 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAnet: A New Temporal Attention Network for EEG-based Auditory Spatial Attention Decoding with a Short Decision Window
Jan 11, 2024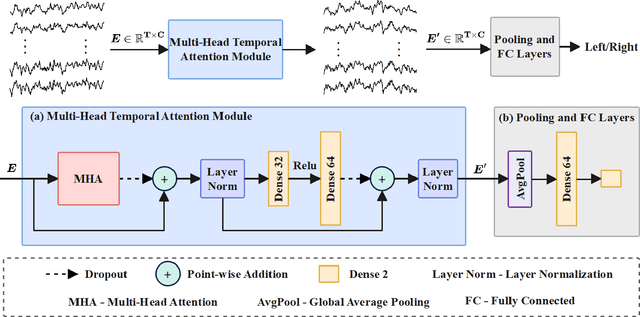

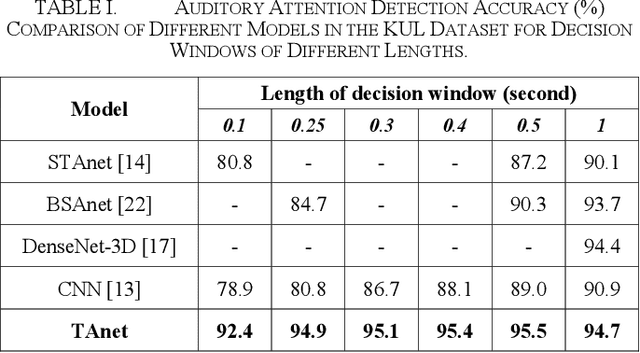
Auditory spatial attention detection (ASAD) is used to determine the direction of a listener's attention to a speaker by analyzing her/his electroencephalographic (EEG) signals. This study aimed to further improve the performance of ASAD with a short decision window (i.e., <1 s) rather than with long decision windows in previous studies. An end-to-end temporal attention network (i.e., TAnet) was introduced in this work. TAnet employs a multi-head attention (MHA) mechanism, which can more effectively capture the interactions among time steps in collected EEG signals and efficiently assign corresponding weights to those EEG time steps. Experiments demonstrated that, compared with the CNN-based method and recent ASAD methods, TAnet provided improved decoding performance in the KUL dataset, with decoding accuracies of 92.4% (decision window 0.1 s), 94.9% (0.25 s), 95.1% (0.3 s), 95.4% (0.4 s), and 95.5% (0.5 s) with short decision windows (i.e., <1 s). As a new ASAD model with a short decision window, TAnet can potentially facilitate the design of EEG-controlled intelligent hearing aids and sound recognition systems.
A Latent Feature Analysis-based Approach for Spatio-Temporal Traffic Data Recovery
Aug 16, 2022



Missing data is an inevitable and common problem in data-driven intelligent transportation systems (ITS). In the past decade, scholars have done many research on the recovery of missing traffic data, however how to make full use of spatio-temporal traffic patterns to improve the recovery performance is still an open problem. Aiming at the spatio-temporal characteristics of traffic speed data, this paper regards the recovery of missing data as a matrix completion problem, and proposes a spatio-temporal traffic data completion method based on hidden feature analysis, which discovers spatio-temporal patterns and underlying structures from incomplete data to complete the recovery task. Therefore, we introduce spatial and temporal correlation to capture the main underlying features of each dimension. Finally, these latent features are applied to recovery traffic data through latent feature analysis. The experimental and evaluation results show that the evaluation criterion value of the model is small, which indicates that the model has better performance. The results show that the model can accurately estimate the continuous missing data.
PharmMT: A Neural Machine Translation Approach to Simplify Prescription Directions
Apr 08, 2022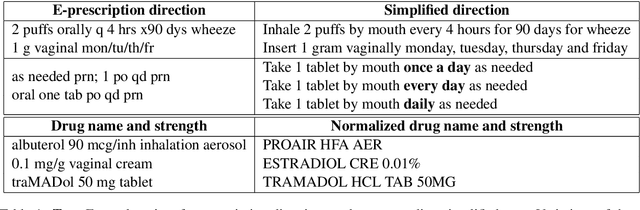
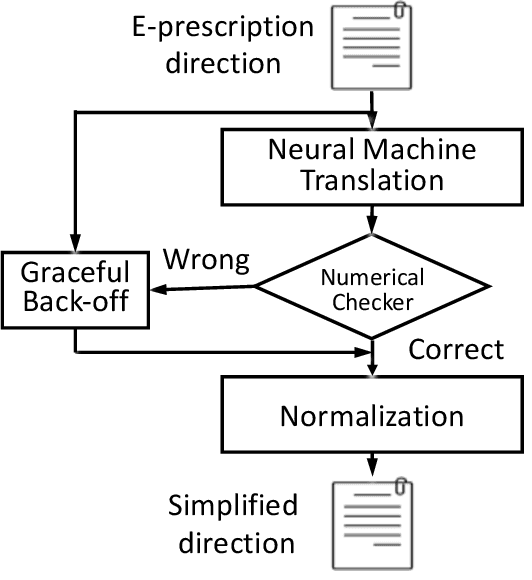
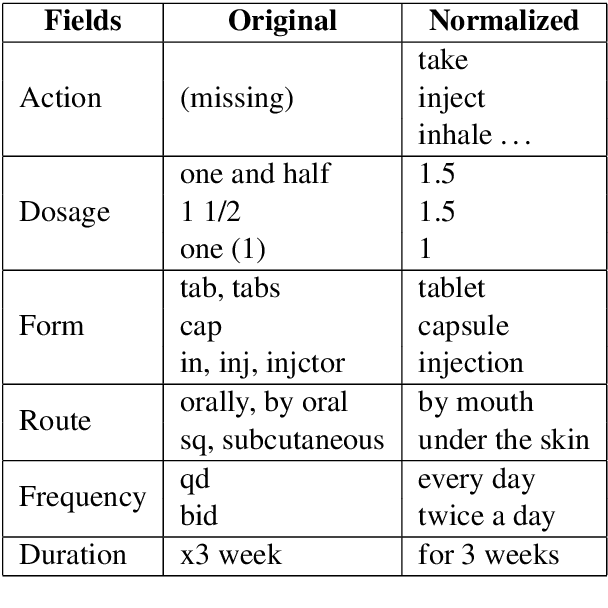

