 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Robotic Manipulation via 3D Gaussian Splatting-Enhanced Multimodal Retrieval-Augmented Generation
Feb 28, 2026Existing end-to-end approaches of robotic manipulation often lack generalization to unseen objects or tasks due to limited data and poor interpretability. While recent Multimodal Large Language Models (MLLMs) demonstrate strong commonsense reasoning, they struggle with geometric and spatial understanding required for pose prediction. In this paper, we propose RobMRAG, a 3D Gaussian Splatting-Enhanced Multimodal Retrieval-Augmented Generation (MRAG) framework for zero-shot robotic manipulation. Specifically, we construct a multi-source manipulation knowledge base containing object contact frames, task completion frames, and pose parameters. During inference, a Hierarchical Multimodal Retrieval module first employs a three-priority hybrid retrieval strategy to find task-relevant object prototypes, then selects the geometrically closest reference example based on pixel-level similarity and Instance Matching Distance (IMD). We further introduce a 3D-Aware Pose Refinement module based on 3D Gaussian Splatting into the MRAG framework, which aligns the pose of the reference object to the target object in 3D space. The aligned results are reprojected onto the image plane and used as input to the MLLM to enhance the generation of the final pose parameters. Extensive experiments show that on a test set containing 30 categories of household objects, our method improves the success rate by 7.76% compared to the best-performing zero-shot baseline under the same setting, and by 6.54% compared to the state-of-the-art supervised baseline. Our results validate that RobMRAG effectively bridges the gap between high-level semantic reasoning and low-level geometric execution, enabling robotic systems that generalize to unseen objects while remaining inherently interpretable.
HetGL2R: Learning to Rank Critical Road Segments via Attributed Heterogeneous Graph Random Walks
Apr 27, 2025Accurately identifying critical nodes with high spatial influence in road networks is essential for enhancing the efficiency of traffic management and urban planning. However, existing node importance ranking methods mainly rely on structural features and topological information, often overlooking critical factors such as origin-destination (OD) demand and route information. This limitation leaves considerable room for improvement in ranking accuracy. To address this issue, we propose HetGL2R, an attributed heterogeneous graph learning approach for ranking node importance in road networks. This method introduces a tripartite graph (trip graph) to model the structure of the road network, integrating OD demand, route choice, and various structural features of road segments. Based on the trip graph, we design an embedding method to learn node representations that reflect the spatial influence of road segments. The method consists of a heterogeneous random walk sampling algorithm (HetGWalk) and a Transformer encoder. HetGWalk constructs multiple attribute-guided graphs based on the trip graph to enrich the diversity of semantic associations between nodes. It then applies a joint random walk mechanism to convert both topological structures and node attributes into sequences, enabling the encoder to capture spatial dependencies more effectively among road segments. Finally, a listwise ranking strategy is employed to evaluate node importance. To validate the performance of our method, we construct two synthetic datasets using SUMO based on simulated road networks. Experimental results demonstrate that HetGL2R significantly outperforms baselines in incorporating OD demand and route choice information, achieving more accurate and robust node ranking. Furthermore, we conduct a case study using real-world taxi trajectory data from Beijing, further verifying the practicality of the proposed method.
E2E-AFG: An End-to-End Model with Adaptive Filtering for Retrieval-Augmented Generation
Nov 01, 2024



Retrieval-augmented generation methods often neglect the quality of content retrieved from external knowledge bases, resulting in irrelevant information or potential misinformation that negatively affects the generation results of large language models. In this paper, we propose an end-to-end model with adaptive filtering for retrieval-augmented generation (E2E-AFG), which integrates answer existence judgment and text generation into a single end-to-end framework. This enables the model to focus more effectively on relevant content while reducing the influence of irrelevant information and generating accurate answers. We evaluate E2E-AFG on six representative knowledge-intensive language datasets, and the results show that it consistently outperforms baseline models across all tasks, demonstrating the effectiveness and robustness of the proposed approach.
