 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trustworthy Multimodal Recommendation
Jan 31, 2026Recent advances in multimodal recommendation have demonstrated the effectiveness of incorporating visual and textual content into collaborative filtering. However, real-world deployments raise an increasingly important yet underexplored issue: trustworthiness. On modern e-commerce platforms, multimodal content can be misleading or unreliable (e.g., visually inconsistent product images or click-bait titles), injecting untrustworthy signals into multimodal representations and making existing recommenders brittle under modality corruption. In this work, we take a step towards trustworthy multimodal recommendation from both a method and an analysis perspective. First, we propose a plug-and-play modality-level rectification component that mitigates untrustworthy modality features by learning soft correspondences between items and multimodal features. Using lightweight projections and Sinkhorn-based soft matching, the rectification suppresses mismatched modality signals while preserving semantic consistency, and can be integrated into existing multimodal recommenders without architectural modifications. Second, we present two practical insights on interaction-level trustworthiness under noisy collaborative signals: (i) training-set pseudo interactions can help or hurt performance under noise depending on prior-signal alignment; and (ii) propagation-graph pseudo edges can also help or hurt robustness, as message passing may amplify misalignment. Extensive experiments on multiple datasets and backbones under varying corruption levels demonstrate improved robustness from modality rectification and validate the above interaction-level observations.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Beyond Dialogue Time: Temporal Semantic Memory for Personalized LLM Agents
Jan 12, 2026Memory enables Large Language Model (LLM) agents to perceive, store, and use information from past dialogues, which is essential for personalization. However, existing methods fail to properly model the temporal dimension of memory in two aspects: 1) Temporal inaccuracy: memories are organized by dialogue time rather than their actual occurrence time; 2) Temporal fragmentation: existing methods focus on point-wise memory, losing durative information that captures persistent states and evolving patterns. To address these limitations, we propose Temporal Semantic Memory (TSM), a memory framework that models semantic time for point-wise memory and supports the construction and utilization of durative memory. During memory construction, it first builds a semantic timeline rather than a dialogue one. Then, it consolidates temporally continuous and semantically related