 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Vision Language Model Unlearning via Fictitious Facial Identity Dataset
Nov 05, 2024



Machine unlearning has emerged as an effective strategy for forgetting specific information in the training data. However, with the increasing integration of visual data, privacy concerns in Vision Language Models (VLMs) remain underexplored. To address this, we introduce Facial Identity Unlearning Benchmark (FIUBench), a novel VLM unlearning benchmark designed to robustly evaluate the effectiveness of unlearning algorithms under the Right to be Forgotten setting. Specifically, we formulate the VLM unlearning task via constructing the Fictitious Facial Identity VQA dataset and apply a two-stage evaluation pipeline that is designed to precisely control the sources of information and their exposure levels. In terms of evaluation, since VLM supports various forms of ways to ask questions with the same semantic meaning, we also provide robust evaluation metrics including membership inference attacks and carefully designed adversarial privacy attacks to evaluate the performance of algorithms. Through the evaluation of four baseline VLM unlearning algorithms within FIUBench, we find that all methods remain limited in their unlearning performance, with significant trade-offs between model utility and forget quality. Furthermore, our findings also highlight the importance of privacy attacks for robust evaluations. We hope FIUBench will drive progress in developing more effective VLM unlearning algorithms.
Mitigating Fine-tuning Jailbreak Attack with Backdoor Enhanced Alignment
Feb 27, 2024



Despite the general capabilities of Large Language Models (LLMs) like GPT-4 and Llama-2, these models still request fine-tuning or adaptation with customized data when it comes to meeting the specific business demands and intricacies of tailored use cases. However, this process inevitably introduces new safety threats, particularly against the Fine-tuning based Jailbreak Attack (FJAttack), where incorporating just a few harmful examples into the fine-tuning dataset can significantly compromise the model safety. Though potential defenses have been proposed by incorporating safety examples into the fine-tuning dataset to reduce the safety issues, such approaches require incorporating a substantial amount of safety examples, making it inefficient. To effectively defend against the FJAttack with limited safety examples, we propose a Backdoor Enhanced Safety Alignment method inspired by an analogy with the concept of backdoor attacks. In particular, we construct prefixed safety examples by integrating a secret prompt, acting as a "backdoor trigger", that is prefixed to safety examples. Our comprehensive experiments demonstrate that through the Backdoor Enhanced Safety Alignment with adding as few as 11 prefixed safety examples, the maliciously fine-tuned LLMs will achieve similar safety performance as the original aligned models. Furthermore, we also explore the effectiveness of our method in a more practical setting where the fine-tuning data consists of both FJAttack examples and the fine-tuning task data. Our method shows great efficacy in defending against FJAttack without harming the performance of fine-tuning tasks.
Defending against Insertion-based Textual Backdoor Attacks via Attribution
May 03, 2023



Textual backdoor attack, as a novel attack model, has been shown to be effective in adding a backdoor to the model during training. Defending against such backdoor attacks has become urgent and important. In this paper, we propose AttDef, an efficient attribution-based pipeline to defend against two insertion-based poisoning attacks, BadNL and InSent. Specifically, we regard the tokens with larger attribution scores as potential triggers since larger attribution words contribute more to the false prediction results and therefore are more likely to be poison triggers. Additionally, we further utilize an external pre-trained language model to distinguish whether input is poisoned or not. We show that our proposed method can generalize sufficiently well in two common attack scenarios (poisoning training data and testing data), which consistently improves previous methods. For instance, AttDef can successfully mitigate both attacks with an average accuracy of 79.97% (56.59% up) and 48.34% (3.99% up) under pre-training and post-training attack defense respectively, achieving the new state-of-the-art performance on prediction recovery over four benchmark datasets.
ChatGPT as an Attack Tool: Stealthy Textual Backdoor Attack via Blackbox Generative Model Trigger
Apr 27, 2023



