 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Feb 10, 2025Modern large language models (LLMs) driven by scaling laws, achieve intelligence emergency in large model sizes. Recently, the increasing concerns about cloud costs, latency, and privacy make it an urgent requirement to develop compact edge language models. Distinguished from direct pretraining that bounded by the scaling law, this work proposes the pruning-aware pretraining, focusing on retaining performance of much larger optimized models. It features following characteristics: 1) Data-scalable: we introduce minimal parameter groups in LLM and continuously optimize structural pruning, extending post-training pruning methods like LLM-Pruner and SparseGPT into the pretraining phase. 2) Architecture-agnostic: the LLM architecture is auto-designed using saliency-driven pruning, which is the first time to exceed SoTA human-designed LLMs in modern pretraining. We reveal that it achieves top-quality edge language models, termed EfficientLLM, by scaling up LLM compression and extending its boundary. EfficientLLM significantly outperforms SoTA baselines with $100M \sim 1B$ parameters, such as MobileLLM, SmolLM, Qwen2.5-0.5B, OLMo-1B, Llama3.2-1B in common sense benchmarks. As the first attempt, EfficientLLM bridges the performance gap between traditional LLM compression and direct pretraining methods, and we will fully open source at https://github.com/Xingrun-Xing2/EfficientLLM.
VideoOrion: Tokenizing Object Dynamics in Videos
Nov 25, 2024We present VideoOrion, a Video Large Language Model (Video-LLM) that explicitly captures the key semantic information in videos--the spatial-temporal dynamics of objects throughout the videos. VideoOrion employs expert vision models to extract object dynamics through a detect-segment-track pipeline, encoding them into a set of object tokens by aggregating spatial-temporal object features. Our method addresses the persistent challenge in Video-LLMs of efficiently compressing high-dimensional video data into semantic tokens that are comprehensible to LLMs. Compared to prior methods which resort to downsampling the original video or aggregating visual tokens using resamplers, leading to information loss and entangled semantics, VideoOrion not only offers a more natural and efficient way to derive compact, disentangled semantic representations but also enables explicit object modeling of video content with minimal computational cost. Moreover, the introduced object tokens naturally allow VideoOrion to accomplish video-based referring tasks. Experimental results show that VideoOrion can learn to make good use of the object tokens, and achieves competitive results on both general video question answering and video-based referring benchmarks.
From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
Oct 03, 2024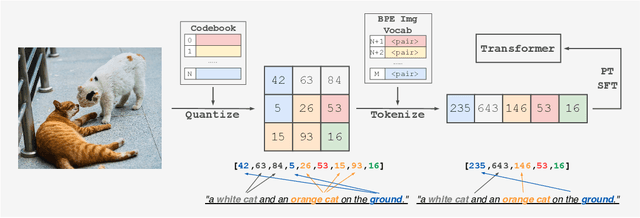
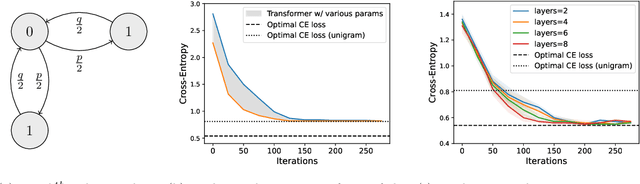
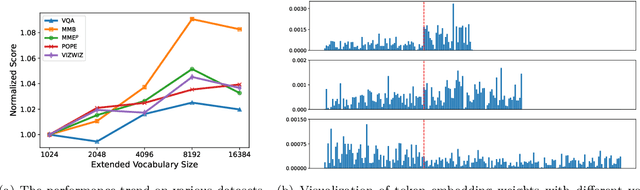
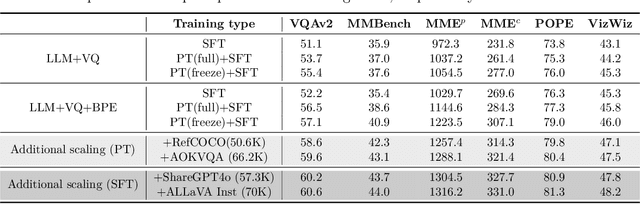
Multimodal Large Language Models have made significant strides in integrating visual and textual information, yet they often struggle with effectively aligning these modalities. We introduce a novel image tokenizer that bridges this gap by applying the principle of Byte-Pair Encoding (BPE) to visual data. Unlike conventional approaches that rely on separate visual encoders, our method directly incorporates structural prior information into image tokens, mirroring the successful tokenization strategies used in text-only Large Language Models. This innovative approach enables Transformer models to more effectively learn and reason across modalities. Through theoretical analysis and extensive experiments, we demonstrate that our BPE Image Tokenizer significantly enhances MLLMs' multimodal understanding capabilities, even with limited training data. Our method not only improves performance across various benchmarks but also shows promising scalability, potentially paving the way for more efficient and capable multimodal foundation models.