information into a durative memory. During memory utilization, it incorporates the query's temporal intent on the semantic timeline, enabling the retrieval of temporally appropriate durative memories and providing time-valid, duration-consistent context to support response generation. Experiments on LongMemEval and LoCoMo show that TSM consistently outperforms existing methods and achieves up to 12.2% absolute improvement in accuracy, demonstrating the effectiveness of the proposed method.
LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction
Sep 09, 2025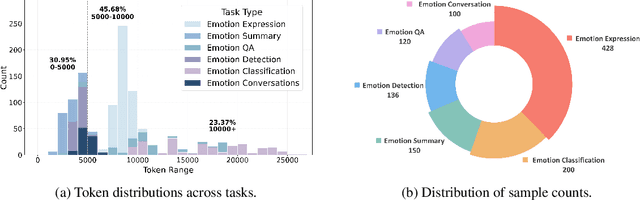

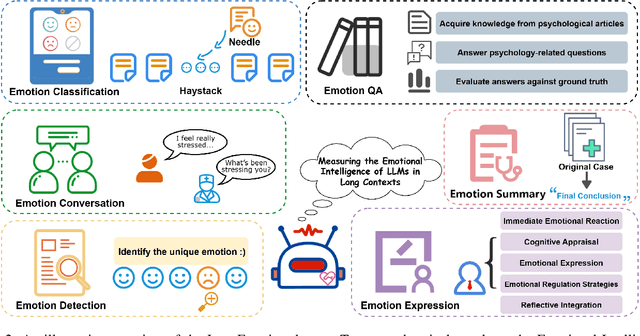
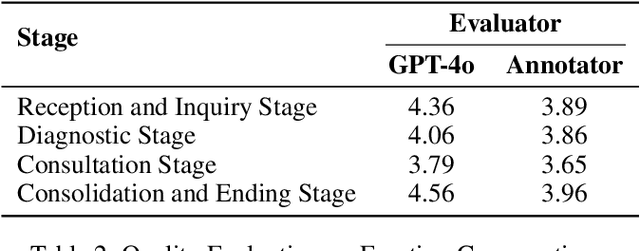
Large language models (LLMs) make significant progress in Emotional Intelligence (EI) and long-context understanding. However, existing benchmarks tend to overlook certain aspects of EI in long-context scenarios, especially under realistic, practical settings where interactions are lengthy, diverse, and often noisy. To move towards such realistic settings, we present LongEmotion, a benchmark specifically designed for long-context EI tasks. It covers a diverse set of tasks, including Emotion Classification, Emotion Detection, Emotion QA, Emotion Conversation, Emotion Summary, and Emotion Expression. On average, the input length for these tasks reaches 8,777 tokens, with long-form generation required for Emotion Expression. To enhance performance under realistic constraints, we incorporate Retrieval-Augmented Generation (RAG) and Collaborative Emotional Modeling (CoEM), and compare them with standard prompt-based methods. Unlike conventional approaches, our RAG method leverages both the conversation context and the large language model itself as retrieval sources, avoiding reliance on external knowledge bases. The CoEM method further improves performance by decomposing the task into five stages, integrating both retrieval augmentation and limited knowledge injection. Experimental results show that both RAG and CoEM consistently enhance EI-related performance across most long-context tasks, advancing LLMs toward more practical and real-world EI applications. Furthermore, we conducted a comparative case study experiment on the GPT series to demonstrate the differences among various models in terms of EI. Code is available on GitHub at https://github.com/LongEmotion/LongEmotion, and the project page can be found at https://longemotion.github.io/.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
KnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025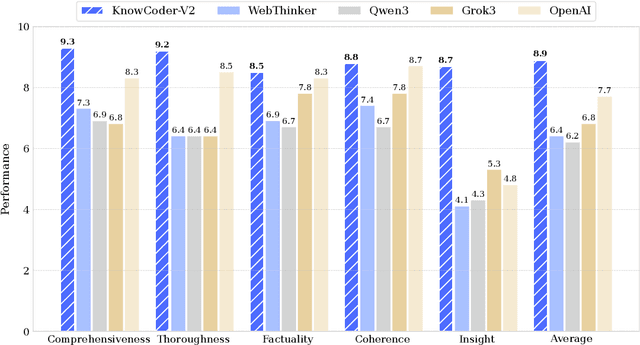
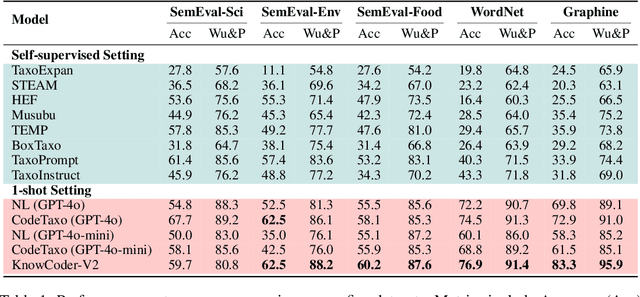
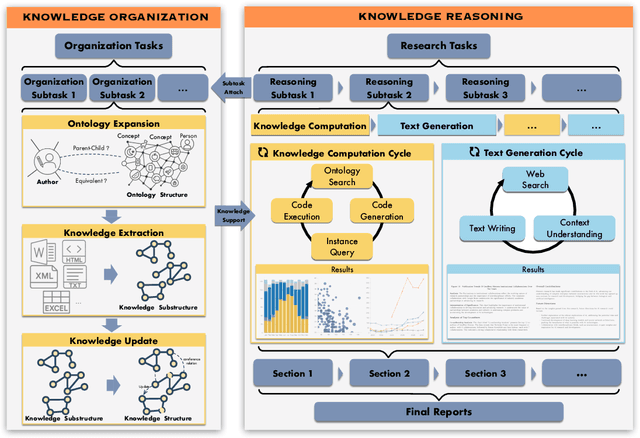
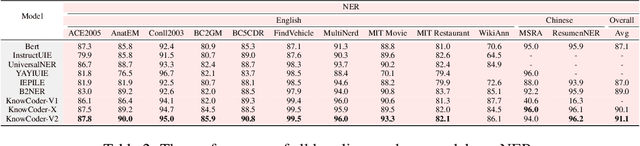
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.
