 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniConv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
Jul 09, 2025
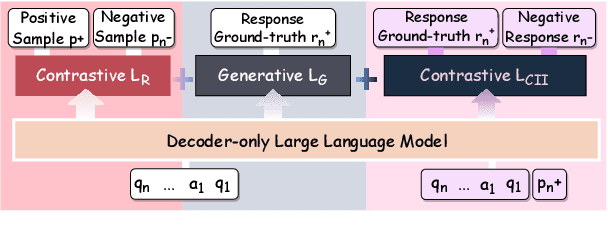
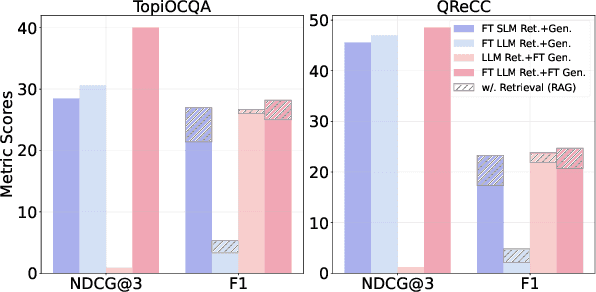
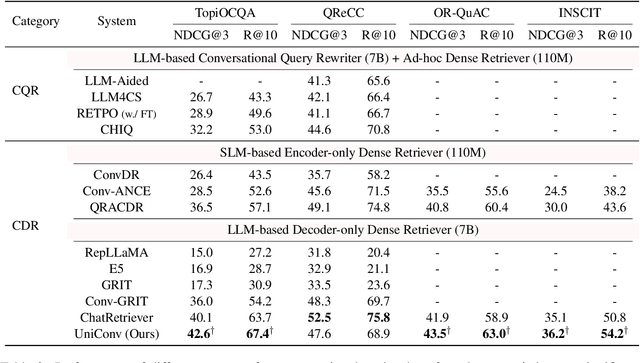
The rapid advancement of conversational search systems revolutionizes how information is accessed by enabling the multi-turn interaction between the user and the system. Existing conversational search systems are usually built with two different models. This separation restricts the system from leveraging the intrinsic knowledge of the models simultaneously, which cannot ensure the effectiveness of retrieval benefiting the generation. The existing studies for developing unified models cannot fully address the aspects of understanding conversational context, managing retrieval independently, and generating responses. In this paper, we explore how to unify dense retrieval and response generation for large language models in conversation. We conduct joint fine-tuning with different objectives and design two mechanisms to reduce the inconsistency risks while mitigating data discrepancy. The evaluations on five conversational search datasets demonstrate that our unified model can mutually improve both tasks and outperform the existing baselines.
Disparity Estimation Using a Quad-Pixel Sensor
Sep 01, 2024



A quad-pixel (QP) sensor is increasingly integrated into commercial mobile cameras. The QP sensor has a unit of 2$\times$2 four photodiodes under a single microlens, generating multi-directional phase shifting when out-focus blurs occur. Similar to a dual-pixel (DP) sensor, the phase shifting can be regarded as stereo disparity and utilized for depth estimation. Based on this, we propose a QP disparity estimation network (QPDNet), which exploits abundant QP information by fusing vertical and horizontal stereo-matching correlations for effective disparity estimation. We also present a synthetic pipeline to generate a training dataset from an existing RGB-Depth dataset. Experimental results demonstrate that our QPDNet outperforms state-of-the-art stereo and DP methods. Our code and synthetic dataset are available at https://github.com/Zhuofeng-Wu/QPDNet.
Self-Supervised Spatially Variant PSF Estimation for Aberration-Aware Depth-from-Defocus
Feb 28, 2024In this paper, we address the task of aberration-aware depth-from-defocus (DfD), which takes account of spatially variant point spread functions (PSFs) of a real camera. To effectively obtain the spatially variant PSFs of a real camera without requiring any ground-truth PSFs, we propose a novel self-supervised learning method that leverages the pair of real sharp and blurred images, which can be easily captured by changing the aperture setting of the camera. In our PSF estimation, we assume rotationally symmetric PSFs and introduce the polar coordinate system to more accurately learn the PSF estimation network. We also handle the focus breathing phenomenon that occurs in real DfD situations. Experimental results on synthetic and real data demonstrate the effectiveness of our method regarding both the PSF estimation and the depth estimation.
Divide-or-Conquer? Which Part Should You Distill Your LLM?
Feb 22, 2024



