 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Dialogue Time: Temporal Semantic Memory for Personalized LLM Agents
Jan 12, 2026Memory enables Large Language Model (LLM) agents to perceive, store, and use information from past dialogues, which is essential for personalization. However, existing methods fail to properly model the temporal dimension of memory in two aspects: 1) Temporal inaccuracy: memories are organized by dialogue time rather than their actual occurrence time; 2) Temporal fragmentation: existing methods focus on point-wise memory, losing durative information that captures persistent states and evolving patterns. To address these limitations, we propose Temporal Semantic Memory (TSM), a memory framework that models semantic time for point-wise memory and supports the construction and utilization of durative memory. During memory construction, it first builds a semantic timeline rather than a dialogue one. Then, it consolidates temporally continuous and semantically related information into a durative memory. During memory utilization, it incorporates the query's temporal intent on the semantic timeline, enabling the retrieval of temporally appropriate durative memories and providing time-valid, duration-consistent context to support response generation. Experiments on LongMemEval and LoCoMo show that TSM consistently outperforms existing methods and achieves up to 12.2% absolute improvement in accuracy, demonstrating the effectiveness of the proposed method.
Mixture Policy based Multi-Hop Reasoning over N-tuple Temporal Knowledge Graphs
May 19, 2025Temporal Knowledge Graphs (TKGs), which utilize quadruples in the form of (subject, predicate, object, timestamp) to describe temporal facts, have attracted extensive attention. N-tuple TKGs (N-TKGs) further extend traditional TKGs by utilizing n-tuples to incorporate auxiliary elements alongside core elements (i.e., subject, predicate, and object) of facts, so as to represent them in a more fine-grained manner. Reasoning over N-TKGs aims to predict potential future facts based on historical ones. However, existing N-TKG reasoning methods often lack explainability due to their black-box nature. Therefore, we introduce a new Reinforcement Learning-based method, named MT-Path, which leverages the temporal information to traverse historical n-tuples and construct a temporal reasoning path. Specifically, in order to integrate the information encapsulated within n-tuples, i.e., the entity-irrelevant information within the predicate, the information about core elements, and the complete information about the entire n-tuples, MT-Path utilizes a mixture policy-driven action selector, which bases on three low-level policies, namely, the predicate-focused policy, the core-element-focused policy and the whole-fact-focused policy. Further, MT-Path utilizes an auxiliary element-aware GCN to capture the rich semantic dependencies among facts, thereby enabling the agent to gain a deep understanding of each n-tuple. Experimental results demonstrate the effectiveness and the explainability of MT-Path.
LongReward: Improving Long-context Large Language Models with AI Feedback
Oct 28, 2024Though significant advancements have been achieved in developing long-context large language models (LLMs), the compromised quality of LLM-synthesized data for supervised fine-tuning (SFT) often affects the long-context performance of SFT models and leads to inherent limitations. In principle, reinforcement learning (RL) with appropriate reward signals can further enhance models' capacities. However, how to obtain reliable rewards in long-context scenarios remains unexplored. To this end, we propose LongReward, a novel method that utilizes an off-the-shelf LLM to provide rewards for long-context model responses from four human-valued dimensions: helpfulness, logicality, faithfulness, and completeness, each with a carefully designed assessment pipeline. By combining LongReward and offline RL algorithm DPO, we are able to effectively improve long-context SFT models. Our experiments indicate that LongReward not only significantly improves models' long-context performance but also enhances their ability to follow short instructions. We also find that long-context DPO with LongReward and conventional short-context DPO can be used together without hurting either one's performance.
Selective Temporal Knowledge Graph Reasoning
Apr 02, 2024



Temporal Knowledge Graph (TKG), which characterizes temporally evolving facts in the form of (subject, relation, object, timestamp), has attracted much attention recently. TKG reasoning aims to predict future facts based on given historical ones. However, existing TKG reasoning models are unable to abstain from predictions they are uncertain, which will inevitably bring risks in real-world applications. Thus, in this paper, we propose an abstention mechanism for TKG reasoning, which helps the existing models make selective, instead of indiscriminate, predictions. Specifically, we develop a confidence estimator, called Confidence Estimator with History (CEHis), to enable the existing TKG reasoning models to first estimate their confidence in making predictions, and then abstain from those with low confidence. To do so, CEHis takes two kinds of information into consideration, namely, the certainty of the current prediction and the accuracy of historical predictions. Experiments with representative TKG reasoning models on two benchmark datasets demonstrate the effectiveness of the proposed CEHis.
