 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
CLaSp: In-Context Layer Skip for Self-Speculative Decoding
May 30, 2025Speculative decoding (SD) is a promising method for accelerating the decoding process of Large Language Models (LLMs). The efficiency of SD primarily hinges on the consistency between the draft model and the verify model. However, existing drafting approaches typically require additional modules to be trained, which can be challenging to implement and ensure compatibility across various LLMs. In this paper, we propose CLaSp, an in-context layer-skipping strategy for self-speculative decoding. Unlike prior methods, CLaSp does not require additional drafting modules or extra training. Instead, it employs a plug-and-play mechanism by skipping intermediate layers of the verify model to construct a compressed draft model. Specifically, we develop a dynamic programming algorithm that optimizes the layer-skipping process by leveraging the complete hidden states from the last verification stage as an objective. This enables CLaSp to dynamically adjust its layer-skipping strategy after each verification stage, without relying on pre-optimized sets of skipped layers. Experimental results across diverse downstream tasks demonstrate that CLaSp achieves a speedup of 1.3x ~ 1.7x on LLaMA3 series models without altering the original distribution of the generated text.
VCM: Vision Concept Modeling Based on Implicit Contrastive Learning with Vision-Language Instruction Fine-Tuning
Apr 28, 2025Large Vision-Language Models (LVLMs) are pivotal for real-world AI tasks like embodied intelligence due to their strong vision-language reasoning abilities. However, current LVLMs process entire images at the token level, which is inefficient compared to humans who analyze information and generate content at the conceptual level, extracting relevant visual concepts with minimal effort. This inefficiency, stemming from the lack of a visual concept model, limits LVLMs' usability in real-world applications. To address this, we propose VCM, an end-to-end self-supervised visual concept modeling framework. VCM leverages implicit contrastive learning across multiple sampled instances and vision-language fine-tuning to construct a visual concept model without requiring costly concept-level annotations. Our results show that VCM significantly reduces computational costs (e.g., 85\% fewer FLOPs for LLaVA-1.5-7B) while maintaining strong performance across diverse image understanding tasks. Moreover, VCM enhances visual encoders' capabilities in classic visual concept perception tasks. Extensive quantitative and qualitative experiments validate the effectiveness and efficiency of VCM.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

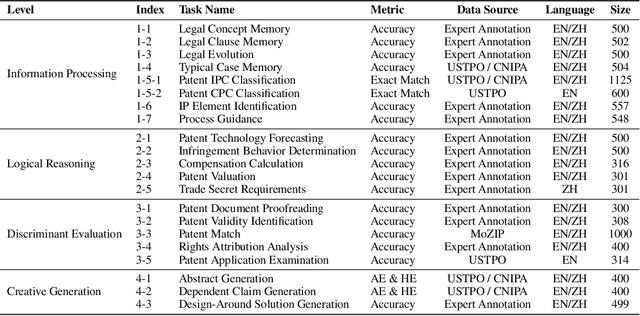
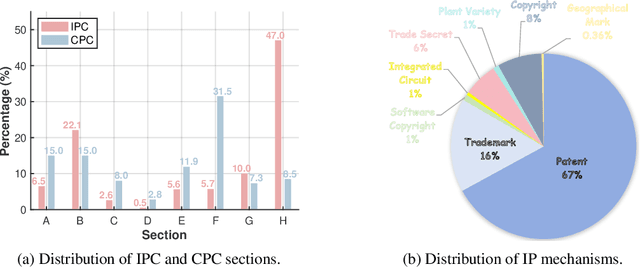
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
Can MLLMs Understand the Deep Implication Behind Chinese Images?