Two-stage Audio-Visual Target Speaker Extraction System for Real-Time Processing On Edge Device
May 28, 2025Audio-Visual Target Speaker Extraction (AVTSE) aims to isolate a target speaker's voice in a multi-speaker environment with visual cues as auxiliary. Most of the existing AVTSE methods encode visual and audio features simultaneously, resulting in extremely high computational complexity and making it impractical for real-time processing on edge devices. To tackle this issue, we proposed a two-stage ultra-compact AVTSE system. Specifically, in the first stage, a compact network is employed for voice activity detection (VAD) using visual information. In the second stage, the VAD results are combined with audio inputs to isolate the target speaker's voice. Experiments show that the proposed system effectively suppresses background noise and interfering voices while spending little computational resources.
Mixture Policy based Multi-Hop Reasoning over N-tuple Temporal Knowledge Graphs
May 19, 2025Temporal Knowledge Graphs (TKGs), which utilize quadruples in the form of (subject, predicate, object, timestamp) to describe temporal facts, have attracted extensive attention. N-tuple TKGs (N-TKGs) further extend traditional TKGs by utilizing n-tuples to incorporate auxiliary elements alongside core elements (i.e., subject, predicate, and object) of facts, so as to represent them in a more fine-grained manner. Reasoning over N-TKGs aims to predict potential future facts based on historical ones. However, existing N-TKG reasoning methods often lack explainability due to their black-box nature. Therefore, we introduce a new Reinforcement Learning-based method, named MT-Path, which leverages the temporal information to traverse historical n-tuples and construct a temporal reasoning path. Specifically, in order to integrate the information encapsulated within n-tuples, i.e., the entity-irrelevant information within the predicate, the information about core elements, and the complete information about the entire n-tuples, MT-Path utilizes a mixture policy-driven action selector, which bases on three low-level policies, namely, the predicate-focused policy, the core-element-focused policy and the whole-fact-focused policy. Further, MT-Path utilizes an auxiliary element-aware GCN to capture the rich semantic dependencies among facts, thereby enabling the agent to gain a deep understanding of each n-tuple. Experimental results demonstrate the effectiveness and the explainability of MT-Path.
Empowering Vision Transformers with Multi-Scale Causal Intervention for Long-Tailed Image Classification
May 13, 2025Causal inference has emerged as a promising approach to mitigate long-tail classification by handling the biases introduced by class imbalance. However, along with the change of advanced backbone models from Convolutional Neural Networks (CNNs) to Visual Transformers (ViT), existing causal models may not achieve an expected performance gain. This paper investigates the influence of existing causal models on CNNs and ViT variants, highlighting that ViT's global feature representation makes it hard for causal methods to model associations between fine-grained features and predictions, which leads to difficulties in classifying tail classes with similar visual appearance. To address these issues, this paper proposes TSCNet, a two-stage causal modeling method to discover fine-grained causal associations through multi-scale causal interventions. Specifically, in the hierarchical causal representation learning stage (HCRL), it decouples the background and objects, applying backdoor interventions at both the patch and feature level to prevent model from using class-irrelevant areas to infer labels which enhances fine-grained causal representation. In the counterfactual logits bias calibration stage (CLBC), it refines the optimization of model's decision boundary by adaptive constructing counterfactual balanced data distribution to remove the spurious associations in the logits caused by data distribution. Extensive experiments conducted on various long-tail benchmarks demonstrate that the proposed TSCNet can eliminate multiple biases introduced by data imbalance, which outperforms existing methods.
Semantic-Space-Intervened Diffusive Alignment for Visual Classification
May 09, 2025Cross-modal alignment is an effective approach to improving visual classification. Existing studies typically enforce a one-step mapping that uses deep neural networks to project the visual features to mimic the distribution of textual features. However, they typically face difficulties in finding such a projection due to the two modalities in both the distribution of class-wise samples and the range of their feature values. To address this issue, this paper proposes a novel Semantic-Space-Intervened Diffusive Alignment method, termed SeDA, models a semantic space as a bridge in the visual-to-textual projection, considering both types of features share the same class-level information in classification. More importantly, a bi-stage diffusion framework is developed to enable the progressive alignment between the two modalities. Specifically, SeDA first employs a Diffusion-Controlled Semantic Learner to model the semantic features space of visual features by constraining the interactive features of the diffusion model and the category centers of visual features. In the later stage of SeDA, the Diffusion-Controlled Semantic Translator focuses on learning the distribution of textual features from the semantic space. Meanwhile, the Progressive Feature Interaction Network introduces stepwise feature interactions at each alignment step, progressively integrating textual information into mapped features. Experimental results show that SeDA achieves stronger cross-modal feature alignment, leading to superior performance over existing methods across multiple scenarios.