Recent methods have demonstrated that Large Language Models (LLMs) can solve reasoning tasks better when they are encouraged to solve subtasks of the main task first. In this paper we devise a similar strategy that breaks down reasoning tasks into a problem decomposition phase and a problem solving phase and show that the strategy is able to outperform a single stage solution. Further, we hypothesize that the decomposition should be easier to distill into a smaller model compared to the problem solving because the latter requires large amounts of domain knowledge while the former only requires learning general problem solving strategies. We propose methods to distill these two capabilities and evaluate their impact on reasoning outcomes and inference cost. We find that we can distill the problem decomposition phase and at the same time achieve good generalization across tasks, datasets, and models. However, it is harder to distill the problem solving capability without losing performance and the resulting distilled model struggles with generalization. These results indicate that by using smaller, distilled problem decomposition models in combination with problem solving LLMs we can achieve reasoning with cost-efficient inference and local adaptation.
HiCL: Hierarchical Contrastive Learning of Unsupervised Sentence Embeddings
Oct 15, 2023In this paper, we propose a hierarchical contrastive learning framework, HiCL, which considers local segment-level and global sequence-level relationships to improve training efficiency and effectiveness. Traditional methods typically encode a sequence in its entirety for contrast with others, often neglecting local representation learning, leading to challenges in generalizing to shorter texts. Conversely, HiCL improves its effectiveness by dividing the sequence into several segments and employing both local and global contrastive learning to model segment-level and sequence-level relationships. Further, considering the quadratic time complexity of transformers over input tokens, HiCL boosts training efficiency by first encoding short segments and then aggregating them to obtain the sequence representation. Extensive experiments show that HiCL enhances the prior top-performing SNCSE model across seven extensively evaluated STS tasks, with an average increase of +0.2% observed on BERT-large and +0.44% on RoBERTa-large.
PLANNER: Generating Diversified Paragraph via Latent Language Diffusion Model
Jun 05, 2023



Autoregressive models for text sometimes generate repetitive and low-quality output because errors accumulate during the steps of generation. This issue is often attributed to exposure bias - the difference between how a model is trained, and how it is used during inference. Denoising diffusion models provide an alternative approach in which a model can revisit and revise its output. However, they can be computationally expensive and prior efforts on text have led to models that produce less fluent output compared to autoregressive models, especially for longer text and paragraphs. In this paper, we propose PLANNER, a model that combines latent semantic diffusion with autoregressive generation, to generate fluent text while exercising global control over paragraphs. The model achieves this by combining an autoregressive "decoding" module with a "planning" module that uses latent diffusion to generate semantic paragraph embeddings in a coarse-to-fine manner. The proposed method is evaluated on various conditional generation tasks, and results on semantic generation, text completion and summarization show its effectiveness in generating high-quality long-form text in an efficient manner.
Defending against Insertion-based Textual Backdoor Attacks via Attribution
May 03, 2023



Textual backdoor attack, as a novel attack model, has been shown to be effective in adding a backdoor to the model during training. Defending against such backdoor attacks has become urgent and important. In this paper, we propose AttDef, an efficient attribution-based pipeline to defend against two insertion-based poisoning attacks, BadNL and InSent. Specifically, we regard the tokens with larger attribution scores as potential triggers since larger attribution words contribute more to the false prediction results and therefore are more likely to be poison triggers. Additionally, we further utilize an external pre-trained language model to distinguish whether input is poisoned or not. We show that our proposed method can generalize sufficiently well in two common attack scenarios (poisoning training data and testing data), which consistently improves previous methods. For instance, AttDef can successfully mitigate both attacks with an average accuracy of 79.97% (56.59% up) and 48.34% (3.99% up) under pre-training and post-training attack defense respectively, achieving the new state-of-the-art performance on prediction recovery over four benchmark datasets.
ChatGPT as an Attack Tool: Stealthy Textual Backdoor Attack via Blackbox Generative Model Trigger
Apr 27, 2023



