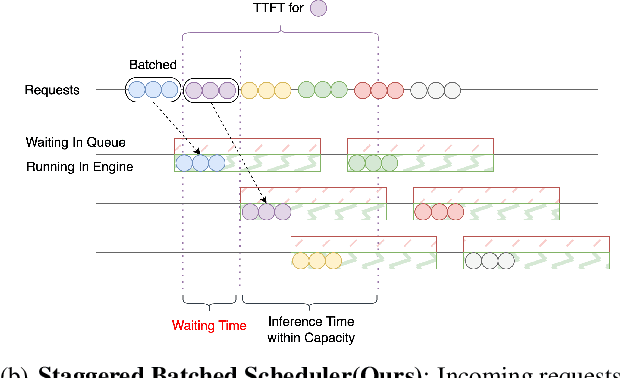
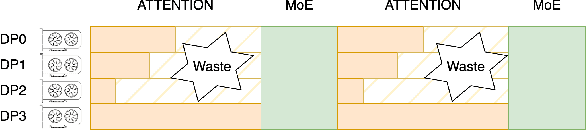
The evolution of Large Language Model (LLM) serving towards complex, distributed architectures--specifically the P/D-separated, large-scale DP+EP paradigm--introduces distinct scheduling challenges. Unlike traditional deployments where schedulers can treat instances as black boxes, DP+EP architectures exhibit high internal synchronization costs. We identify that immediate request dispatching in such systems leads to severe in-engine queuing and parallelization bubbles, degrading Time-to-First-Token (TTFT). To address this, we propose Staggered Batch Scheduling (SBS), a mechanism that deliberately buffers requests to form optimal execution batches. This temporal decoupling eliminates internal queuing bubbles without compromising throughput. Furthermore, leveraging the scheduling window created by buffering, we introduce a Load-Aware Global Allocation strategy that balances computational load across DP units for both Prefill and Decode phases. Deployed on a production H800 cluster serving Deepseek-V3, our system reduces TTFT by 30%-40% and improves throughput by 15%-20% compared to state-of-the-art immediate scheduling baselines.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
TreeRL: LLM Reinforcement Learning with On-Policy Tree Search
Jun 13, 2025Reinforcement learning (RL) with tree search has demonstrated superior performance in traditional reasoning tasks. Compared to conventional independent chain sampling strategies with outcome supervision, tree search enables better exploration of the reasoning space and provides dense, on-policy process rewards during RL training but remains under-explored in On-Policy LLM RL. We propose TreeRL, a reinforcement learning framework that directly incorporates on-policy tree search for RL training. Our approach includes intermediate supervision and eliminates the need for a separate reward model training. Existing approaches typically train a separate process reward model, which can suffer from distribution mismatch and reward hacking. We also introduce a cost-effective tree search approach that achieves higher search efficiency under the same generation token budget by strategically branching from high-uncertainty intermediate steps rather than using random branching. Experiments on challenging math and code reasoning benchmarks demonstrate that TreeRL achieves superior performance compared to traditional ChainRL, highlighting the potential of tree search for LLM. TreeRL is open-sourced at https://github.com/THUDM/TreeRL.
