 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Implicit Neural Representations and B-Splines for Continuous Function Fitting from Sparse Samples
Feb 25, 2026Continuous signal representations are naturally suited for inverse problems, such as magnetic resonance imaging (MRI) and computed tomography, because the measurements depend on an underlying physically continuous signal. While classical methods rely on predefined analytical bases like B-splines, implicit neural representations (INRs) have emerged as a powerful alternative that use coordinate-based networks to parameterize continuous functions with implicitly defined bases. Despite their empirical success, direct comparisons of their intrinsic representation capabilities with conventional models remain limited. This preliminary empirical study compares a positional-encoded INR with a cubic B-spline model for continuous function fitting from sparse random samples, isolating the representation capacity difference by only using coefficient-domain Tikhonov regularization. Results demonstrate that, under oracle hyperparameter selection, the INR achieves a lower normalized root-mean-squared error, yielding sharper edge transitions and fewer oscillatory artifacts than the oracle-tuned B-spline model. Additionally, we show that a practical bilevel optimization framework for INR hyperparameter selection based on measurement data split effectively approximates oracle performance. These findings empirically support the superior representation capacity of INRs for sparse data fitting.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Bilevel Optimized Implicit Neural Representation for Scan-Specific Accelerated MRI Reconstruction
Feb 28, 2025Deep Learning (DL) methods can reconstruct highly accelerated magnetic resonance imaging (MRI) scans, but they rely on application-specific large training datasets and often generalize poorly to out-of-distribution data. Self-supervised deep learning algorithms perform scan-specific reconstructions, but still require complicated hyperparameter tuning based on the acquisition and often offer limited acceleration. This work develops a bilevel-optimized implicit neural representation (INR) approach for scan-specific MRI reconstruction. The method automatically optimizes the hyperparameters for a given acquisition protocol, enabling a tailored reconstruction without training data. The proposed algorithm uses Gaussian process regression to optimize INR hyperparameters, accommodating various acquisitions. The INR includes a trainable positional encoder for high-dimensional feature embedding and a small multilayer perceptron for decoding. The bilevel optimization is computationally efficient, requiring only a few minutes per typical 2D Cartesian scan. On scanner hardware, the subsequent scan-specific reconstruction-using offline-optimized hyperparameters-is completed within seconds and achieves improved image quality compared to previous model-based and self-supervised learning methods.
E2E-AFG: An End-to-End Model with Adaptive Filtering for Retrieval-Augmented Generation
Nov 01, 2024



Retrieval-augmented generation methods often neglect the quality of content retrieved from external knowledge bases, resulting in irrelevant information or potential misinformation that negatively affects the generation results of large language models. In this paper, we propose an end-to-end model with adaptive filtering for retrieval-augmented generation (E2E-AFG), which integrates answer existence judgment and text generation into a single end-to-end framework. This enables the model to focus more effectively on relevant content while reducing the influence of irrelevant information and generating accurate answers. We evaluate E2E-AFG on six representative knowledge-intensive language datasets, and the results show that it consistently outperforms baseline models across all tasks, demonstrating the effectiveness and robustness of the proposed approach.
StarLKNet: Star Mixup with Large Kernel Networks for Palm Vein Identification
May 21, 2024



As a representative of a new generation of biometrics, vein identification technology offers a high level of security and convenience. Convolutional neural networks (CNNs), a prominent class of deep learning architectures, have been extensively utilized for vein identification. Since their performance and robustness are limited by small Effective Receptive Fields (e.g. 3$\times$3 kernels) and insufficient training samples, however, they are unable to extract global feature representations from vein images in an effective manner. To address these issues, we propose StarLKNet, a large kernel convolution-based palm-vein identification network, with the Mixup approach. Our StarMix learns effectively the distribution of vein features to expand samples. To enable CNNs to capture comprehensive feature representations from palm-vein images, we explored the effect of convolutional kernel size on the performance of palm-vein identification networks and designed LaKNet, a network leveraging large kernel convolution and gating mechanism. In light of the current state of knowledge, this represents an inaugural instance of the deployment of a CNN with large kernels in the domain of vein identification. Extensive experiments were conducted to validate the performance of StarLKNet on two public palm-vein datasets. The results demonstrated that StarMix provided superior augmentation, and LakNet exhibited more stable performance gains compared to mainstream approaches, resulting in the highest recognition accuracy and lowest identification error.
Adversarial AutoMixup
Dec 19, 2023Data mixing augmentation has been widely applied to improve the generalization ability of deep neural networks. Recently, offline data mixing augmentation, e.g. handcrafted and saliency information-based mixup, has been gradually replaced by automatic mixing approaches. Through minimizing two sub-tasks, namely, mixed sample generation and mixup classification in an end-to-end way, AutoMix significantly improves accuracy on image classification tasks. However, as the optimization objective is consistent for the two sub-tasks, this approach is prone to generating consistent instead of diverse mixed samples, which results in overfitting for target task training. In this paper, we propose AdAutomixup, an adversarial automatic mixup augmentation approach that generates challenging samples to train a robust classifier for image classification, by alternatively optimizing the classifier and the mixup sample generator. AdAutomixup comprises two modules, a mixed example generator, and a target classifier. The mixed sample generator aims to produce hard mixed examples to challenge the target classifier while the target classifier`s aim is to learn robust features from hard mixed examples to improve generalization. To prevent the collapse of the inherent meanings of images, we further introduce an exponential moving average (EMA) teacher and cosine similarity to train AdAutomixup in an end-to-end way. Extensive experiments on seven image benchmarks consistently prove that our approach outperforms the state of the art in various classification scenarios.
PharmMT: A Neural Machine Translation Approach to Simplify Prescription Directions
Apr 08, 2022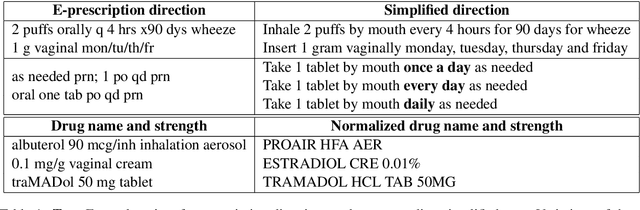
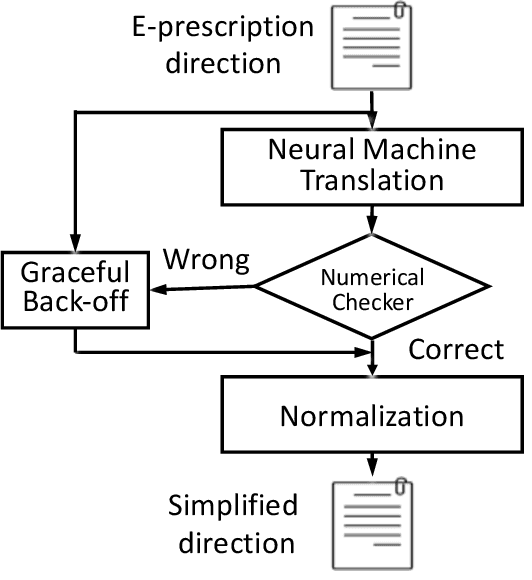
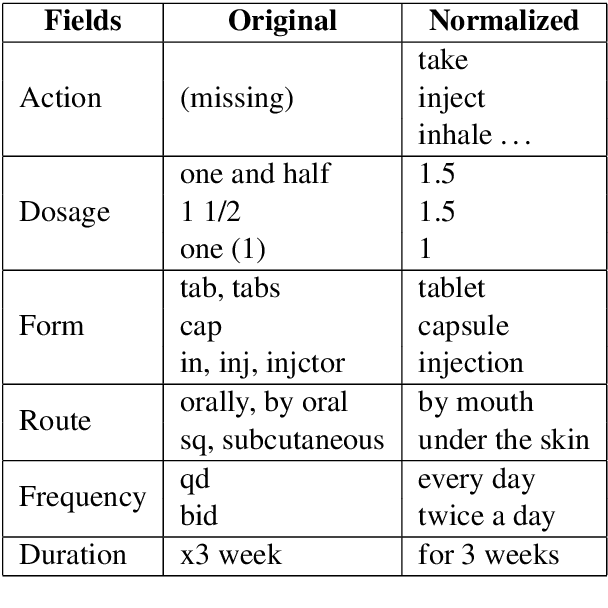

The language used by physicians and health professionals in prescription directions includes medical jargon and implicit directives and causes much confusion among patients. Human intervention to simplify the language at the pharmacies may introduce additional errors that can lead to potentially severe health outcomes. We propose a novel machine translation-based approach, PharmMT, to automatically and reliably simplify prescription directions into patient-friendly language, thereby significantly reducing pharmacist workload. We evaluate the proposed approach over a dataset consisting of over 530K prescriptions obtained from a large mail-order pharmacy. The end-to-end system achieves a BLEU score of 60.27 against the reference directions generated by pharmacists, a 39.6% relative improvement over the rule-based normalization. Pharmacists judged 94.3% of the simplified directions as usable as-is or with minimal changes. This work demonstrates the feasibility of a machine translation-based tool for simplifying prescription directions in real-life.
