 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Insertion-based Textual Backdoor Attacks via Attribution
May 03, 2023



Textual backdoor attack, as a novel attack model, has been shown to be effective in adding a backdoor to the model during training. Defending against such backdoor attacks has become urgent and important. In this paper, we propose AttDef, an efficient attribution-based pipeline to defend against two insertion-based poisoning attacks, BadNL and InSent. Specifically, we regard the tokens with larger attribution scores as potential triggers since larger attribution words contribute more to the false prediction results and therefore are more likely to be poison triggers. Additionally, we further utilize an external pre-trained language model to distinguish whether input is poisoned or not. We show that our proposed method can generalize sufficiently well in two common attack scenarios (poisoning training data and testing data), which consistently improves previous methods. For instance, AttDef can successfully mitigate both attacks with an average accuracy of 79.97% (56.59% up) and 48.34% (3.99% up) under pre-training and post-training attack defense respectively, achieving the new state-of-the-art performance on prediction recovery over four benchmark datasets.
ChatGPT as an Attack Tool: Stealthy Textual Backdoor Attack via Blackbox Generative Model Trigger
Apr 27, 2023



Textual backdoor attacks pose a practical threat to existing systems, as they can compromise the model by inserting imperceptible triggers into inputs and manipulating labels in the training dataset. With cutting-edge generative models such as GPT-4 pushing rewriting to extraordinary levels, such attacks are becoming even harder to detect. We conduct a comprehensive investigation of the role of black-box generative models as a backdoor attack tool, highlighting the importance of researching relative defense strategies. In this paper, we reveal that the proposed generative model-based attack, BGMAttack, could effectively deceive textual classifiers. Compared with the traditional attack methods, BGMAttack makes the backdoor trigger less conspicuous by leveraging state-of-the-art generative models. Our extensive evaluation of attack effectiveness across five datasets, complemented by three distinct human cognition assessments, reveals that Figure 4 achieves comparable attack performance while maintaining superior stealthiness relative to baseline methods.
IDPG: An Instance-Dependent Prompt Generation Method
Apr 09, 2022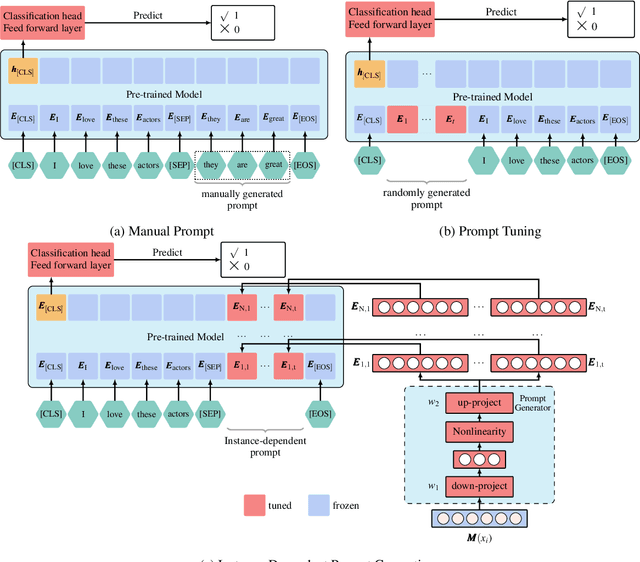
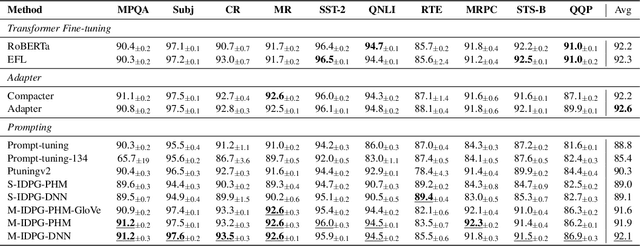

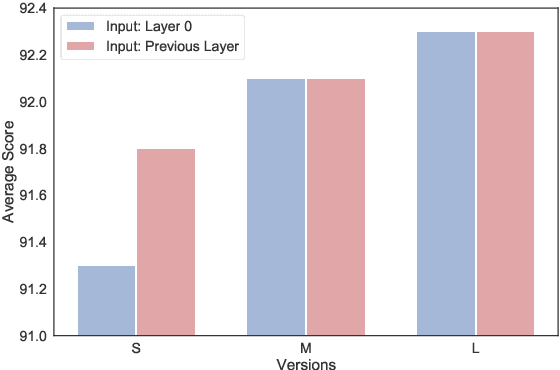
Prompt tuning is a new, efficient NLP transfer learning paradigm that adds a task-specific prompt in each input instance during the model training stage. It freezes the pre-trained language model and only optimizes a few task-specific prompts. In this paper, we propose a conditional prompt generation method to generate prompts for each input instance, referred to as the Instance-Dependent Prompt Generation (IDPG). Unlike traditional prompt tuning methods that use a fixed prompt, IDPG introduces a lightweight and trainable component to generate prompts based on each input sentence. Extensive experiments on ten natural language understanding (NLU) tasks show that the proposed strategy consistently outperforms various prompt tuning baselines and is on par with other efficient transfer learning methods such as Compacter while tuning far fewer model parameters.