The language used by physicians and health professionals in prescription directions includes medical jargon and implicit directives and causes much confusion among patients. Human intervention to simplify the language at the pharmacies may introduce additional errors that can lead to potentially severe health outcomes. We propose a novel machine translation-based approach, PharmMT, to automatically and reliably simplify prescription directions into patient-friendly language, thereby significantly reducing pharmacist workload. We evaluate the proposed approach over a dataset consisting of over 530K prescriptions obtained from a large mail-order pharmacy. The end-to-end system achieves a BLEU score of 60.27 against the reference directions generated by pharmacists, a 39.6% relative improvement over the rule-based normalization. Pharmacists judged 94.3% of the simplified directions as usable as-is or with minimal changes. This work demonstrates the feasibility of a machine translation-based tool for simplifying prescription directions in real-life.
* Findings of EMNLP '20 Camera Ready
Fine-grained Pattern Matching Over Streaming Time Series
Dec 01, 2017
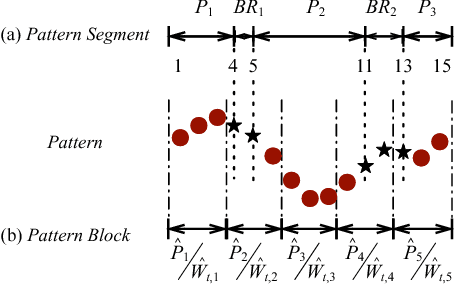
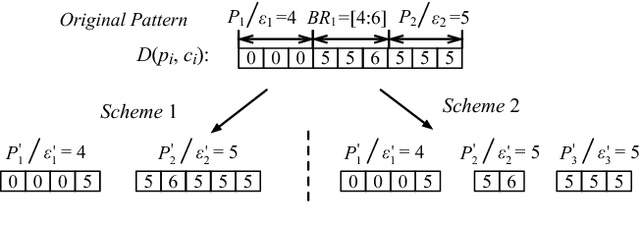

Pattern matching of streaming time series with lower latency under limited computing resource comes to a critical problem, especially as the growth of Industry 4.0 and Industry Internet of Things. However, against traditional single pattern matching problem, a pattern may contain multiple segments representing different statistical properties or physical meanings for more precise and expressive matching in real world. Hence, we formulate a new problem, called "fine-grained pattern matching", which allows users to specify varied granularities of matching deviation to different segments of a given pattern, and fuzzy regions for adaptive breakpoints determination between consecutive segments. In this paper, we propose a novel two-phase approach. In the pruning phase, we introduce Equal-Length Block (ELB) representation together with Block-Skipping Pruning (BSP) policy, which guarantees low cost feature calculation, effective pruning and no false dismissals. In the post-processing phase, a delta-function is proposed to enable us to conduct exact matching in linear complexity. Extensive experiments are conducted to evaluate on synthetic and real-world datasets, which illustrates that our algorithm outperforms the brute-force method and MSM, a multi-step filter mechanism over the multi-scaled representation.