* Findings of EMNLP '20 Camera Ready
Game of Learning Bloch Equation Simulations for MR Fingerprinting
Apr 05, 2020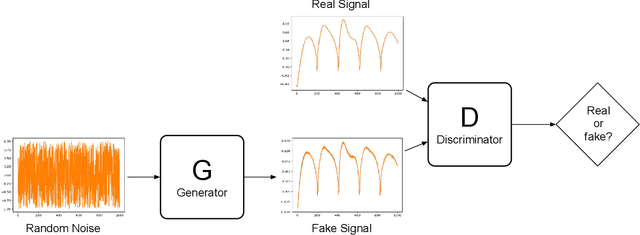
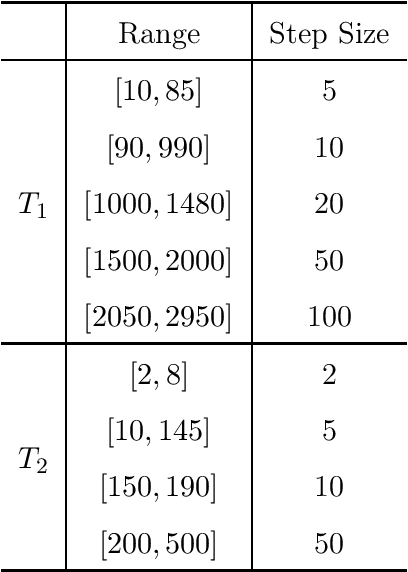
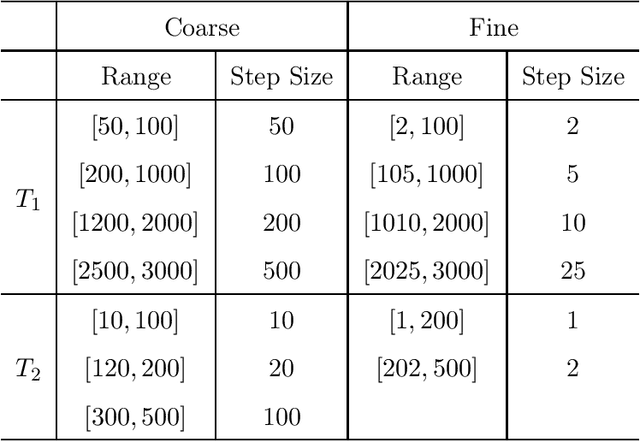
Purpose: This work proposes a novel approach to efficiently generate MR fingerprints for MR fingerprinting (MRF) problems based on the unsupervised deep learning model generative adversarial networks (GAN). Methods: The GAN model is adopted and modified for better convergence and performance, resulting in an MRF specific model named GAN-MRF. The GAN-MRF model is trained, validated, and tested using different MRF fingerprints simulated from the Bloch equations with certain MRF sequence. The performance and robustness of the model are further tested by using in vivo data collected on a 3 Tesla scanner from a healthy volunteer together with MRF dictionaries with different sizes. T1, T2 maps are generated and compared quantitatively. Results: The validation and testing curves for the GAN-MRF model show no evidence of high bias or high variance problems. The sample MRF fingerprints generated from the trained GAN-MRF model agree well with the benchmark fingerprints simulated from the Bloch equations. The in vivo T1, T2 maps generated from the GAN-MRF fingerprints are in good agreement with those generated from the Bloch simulated fingerprints, showing good performance and robustness of the proposed GAN-MRF model. Moreover, the MRF dictionary generation time is reduced from hours to sub-second for the testing dictionary. Conclusion: The GAN-MRF model enables a fast and accurate generation of the MRF fingerprints. It significantly reduces the MRF dictionary generation process and opens the door for real-time applications and sequence optimization problems.