Textual backdoor attacks pose a practical threat to existing systems, as they can compromise the model by inserting imperceptible triggers into inputs and manipulating labels in the training dataset. With cutting-edge generative models such as GPT-4 pushing rewriting to extraordinary levels, such attacks are becoming even harder to detect. We conduct a comprehensive investigation of the role of black-box generative models as a backdoor attack tool, highlighting the importance of researching relative defense strategies. In this paper, we reveal that the proposed generative model-based attack, BGMAttack, could effectively deceive textual classifiers. Compared with the traditional attack methods, BGMAttack makes the backdoor trigger less conspicuous by leveraging state-of-the-art generative models. Our extensive evaluation of attack effectiveness across five datasets, complemented by three distinct human cognition assessments, reveals that Figure 4 achieves comparable attack performance while maintaining superior stealthiness relative to baseline methods.
IDPG: An Instance-Dependent Prompt Generation Method
Apr 09, 2022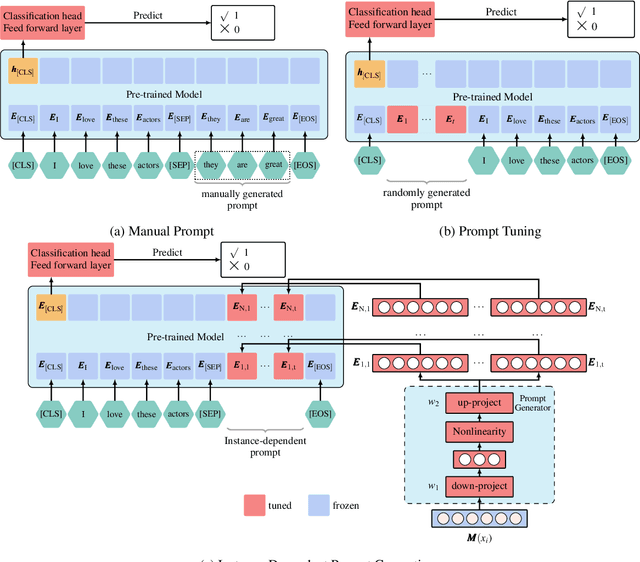
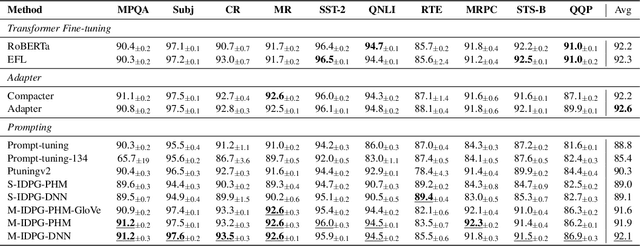

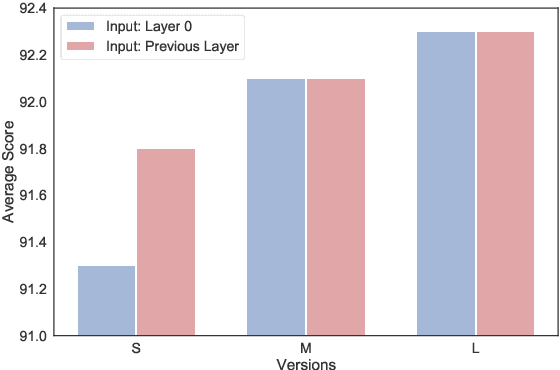
Prompt tuning is a new, efficient NLP transfer learning paradigm that adds a task-specific prompt in each input instance during the model training stage. It freezes the pre-trained language model and only optimizes a few task-specific prompts. In this paper, we propose a conditional prompt generation method to generate prompts for each input instance, referred to as the Instance-Dependent Prompt Generation (IDPG). Unlike traditional prompt tuning methods that use a fixed prompt, IDPG introduces a lightweight and trainable component to generate prompts based on each input sentence. Extensive experiments on ten natural language understanding (NLU) tasks show that the proposed strategy consistently outperforms various prompt tuning baselines and is on par with other efficient transfer learning methods such as Compacter while tuning far fewer model parameters.
CLEAR: Contrastive Learning for Sentence Representation
Dec 31, 2020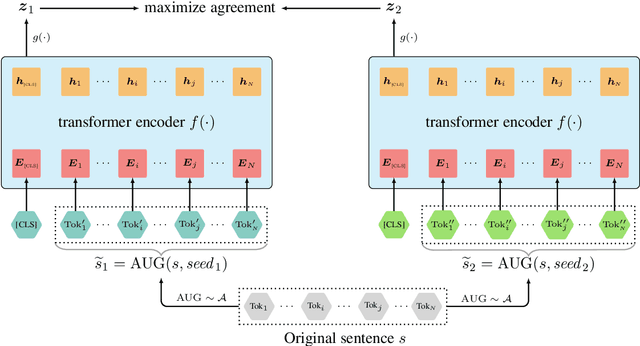



Pre-trained language models have proven their unique powers in capturing implicit language features. However, most pre-training approaches focus on the word-level training objective, while sentence-level objectives are rarely studied. In this paper, we propose Contrastive LEArning for sentence Representation (CLEAR), which employs multiple sentence-level augmentation strategies in order to learn a noise-invariant sentence representation. These augmentations include word and span deletion, reordering, and substitution. Furthermore, we investigate the key reasons that make contrastive learning effective through numerous experiments. We observe that different sentence augmentations during pre-training lead to different performance improvements on various downstream tasks. Our approach is shown to outperform multiple existing methods on both SentEval and GLUE benchmarks.