Textual backdoor attacks pose a practical threat to existing systems, as they can compromise the model by inserting imperceptible triggers into inputs and manipulating labels in the training dataset. With cutting-edge generative models such as GPT-4 pushing rewriting to extraordinary levels, such attacks are becoming even harder to detect. We conduct a comprehensive investigation of the role of black-box generative models as a backdoor attack tool, highlighting the importance of researching relative defense strategies. In this paper, we reveal that the proposed generative model-based attack, BGMAttack, could effectively deceive textual classifiers. Compared with the traditional attack methods, BGMAttack makes the backdoor trigger less conspicuous by leveraging state-of-the-art generative models. Our extensive evaluation of attack effectiveness across five datasets, complemented by three distinct human cognition assessments, reveals that Figure 4 achieves comparable attack performance while maintaining superior stealthiness relative to baseline methods.
PharmMT: A Neural Machine Translation Approach to Simplify Prescription Directions
Apr 08, 2022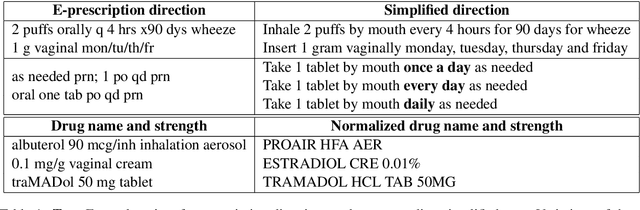
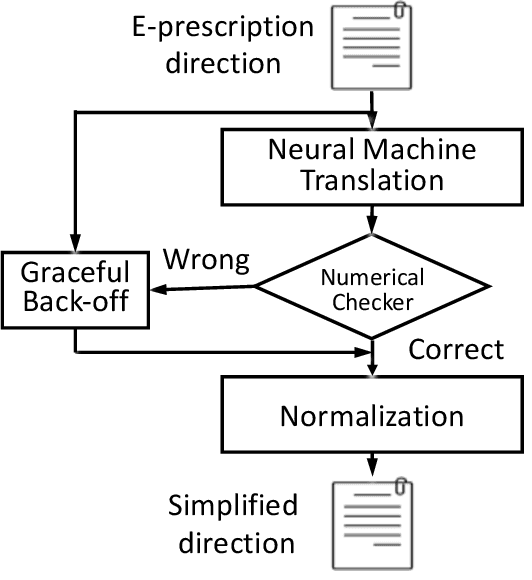
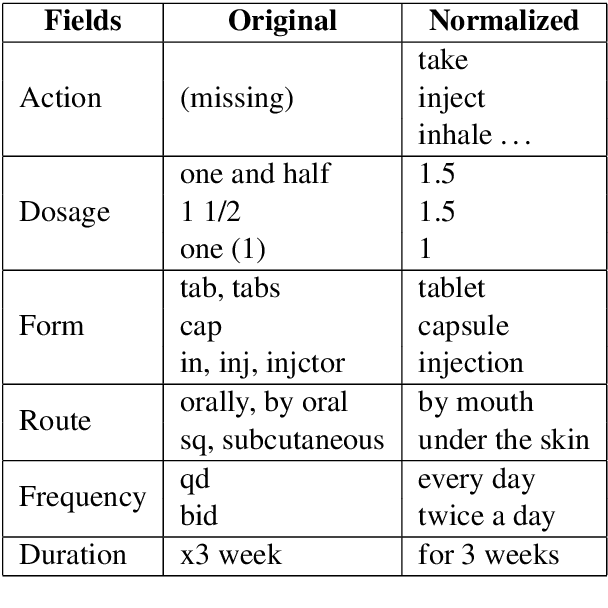

The language used by physicians and health professionals in prescription directions includes medical jargon and implicit directives and causes much confusion among patients. Human intervention to simplify the language at the pharmacies may introduce additional errors that can lead to potentially severe health outcomes. We propose a novel machine translation-based approach, PharmMT, to automatically and reliably simplify prescription directions into patient-friendly language, thereby significantly reducing pharmacist workload. We evaluate the proposed approach over a dataset consisting of over 530K prescriptions obtained from a large mail-order pharmacy. The end-to-end system achieves a BLEU score of 60.27 against the reference directions generated by pharmacists, a 39.6% relative improvement over the rule-based normalization. Pharmacists judged 94.3% of the simplified directions as usable as-is or with minimal changes. This work demonstrates the feasibility of a machine translation-based tool for simplifying prescription directions in real-life.
* Findings of EMNLP '20 Camera Ready