 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Paper and Code
Mar 26, 2024
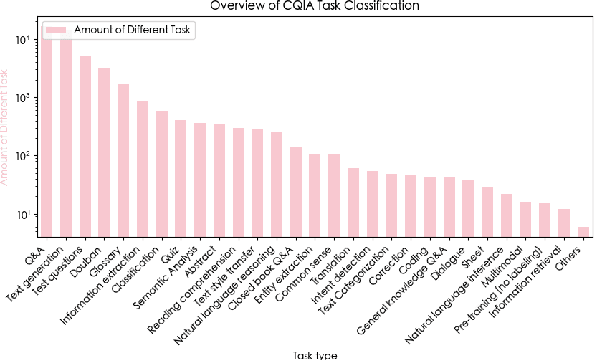

Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA