 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
Paper and Code
Oct 03, 2024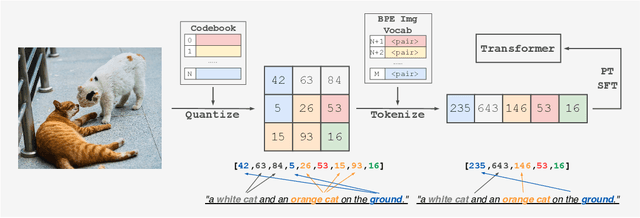
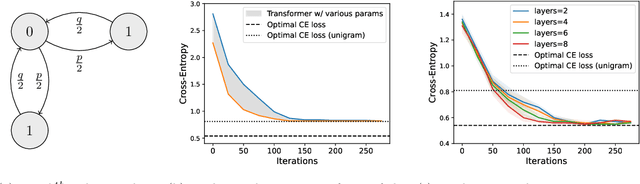
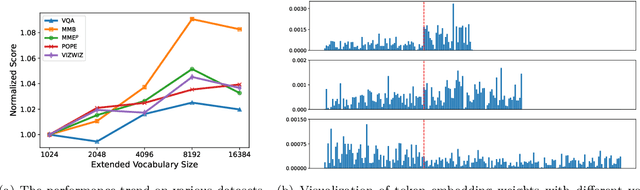
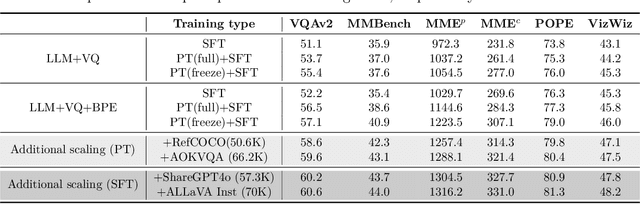
Multimodal Large Language Models have made significant strides in integrating visual and textual information, yet they often struggle with effectively aligning these modalities. We introduce a novel image tokenizer that bridges this gap by applying the principle of Byte-Pair Encoding (BPE) to visual data. Unlike conventional approaches that rely on separate visual encoders, our method directly incorporates structural prior information into image tokens, mirroring the successful tokenization strategies used in text-only Large Language Models. This innovative approach enables Transformer models to more effectively learn and reason across modalities. Through theoretical analysis and extensive experiments, we demonstrate that our BPE Image Tokenizer significantly enhances MLLMs' multimodal understanding capabilities, even with limited training data. Our method not only improves performance across various benchmarks but also shows promising scalability, potentially paving the way for more efficient and capable multimodal foundation models.