HiSMatch: Historical Structure Matching based Temporal Knowledge Graph Reasoning
Oct 18, 2022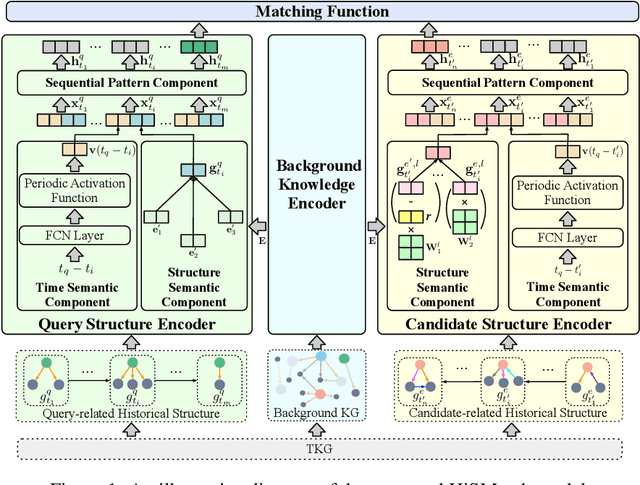
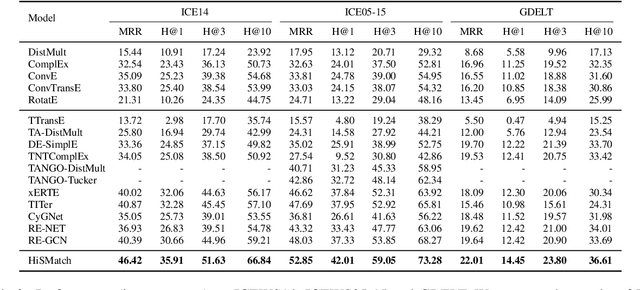
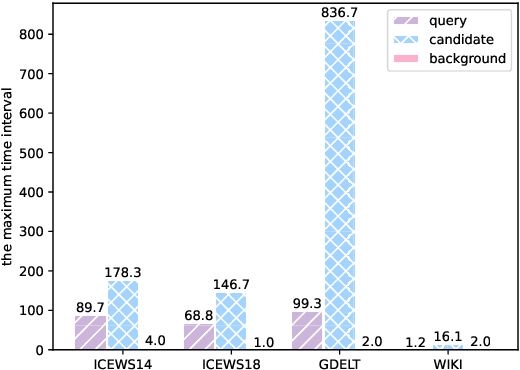
A Temporal Knowledge Graph (TKG) is a sequence of KGs with respective timestamps, which adopts quadruples in the form of (\emph{subject}, \emph{relation}, \emph{object}, \emph{timestamp}) to describe dynamic facts. TKG reasoning has facilitated many real-world applications via answering such queries as (\emph{query entity}, \emph{query relation}, \emph{?}, \emph{future timestamp}) about future. This is actually a matching task between a query and candidate entities based on their historical structures, which reflect behavioral trends of the entities at different timestamps. In addition, recent KGs provide background knowledge of all the entities, which is also helpful for the matching. Thus, in this paper, we propose the \textbf{Hi}storical \textbf{S}tructure \textbf{Match}ing (\textbf{HiSMatch}) model. It applies two structure encoders to capture the semantic information contained in the historical structures of the query and candidate entities. Besides, it adopts another encoder to integrate the background knowledge into the model. TKG reasoning experiments on six benchmark datasets demonstrate the significant improvement of the proposed HiSMatch model, with up to 5.6\% performance improvement in MRR, compared to the state-of-the-art baselines.