Retinal Vessels Segmentation Based on Dilated Multi-Scale Convolutional Neural Network
Apr 11, 2019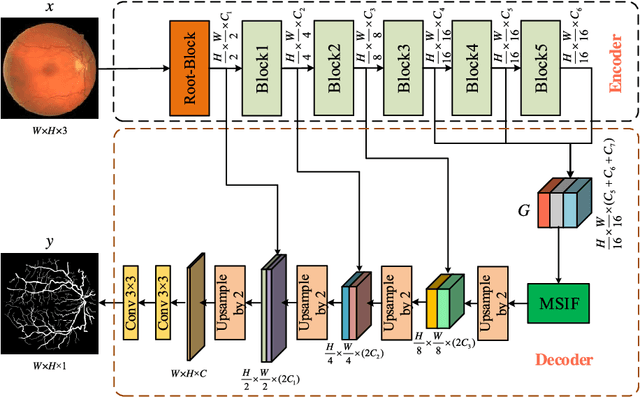

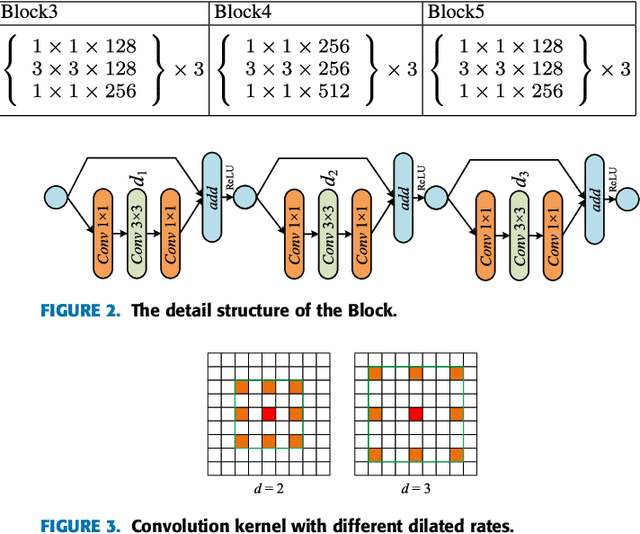
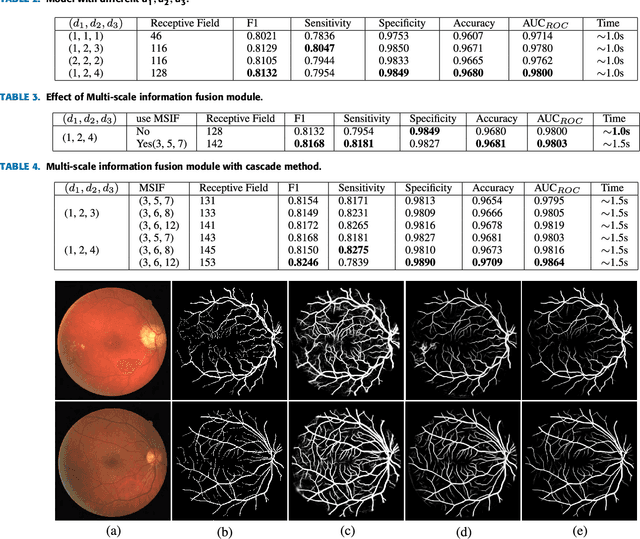
Accurate segmentation of retinal vessels is a basic step in Diabetic retinopathy(DR) detection. Most methods based on deep convolutional neural network (DCNN) have small receptive fields, and hence they are unable to capture global context information of larger regions, with difficult to identify lesions. The final segmented retina vessels contain more noise with low classification accuracy. Therefore, in this paper, we propose a DCNN structure named as D-Net. In the proposed D-Net, the dilation convolution is used in the backbone network to obtain a larger receptive field without losing spatial resolution, so as to reduce the loss of feature information and to reduce the difficulty of tiny thin vessels segmentation. The large receptive field can better distinguished between the lesion area and the blood vessel area. In the proposed Multi-Scale Information Fusion module (MSIF), parallel convolution layers with different dilation rates are used, so that the model can obtain more dense feature information and better capture retinal vessel information of different sizes. In the decoding module, the skip layer connection is used to propagate context information to higher resolution layers, so as to prevent low-level information from passing the entire network structure. Finally, our method was verified on DRIVE, STARE and CHASE dataset. The experimental results show that our network structure outperforms some state-of-art method, such as N4-fields, U-Net, and DRIU in terms of accuracy, sensitivity, specificity, and AUCROC. Particularly, D-Net outperforms U-Net by 1.04%, 1.23% and 2.79% in DRIVE, STARE, and CHASE three dataset, respectively.
Retinal Vessel Segmentation Based on Conditional Deep Convolutional Generative Adversarial Networks
May 11, 2018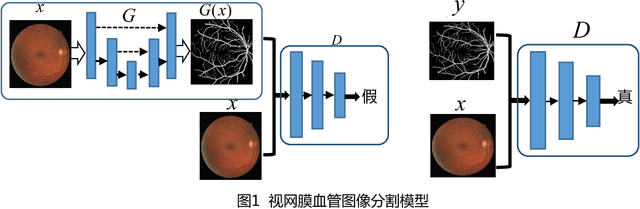
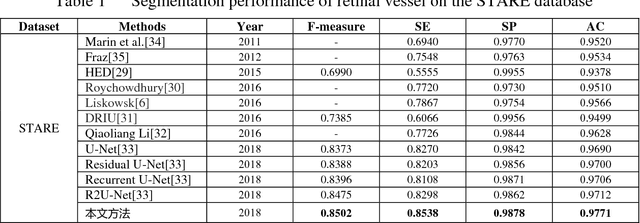
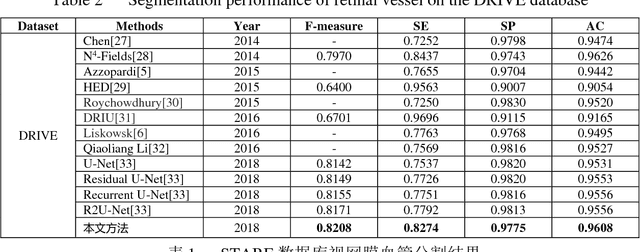
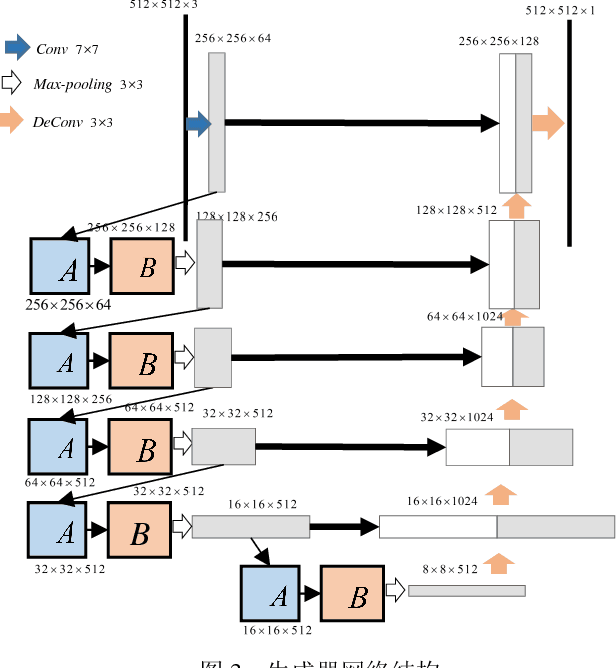
The segmentation of retinal vessels is of significance for doctors to diagnose the fundus diseases. However, existing methods have various problems in the segmentation of the retinal vessels, such as insufficient segmentation of retinal vessels, weak anti-noise interference ability, and sensitivity to lesions, etc. Aiming to the shortcomings of existed methods, this paper proposes the use of conditional deep convolutional generative adversarial networks to segment the retinal vessels. We mainly improve the network structure of the generator. The introduction of the residual module at the convolutional layer for residual learning makes the network structure sensitive to changes in the output, as to better adjust the weight of the generator. In order to reduce the number of parameters and calculations, using a small convolution to halve the number of channels in the input signature before using a large convolution kernel. By used skip connection to connect the output of the convolutional layer with the output of the deconvolution layer to avoid low-level information sharing. By verifying the method on the DRIVE and STARE datasets, the segmentation accuracy rate is 96.08% and 97.71%, the sensitivity reaches 82.74% and 85.34% respectively, and the F-measure reaches 82.08% and 85.02% respectively. The sensitivity is 4.82% and 2.4% higher than that of R2U-Net.