RLAdapter: Bridging Large Language Models to Reinforcement Learning in Open Worlds
Sep 29, 2023While reinforcement learning (RL) shows remarkable success in decision-making problems, it often requires a lot of interactions with the environment, and in sparse-reward environments, it is challenging to learn meaningful policies. Large Language Models (LLMs) can potentially provide valuable guidance to agents in learning policies, thereby enhancing the performance of RL algorithms in such environments. However, LLMs often encounter difficulties in understanding downstream tasks, which hinders their ability to optimally assist agents in these tasks. A common approach to mitigating this issue is to fine-tune the LLMs with task-related data, enabling them to offer useful guidance for RL agents. However, this approach encounters several difficulties, such as inaccessible model weights or the need for significant computational resources, making it impractical. In this work, we introduce RLAdapter, a framework that builds a better connection between RL algorithms and LLMs by incorporating an adapter model. Within the RLAdapter framework, fine-tuning a lightweight language model with information generated during the training process of RL agents significantly aids LLMs in adapting to downstream tasks, thereby providing better guidance for RL agents. We conducted experiments to evaluate RLAdapter in the Crafter environment, and the results show that RLAdapter surpasses the SOTA baselines. Furthermore, agents under our framework exhibit common-sense behaviors that are absent in baseline models.
Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation
Jun 05, 2023



In real-world scenarios, the application of reinforcement learning is significantly challenged by complex non-stationarity. Most existing methods attempt to model the changes of the environment explicitly, often requiring impractical prior knowledge. In this paper, we propose a new perspective, positing that non-stationarity can propagate and accumulate through complex causal relationships during state transitions, thereby compounding its sophistication and affecting policy learning. We believe that this challenge can be more effectively addressed by tracing the causal origin of non-stationarity. To this end, we introduce the Causal-Origin REPresentation (COREP) algorithm. COREP primarily employs a guided updating mechanism to learn a stable graph representation for states termed as causal-origin representation. By leveraging this representation, the learned policy exhibits impressive resilience to non-stationarity. We supplement our approach with a theoretical analysis grounded in the causal interpretation for non-stationary reinforcement learning, advocating for the validity of the causal-origin representation. Experimental results further demonstrate the superior performance of COREP over existing methods in tackling non-stationarity.
Entity Divider with Language Grounding in Multi-Agent Reinforcement Learning
Oct 25, 2022We investigate the use of natural language to drive the generalization of policies in multi-agent settings. Unlike single-agent settings, the generalization of policies should also consider the influence of other agents. Besides, with the increasing number of entities in multi-agent settings, more agent-entity interactions are needed for language grounding, and the enormous search space could impede the learning process. Moreover, given a simple general instruction,e.g., beating all enemies, agents are required to decompose it into multiple subgoals and figure out the right one to focus on. Inspired by previous work, we try to address these issues at the entity level and propose a novel framework for language grounding in multi-agent reinforcement learning, entity divider (EnDi). EnDi enables agents to independently learn subgoal division at the entity level and act in the environment based on the associated entities. The subgoal division is regularized by opponent modeling to avoid subgoal conflicts and promote coordinated strategies. Empirically, EnDi demonstrates the strong generalization ability to unseen games with new dynamics and expresses the superiority over existing methods.