PharmMT: A Neural Machine Translation Approach to Simplify Prescription Directions
Apr 08, 2022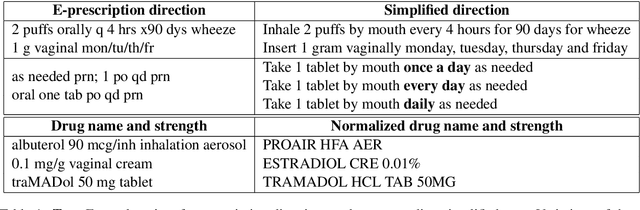
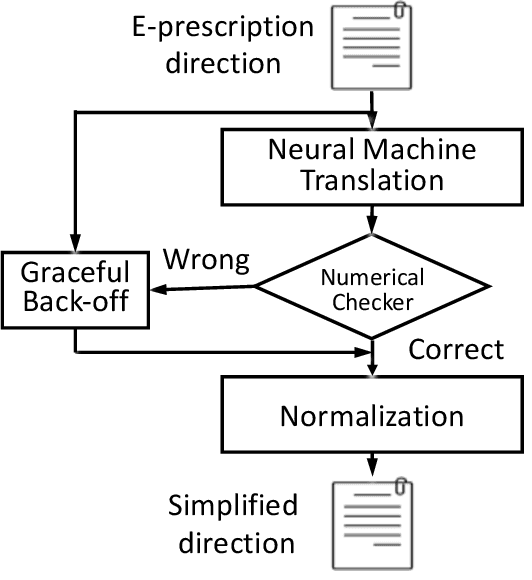
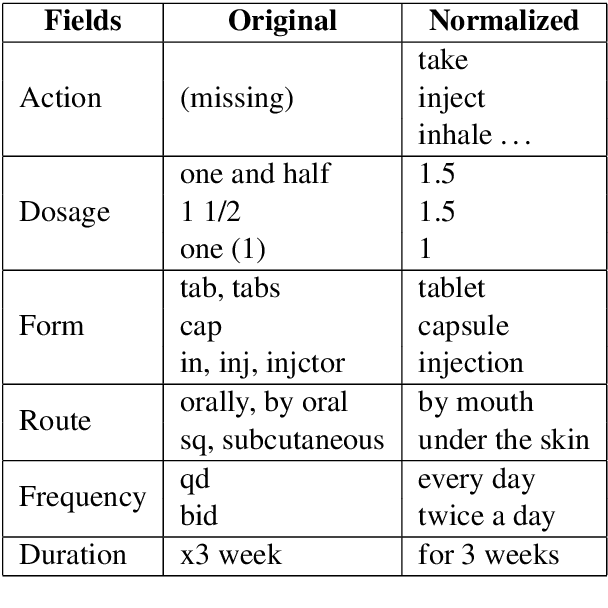

The language used by physicians and health professionals in prescription directions includes medical jargon and implicit directives and causes much confusion among patients. Human intervention to simplify the language at the pharmacies may introduce additional errors that can lead to potentially severe health outcomes. We propose a novel machine translation-based approach, PharmMT, to automatically and reliably simplify prescription directions into patient-friendly language, thereby significantly reducing pharmacist workload. We evaluate the proposed approach over a dataset consisting of over 530K prescriptions obtained from a large mail-order pharmacy. The end-to-end system achieves a BLEU score of 60.27 against the reference directions generated by pharmacists, a 39.6% relative improvement over the rule-based normalization. Pharmacists judged 94.3% of the simplified directions as usable as-is or with minimal changes. This work demonstrates the feasibility of a machine translation-based tool for simplifying prescription directions in real-life.