From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
Oct 03, 2024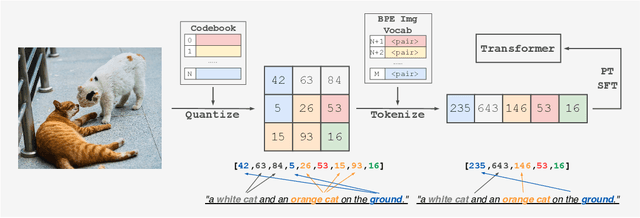
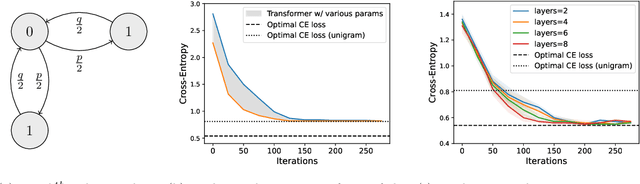
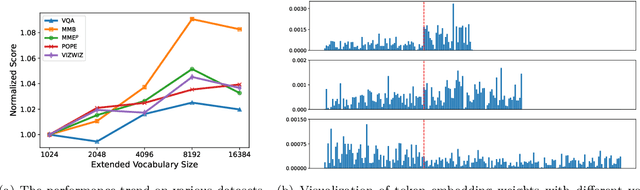
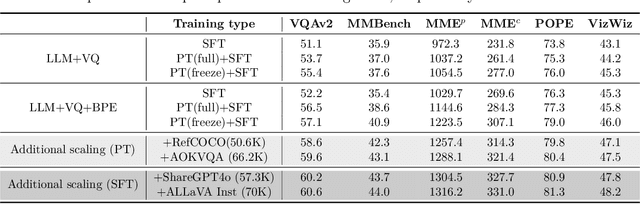
Multimodal Large Language Models have made significant strides in integrating visual and textual information, yet they often struggle with effectively aligning these modalities. We introduce a novel image tokenizer that bridges this gap by applying the principle of Byte-Pair Encoding (BPE) to visual data. Unlike conventional approaches that rely on separate visual encoders, our method directly incorporates structural prior information into image tokens, mirroring the successful tokenization strategies used in text-only Large Language Models. This innovative approach enables Transformer models to more effectively learn and reason across modalities. Through theoretical analysis and extensive experiments, we demonstrate that our BPE Image Tokenizer significantly enhances MLLMs' multimodal understanding capabilities, even with limited training data. Our method not only improves performance across various benchmarks but also shows promising scalability, potentially paving the way for more efficient and capable multimodal foundation models.
Hierarchical Spatial Proximity Reasoning for Vision-and-Language Navigation
Mar 18, 2024



Most Vision-and-Language Navigation (VLN) algorithms tend to make decision errors, primarily due to a lack of visual common sense and insufficient reasoning capabilities. To address this issue, this paper proposes a Hierarchical Spatial Proximity Reasoning (HSPR) model. Firstly, we design a Scene Understanding Auxiliary Task (SUAT) to assist the agent in constructing a knowledge base of hierarchical spatial proximity for reasoning navigation. Specifically, this task utilizes panoramic views and object features to identify regions in the navigation environment and uncover the adjacency relationships between regions, objects, and region-object pairs. Secondly, we dynamically construct a semantic topological map through agent-environment interactions and propose a Multi-step Reasoning Navigation Algorithm (MRNA) based on the map. This algorithm continuously plans various feasible paths from one region to another, utilizing the constructed proximity knowledge base, enabling more efficient exploration. Additionally, we introduce a Proximity Adaptive Attention Module (PAAM) and Residual Fusion Method (RFM) to enable the model to obtain more accurate navigation decision confidence. Finally, we conduct experiments on publicly available datasets including REVERIE, SOON, R2R, and R4R to validate the effectiveness of the proposed approach.