SWE-Dev: Building Software Engineering Agents with Training and Inference Scaling
Jun 09, 2025
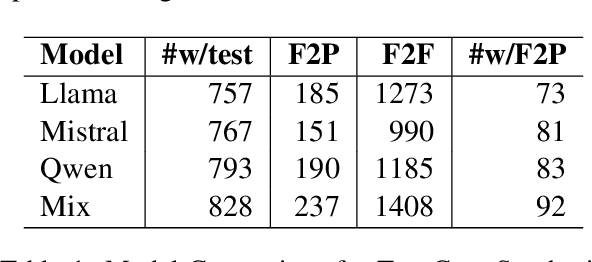
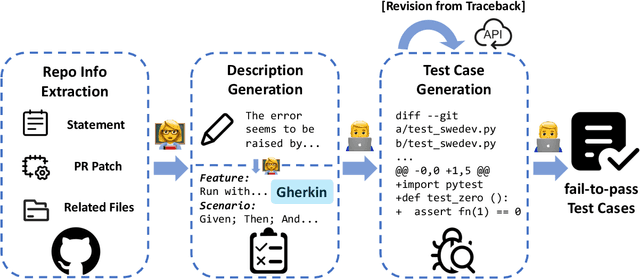

Large language models (LLMs) have advanced rapidly from conversational problem solving to addressing real-world tasks involving tool use, such as software engineering (SWE). Recent LLM-powered toolkits, such as OpenAI Codex and Cursor, have offered end-to-end automation of the software development process. However, building effective SWE agents remains challenging due to the lack of high-quality training data and effective test cases. To address this issue, we present SWE-Dev, an SWE agent built upon open-source LLMs. First, we develop a robust pipeline to synthesize test cases for patch evaluation. Second, we scale up agent trajectories to construct the training data for building SWE-Dev. Experiments on the SWE-bench-Verified benchmark show that the SWE-Dev models can achieve top performance among all open SWE agents. Specifically, the success rates of the SWE-Dev 7B and 32B parameter models reach 23.4% and 36.6%, respectively, outperforming state-of-the-art open-source models. All code, models, and datasets are publicly available at https://github.com/THUDM/SWE-Dev.
Controlling Large Language Model with Latent Actions
Mar 27, 2025Adapting Large Language Models (LLMs) to downstream tasks using Reinforcement Learning (RL) has proven to be an effective approach. However, LLMs do not inherently define the structure of an agent for RL training, particularly in terms of defining the action space. This paper studies learning a compact latent action space to enhance the controllability and exploration of RL for LLMs. We propose Controlling Large Language Models with Latent Actions (CoLA), a framework that integrates a latent action space into pre-trained LLMs. We apply CoLA to the Llama-3.1-8B model. Our experiments demonstrate that, compared to RL with token-level actions, CoLA's latent action enables greater semantic diversity in text generation. For enhancing downstream tasks, we show that CoLA with RL achieves a score of 42.4 on the math500 benchmark, surpassing the baseline score of 38.2, and reaches 68.2 when augmented with a Monte Carlo Tree Search variant. Furthermore, CoLA with RL consistently improves performance on agent-based tasks without degrading the pre-trained LLM's capabilities, unlike the baseline. Finally, CoLA reduces computation time by half in tasks involving enhanced thinking prompts for LLMs by RL. These results highlight CoLA's potential to advance RL-based adaptation of LLMs for downstream applications.
Real-time Spatial-temporal Traversability Assessment via Feature-based Sparse Gaussian Process
Mar 06, 2025Terrain analysis is critical for the practical application of ground mobile robots in real-world tasks, especially in outdoor unstructured environments. In this paper, we propose a novel spatial-temporal traversability assessment method, which aims to enable autonomous robots to effectively navigate through complex terrains. Our approach utilizes sparse Gaussian processes (SGP) to extract geometric features (curvature, gradient, elevation, etc.) directly from point cloud scans. These features are then used to construct a high-resolution local traversability map. Then, we design a spatial-temporal Bayesian Gaussian kernel (BGK) inference method to dynamically evaluate traversability scores, integrating historical and real-time data while considering factors such as slope, flatness, gradient, and uncertainty metrics. GPU acceleration is applied in the feature extraction step, and the system achieves real-time performance. Extensive simulation experiments across diverse terrain scenarios demonstrate that our method outperforms SOTA approaches in both accuracy and computational efficiency. Additionally, we develop an autonomous navigation framework integrated with the traversability map and validate it with a differential driven vehicle in complex outdoor environments. Our code will be open-source for further research and development by the community, https://github.com/ZJU-FAST-Lab/FSGP_BGK.
Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling
Jan 20, 2025



Large language models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks. However, existing approaches mainly rely on imitation learning and struggle to achieve effective test-time scaling. While reinforcement learning (RL) holds promise for enabling self-exploration and learning from feedback, recent attempts yield only modest improvements in complex reasoning. In this paper, we present T1 to scale RL by encouraging exploration and understand inference scaling. We first initialize the LLM using synthesized chain-of-thought data that integrates trial-and-error and self-verification. To scale RL training, we promote increased sampling diversity through oversampling. We further employ an entropy bonus as an auxiliary loss, alongside a dynamic anchor for regularization to facilitate reward optimization. We demonstrate that T1 with open LLMs as its base exhibits inference scaling behavior and achieves superior performance on challenging math reasoning benchmarks. For example, T1 with Qwen2.5-32B as the base model outperforms the recent Qwen QwQ-32B-Preview model on MATH500, AIME2024, and Omni-math-500. More importantly, we present a simple strategy to examine inference scaling, where increased inference budgets directly lead to T1's better performance without any additional verification. We will open-source the T1 models and the data used to train them at \url{https://github.com/THUDM/T1}.
Does RLHF Scale? Exploring the Impacts From Data, Model, and Method
Dec 08, 2024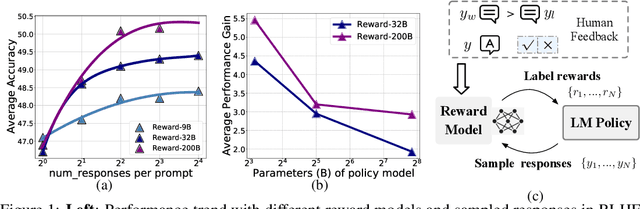
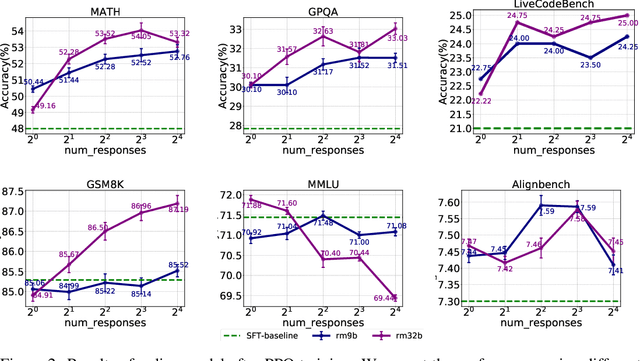
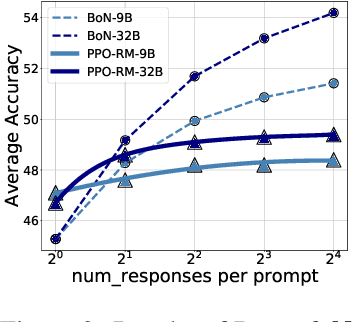
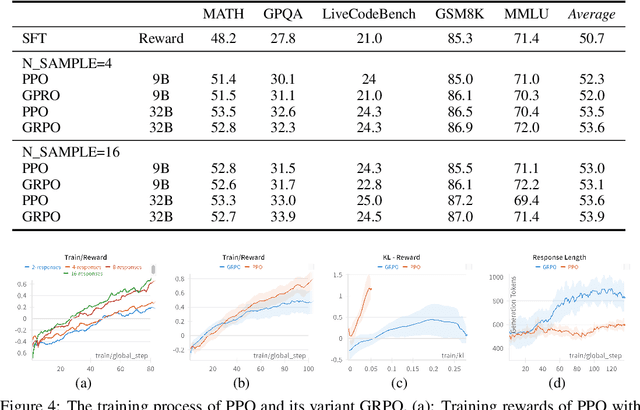
This study explores the scaling properties of Reinforcement Learning from Human Feedback (RLHF) in Large Language Models (LLMs). Although RLHF is considered an important step in post-training of LLMs, its scaling potential is still largely unknown. We systematically analyze key components in the RLHF framework--model size, data composition, and inference budget--and their impacts on performance. Our findings show that increasing data diversity and volume improves reward model performance, helping process-supervision models scale better. For policy training, more response samples per prompt boost performance initially but quickly plateau. And larger reward models offer modest gains in policy training. In addition, larger policy models benefit less from RLHF with a fixed reward model. Overall, RLHF scales less efficiently than pretraining, with diminishing returns from additional computational resources. Based on these observations, we propose strategies to optimize RLHF performance within computational limits.