* Findings of EMNLP '20 Camera Ready
LIREx: Augmenting Language Inference with Relevant Explanation
Dec 16, 2020
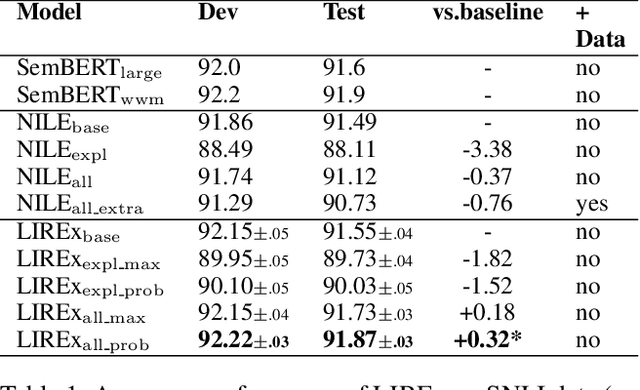
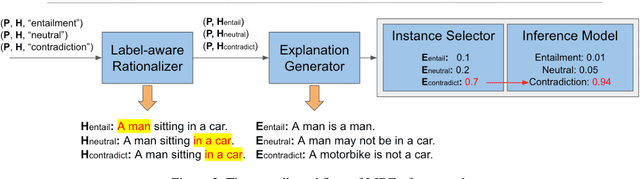
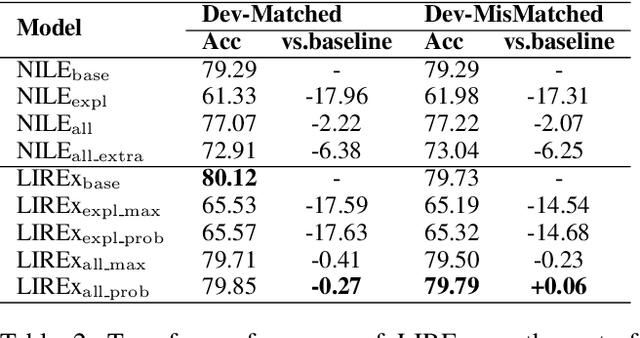
Natural language explanations (NLEs) are a special form of data annotation in which annotators identify rationales (most significant text tokens) when assigning labels to data instances, and write out explanations for the labels in natural language based on the rationales. NLEs have been shown to capture human reasoning better, but not as beneficial for natural language inference (NLI). In this paper, we analyze two primary flaws in the way NLEs are currently used to train explanation generators for language inference tasks. We find that the explanation generators do not take into account the variability inherent in human explanation of labels, and that the current explanation generation models generate spurious explanations. To overcome these limitations, we propose a novel framework, LIREx, that incorporates both a rationale-enabled explanation generator and an instance selector to select only relevant, plausible NLEs to augment NLI models. When evaluated on the standardized SNLI data set, LIREx achieved an accuracy of 91.87%, an improvement of 0.32 over the baseline and matching the best-reported performance on the data set. It also achieves significantly better performance than previous studies when transferred to the out-of-domain MultiNLI data set. Qualitative analysis shows that LIREx generates flexible, faithful, and relevant NLEs that allow the model to be more robust to spurious explanations. The code is available at https://github.com/zhaoxy92/LIREx.