Robust Model-based Reinforcement Learning for Autonomous Greenhouse Control
Aug 26, 2021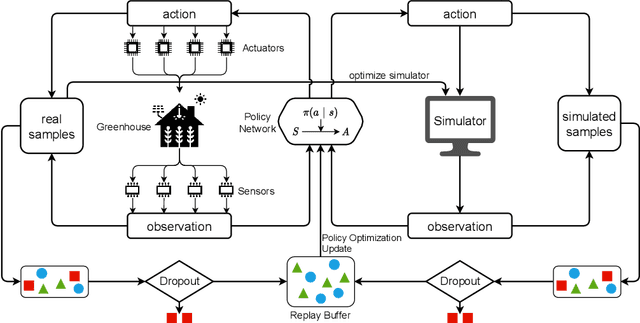
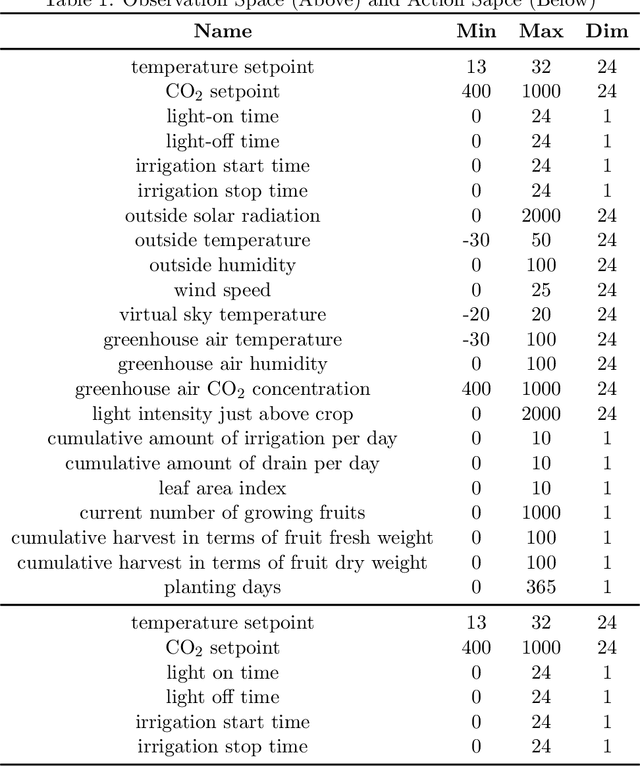

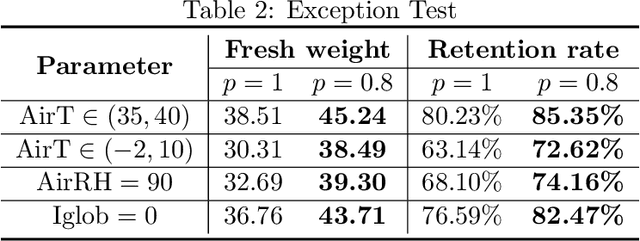
Due to the high efficiency and less weather dependency, autonomous greenhouses provide an ideal solution to meet the increasing demand for fresh food. However, managers are faced with some challenges in finding appropriate control strategies for crop growth, since the decision space of the greenhouse control problem is an astronomical number. Therefore, an intelligent closed-loop control framework is highly desired to generate an automatic control policy. As a powerful tool for optimal control, reinforcement learning (RL) algorithms can surpass human beings' decision-making and can also be seamlessly integrated into the closed-loop control framework. However, in complex real-world scenarios such as agricultural automation control, where the interaction with the environment is time-consuming and expensive, the application of RL algorithms encounters two main challenges, i.e., sample efficiency and safety. Although model-based RL methods can greatly mitigate the efficiency problem of greenhouse control, the safety problem has not got too much attention. In this paper, we present a model-based robust RL framework for autonomous greenhouse control to meet the sample efficiency and safety challenges. Specifically, our framework introduces an ensemble of environment models to work as a simulator and assist in policy optimization, thereby addressing the low sample efficiency problem. As for the safety concern, we propose a sample dropout module to focus more on worst-case samples, which can help improve the adaptability of the greenhouse planting policy in extreme cases. Experimental results demonstrate that our approach can learn a more effective greenhouse planting policy with better robustness than existing methods.
