 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicalized Constituency Parsing for Middle Dutch: Low-resource Training and Cross-Domain Generalization
Jan 11, 2026Recent years have seen growing interest in applying neural networks and contextualized word embeddings to the parsing of historical languages. However, most advances have focused on dependency parsing, while constituency parsing for low-resource historical languages like Middle Dutch has received little attention. In this paper, we adapt a transformer-based constituency parser to Middle Dutch, a highly heterogeneous and low-resource language, and investigate methods to improve both its in-domain and cross-domain performance. We show that joint training with higher-resource auxiliary languages increases F1 scores by up to 0.73, with the greatest gains achieved from languages that are geographically and temporally closer to Middle Dutch. We further evaluate strategies for leveraging newly annotated data from additional domains, finding that fine-tuning and data combination yield comparable improvements, and our neural parser consistently outperforms the currently used PCFG-based parser for Middle Dutch. We further explore feature-separation techniques for domain adaptation and demonstrate that a minimum threshold of approximately 200 examples per domain is needed to effectively enhance cross-domain performance.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
HiMoR: Monocular Deformable Gaussian Reconstruction with Hierarchical Motion Representation
Apr 08, 2025We present Hierarchical Motion Representation (HiMoR), a novel deformation representation for 3D Gaussian primitives capable of achieving high-quality monocular dynamic 3D reconstruction. The insight behind HiMoR is that motions in everyday scenes can be decomposed into coarser motions that serve as the foundation for finer details. Using a tree structure, HiMoR's nodes represent different levels of motion detail, with shallower nodes modeling coarse motion for temporal smoothness and deeper nodes capturing finer motion. Additionally, our model uses a few shared motion bases to represent motions of different sets of nodes, aligning with the assumption that motion tends to be smooth and simple. This motion representation design provides Gaussians with a more structured deformation, maximizing the use of temporal relationships to tackle the challenging task of monocular dynamic 3D reconstruction. We also propose using a more reliable perceptual metric as an alternative, given that pixel-level metrics for evaluating monocular dynamic 3D reconstruction can sometimes fail to accurately reflect the true quality of reconstruction. Extensive experiments demonstrate our method's efficacy in achieving superior novel view synthesis from challenging monocular videos with complex motions.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Keeping Representation Similarity in Finetuning for Medical Image Analysis
Mar 10, 2025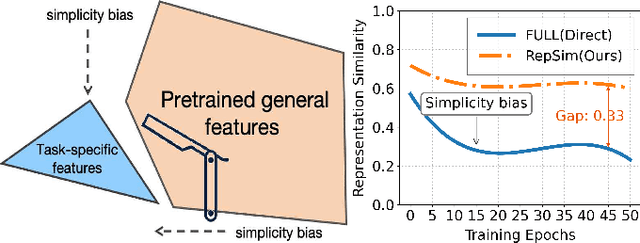
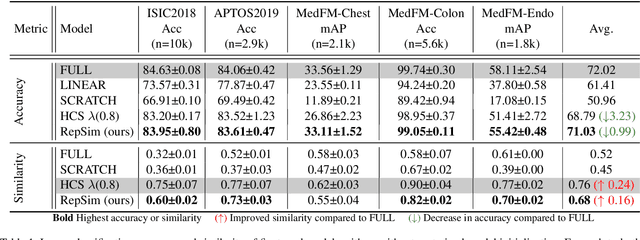
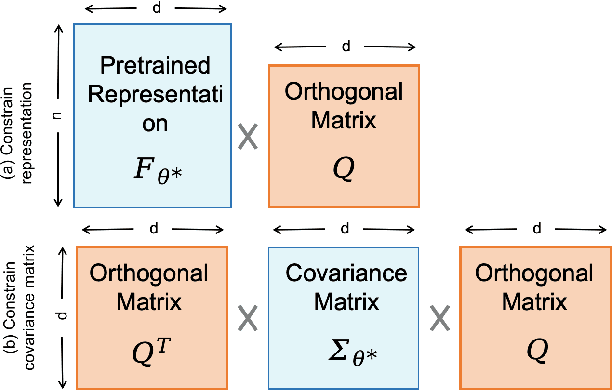
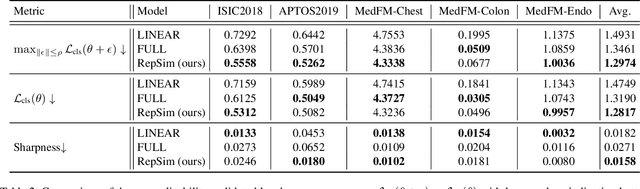
Foundation models pretrained on large-scale natural images have been widely used to adapt to medical image analysis through finetuning. This is largely attributed to pretrained representations capturing universal, robust, and generalizable features, which can be reutilized by downstream tasks. However, these representations are later found to gradually vanish during finetuning, accompanied by a degradation of foundation model's original abilities, e.g., generalizability. In this paper, we argue that pretrained representations can be well preserved while still effectively adapting to downstream tasks. We study this by proposing a new finetuning method RepSim, which minimizes the distance between pretrained and finetuned representations via constraining learnable orthogonal manifold based on similarity invariance. Compared to standard finetuning methods, e.g., full finetuning, our method improves representation similarity by over 30% while maintaining competitive accuracy, and reduces sharpness by 42% across five medical image classification datasets. The code will be released.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
EfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Feb 10, 2025Modern large language models (LLMs) driven by scaling laws, achieve intelligence emergency in large model sizes. Recently, the increasing concerns about cloud costs, latency, and privacy make it an urgent requirement to develop compact edge language models. Distinguished from direct pretraining that bounded by the scaling law, this work proposes the pruning-aware pretraining, focusing on retaining performance of much larger optimized models. It features following characteristics: 1) Data-scalable: we introduce minimal parameter groups in LLM and continuously optimize structural pruning, extending post-training pruning methods like LLM-Pruner and SparseGPT into the pretraining phase. 2) Architecture-agnostic: the LLM architecture is auto-designed using saliency-driven pruning, which is the first time to exceed SoTA human-designed LLMs in modern pretraining. We reveal that it achieves top-quality edge language models, termed EfficientLLM, by scaling up LLM compression and extending its boundary. EfficientLLM significantly outperforms SoTA baselines with $100M \sim 1B$ parameters, such as MobileLLM, SmolLM, Qwen2.5-0.5B, OLMo-1B, Llama3.2-1B in common sense benchmarks. As the first attempt, EfficientLLM bridges the performance gap between traditional LLM compression and direct pretraining methods, and we will fully open source at https://github.com/Xingrun-Xing2/EfficientLLM.