Oct 17, 2024
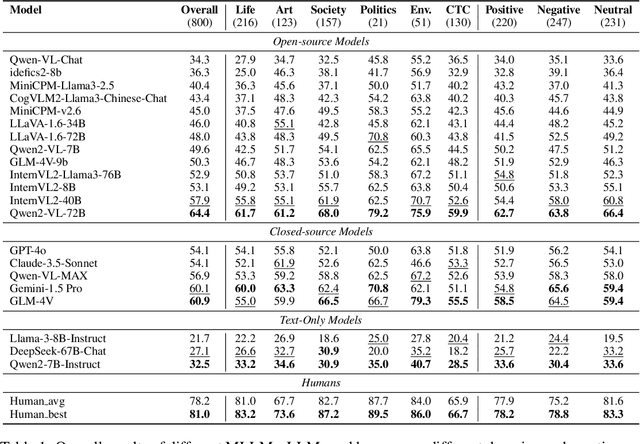
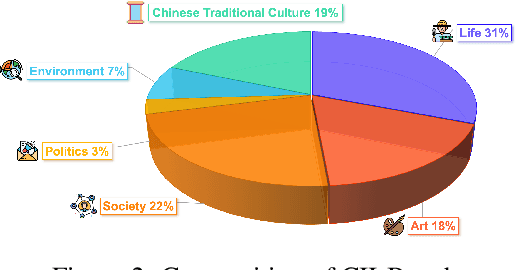
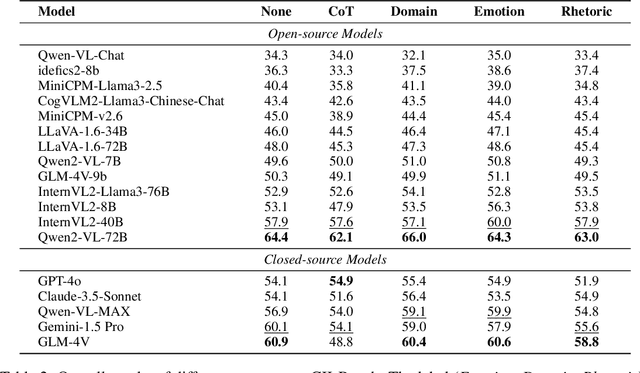
As the capabilities of Multimodal Large Language Models (MLLMs) continue to improve, the need for higher-order capability evaluation of MLLMs is increasing. However, there is a lack of work evaluating MLLM for higher-order perception and understanding of Chinese visual content. To fill the gap, we introduce the **C**hinese **I**mage **I**mplication understanding **Bench**mark, **CII-Bench**, which aims to assess the higher-order perception and understanding capabilities of MLLMs for Chinese images. CII-Bench stands out in several ways compared to existing benchmarks. Firstly, to ensure the authenticity of the Chinese context, images in CII-Bench are sourced from the Chinese Internet and manually reviewed, with corresponding answers also manually crafted. Additionally, CII-Bench incorporates images that represent Chinese traditional culture, such as famous Chinese traditional paintings, which can deeply reflect the model's understanding of Chinese traditional culture. Through extensive experiments on CII-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on CII-Bench. The highest accuracy of MLLMs attains 64.4%, where as human accuracy averages 78.2%, peaking at an impressive 81.0%. Subsequently, MLLMs perform worse on Chinese traditional culture images, suggesting limitations in their ability to understand high-level semantics and lack a deep knowledge base of Chinese traditional culture. Finally, it is observed that most models exhibit enhanced accuracy when image emotion hints are incorporated into the prompts. We believe that CII-Bench will enable MLLMs to gain a better understanding of Chinese semantics and Chinese-specific images, advancing the journey towards expert artificial general intelligence (AGI). Our project is publicly available at https://cii-bench.github.io/.
Ruler: A Model-Agnostic Method to Control Generated Length for Large Language Models
Sep 27, 2024



The instruction-following ability of large language models enables humans to interact with AI agents in a natural way. However, when required to generate responses of a specific length, large language models often struggle to meet users' needs due to their inherent difficulty in accurately perceiving numerical constraints. To explore the ability of large language models to control the length of generated responses, we propose the Target Length Generation Task (TLG) and design two metrics, Precise Match (PM) and Flexible Match (FM) to evaluate the model's performance in adhering to specified response lengths. Furthermore, we introduce a novel, model-agnostic approach called Ruler, which employs Meta Length Tokens (MLTs) to enhance the instruction-following ability of large language models under length-constrained instructions. Specifically, Ruler equips LLMs with the ability to generate responses of a specified length based on length constraints within the instructions. Moreover, Ruler can automatically generate appropriate MLT when length constraints are not explicitly provided, demonstrating excellent versatility and generalization. Comprehensive experiments show the effectiveness of Ruler across different LLMs on Target Length Generation Task, e.g., at All Level 27.97 average gain on PM, 29.57 average gain on FM. In addition, we conduct extensive ablation experiments to further substantiate the efficacy and generalization of Ruler. Our code and data is available at https://github.com/Geaming2002/Ruler.
AgentCourt: Simulating Court with Adversarial Evolvable Lawyer Agents
Aug 15, 2024



In this paper, we present a simulation system called AgentCourt that simulates the entire courtroom process. The judge, plaintiff's lawyer, defense lawyer, and other participants are autonomous agents driven by large language models (LLMs). Our core goal is to enable lawyer agents to learn how to argue a case, as well as improving their overall legal skills, through courtroom process simulation. To achieve this goal, we propose an adversarial evolutionary approach for the lawyer-agent. Since AgentCourt can simulate the occurrence and development of court hearings based on a knowledge base and LLM, the lawyer agents can continuously learn and accumulate experience from real court cases. The simulation experiments show that after two lawyer-agents have engaged in a thousand adversarial legal cases in AgentCourt (which can take a decade for real-world lawyers), compared to their pre-evolutionary state, the evolved lawyer agents exhibit consistent improvement in their ability to handle legal tasks. To enhance the credibility of our experimental results, we enlisted a panel of professional lawyers to evaluate our simulations. The evaluation indicates that the evolved lawyer agents exhibit notable advancements in responsiveness, as well as expertise and logical rigor. This work paves the way for advancing LLM-driven agent technology in legal scenarios. Code is available at https://github.com/relic-yuexi/AgentCourt.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
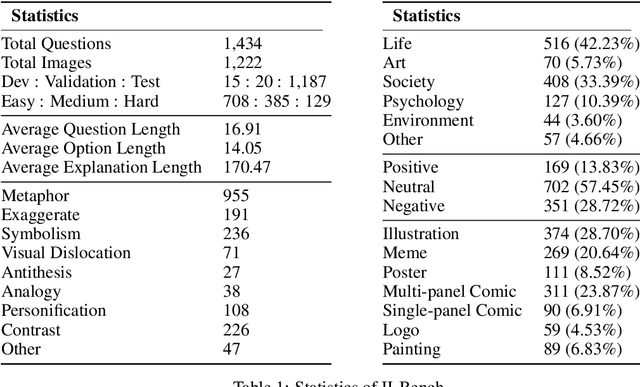
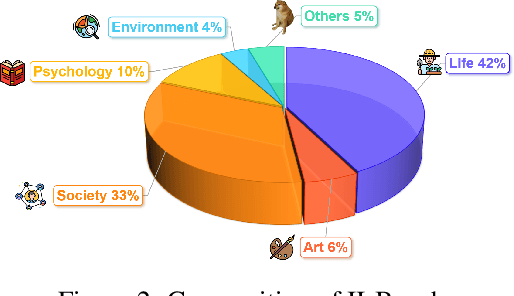
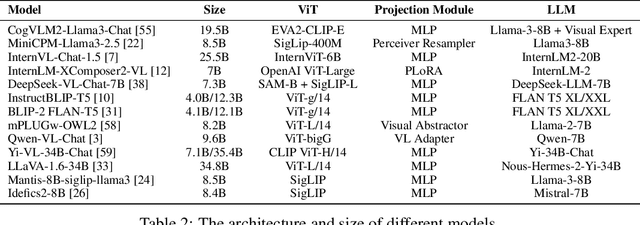
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
Long Context is Not Long at All: A Prospector of Long-Dependency Data for Large Language Models
May 28, 2024Long-context modeling capabilities are important for large language models (LLMs) in various applications. However, directly training LLMs with long context windows is insufficient to enhance this capability since some training samples do not exhibit strong semantic dependencies across long contexts. In this study, we propose a data mining framework \textbf{ProLong} that can assign each training sample with a long dependency score, which can be used to rank and filter samples that are more advantageous for enhancing long-context modeling abilities in LLM training. Specifically, we first use delta perplexity scores to measure the \textit{Dependency Strength} between text segments in a given document. Then we refine this metric based on the \textit{Dependency Distance} of these segments to incorporate spatial relationships across long-contexts. Final results are calibrated with a \textit{Dependency Specificity} metric to prevent trivial dependencies introduced by repetitive patterns. Moreover, a random sampling approach is proposed to optimize the computational efficiency of ProLong. Comprehensive experiments on multiple benchmarks indicate that ProLong effectively identifies documents that carry long dependencies and LLMs trained on these documents exhibit significantly enhanced long-context modeling capabilities.
DEEM: Diffusion Models Serve as the Eyes of Large Language Models for Image Perception
May 24, 2024



The development of large language models (LLMs) has significantly advanced the emergence of large multimodal models (LMMs). While LMMs have achieved tremendous success by promoting the synergy between multimodal comprehension and creation, they often face challenges when confronted with out-of-distribution data. This is primarily due to their reliance on image encoders trained to encode images into task-relevant features, which may lead them to disregard irrelevant details. Delving into the modeling capabilities of diffusion models for images naturally prompts the question: Can diffusion models serve as the eyes of large language models for image perception? In this paper, we propose DEEM, a simple and effective approach that utilizes the generative feedback of diffusion models to align the semantic distributions of the image encoder. This addresses the drawbacks of previous methods that solely relied on image encoders like ViT, thereby enhancing the model's resilience against out-of-distribution samples and reducing visual hallucinations. Importantly, this is achieved without requiring additional training modules and with fewer training parameters. We extensively evaluated DEEM on both our newly constructed RobustVQA benchmark and another well-known benchmark, POPE, for object hallucination. Compared to the state-of-the-art interleaved content generation models, DEEM exhibits enhanced robustness and a superior capacity to alleviate model hallucinations while utilizing fewer trainable parameters, less pre-training data (10%), and a smaller base model size.