MBDP: A Model-based Approach to Achieve both Robustness and Sample Efficiency via Double Dropout Planning
Aug 03, 2021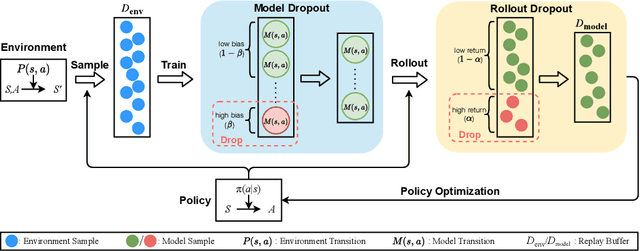



Model-based reinforcement learning is a widely accepted solution for solving excessive sample demands. However, the predictions of the dynamics models are often not accurate enough, and the resulting bias may incur catastrophic decisions due to insufficient robustness. Therefore, it is highly desired to investigate how to improve the robustness of model-based RL algorithms while maintaining high sampling efficiency. In this paper, we propose Model-Based Double-dropout Planning (MBDP) to balance robustness and efficiency. MBDP consists of two kinds of dropout mechanisms, where the rollout-dropout aims to improve the robustness with a small cost of sample efficiency, while the model-dropout is designed to compensate for the lost efficiency at a slight expense of robustness. By combining them in a complementary way, MBDP provides a flexible control mechanism to meet different demands of robustness and efficiency by tuning two corresponding dropout ratios. The effectiveness of MBDP is demonstrated both theoretically and experimentally.
IGrow: A Smart Agriculture Solution to Autonomous Greenhouse Control
Jul 06, 2021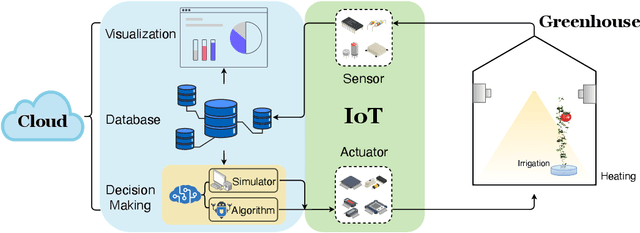
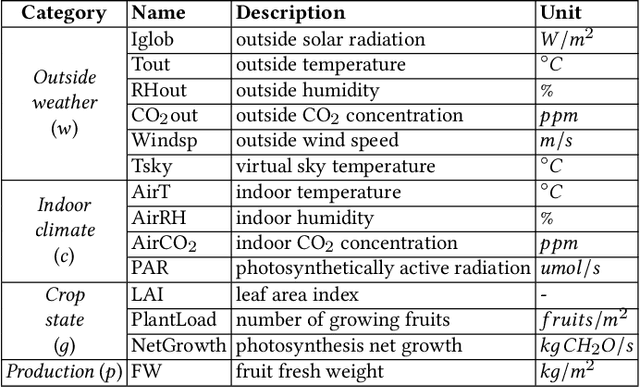
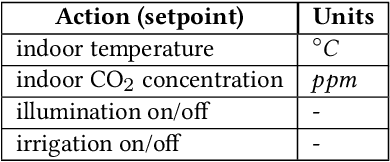
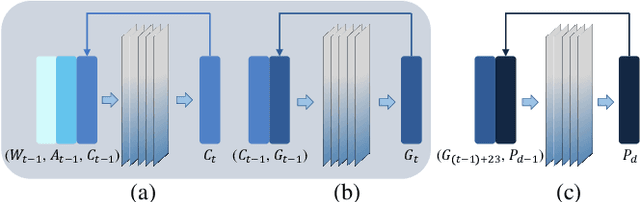
Agriculture is the foundation of human civilization. However, the rapid increase and aging of the global population pose challenges on this cornerstone by demanding more healthy and fresh food. Internet of Things (IoT) technology makes modern autonomous greenhouse a viable and reliable engine of food production. However, the educated and skilled labor capable of overseeing high-tech greenhouses is scarce. Artificial intelligence (AI) and cloud computing technologies are promising solutions for precision control and high-efficiency production in such controlled environments. In this paper, we propose a smart agriculture solution, namely iGrow: (1) we use IoT and cloud computing technologies to measure, collect, and manage growing data, to support iteration of our decision-making AI module, which consists of an incremental model and an optimization algorithm; (2) we propose a three-stage incremental model based on accumulating data, enabling growers/central computers to schedule control strategies conveniently and at low cost; (3) we propose a model-based iterative optimization algorithm, which can dynamically optimize the greenhouse control strategy in real-time production. In the simulated experiment, evaluation results show the accuracy of our incremental model is comparable to an advanced tomato simulator, while our optimization algorithms can beat the champion of the 2nd Autonomous Greenhouse Challenge. Compelling results from the A/B test in real greenhouses demonstrate that our solution significantly increases production (commercially sellable fruits) (+ 10.15%) and net profit (+ 87.07%) with statistical significance compared to planting experts.
Sample Efficient Reinforcement Learning via Model-Ensemble Exploration and Exploitation
Jul 05, 2021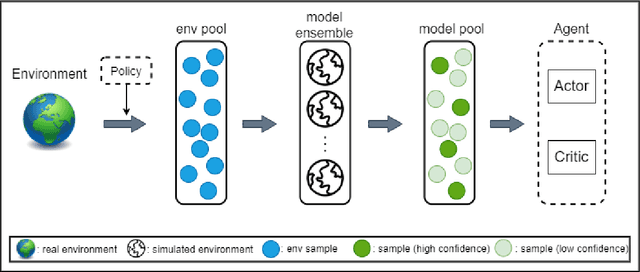
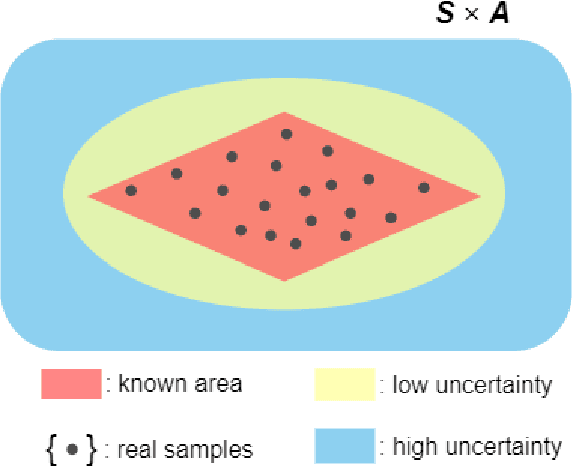
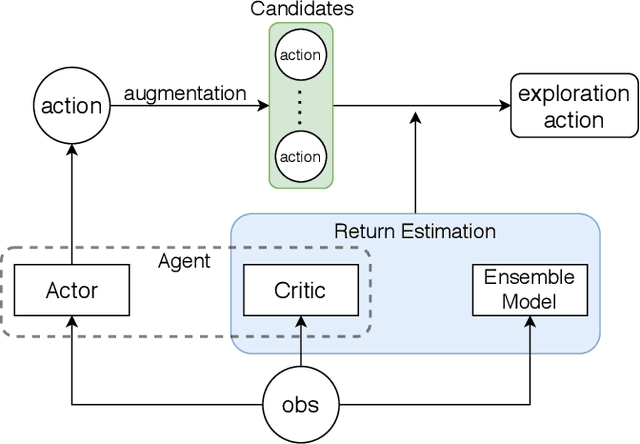

Model-based deep reinforcement learning has achieved success in various domains that require high sample efficiencies, such as Go and robotics. However, there are some remaining issues, such as planning efficient explorations to learn more accurate dynamic models, evaluating the uncertainty of the learned models, and more rational utilization of models. To mitigate these issues, we present MEEE, a model-ensemble method that consists of optimistic exploration and weighted exploitation. During exploration, unlike prior methods directly selecting the optimal action that maximizes the expected accumulative return, our agent first generates a set of action candidates and then seeks out the optimal action that takes both expected return and future observation novelty into account. During exploitation, different discounted weights are assigned to imagined transition tuples according to their model uncertainty respectively, which will prevent model predictive error propagation in agent training. Experiments on several challenging continuous control benchmark tasks demonstrated that our approach outperforms other model-free and model-based state-of-the-art methods, especially in sample complexity.