 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenMRP: A Generative Multi-Route Planning Framework for Efficient and Personalized Real-Time Industrial Navigation
Feb 04, 2026Existing industrial-scale navigation applications contend with massive road networks, typically employing two main categories of approaches for route planning. The first relies on precomputed road costs for optimal routing and heuristic algorithms for generating alternatives, while the second, generative methods, has recently gained significant attention. However, the former struggles with personalization and route diversity, while the latter fails to meet the efficiency requirements of large-scale real-time scenarios. To address these limitations, we propose GenMRP, a generative framework for multi-route planning. To ensure generation efficiency, GenMRP first introduces a skeleton-to-capillary approach that dynamically constructs a relevant sub-network significantly smaller than the full road network. Within this sub-network, routes are generated iteratively. The first iteration identifies the optimal route, while the subsequent ones generate alternatives that balance quality and diversity using the newly proposed correctional boosting approach. Each iteration incorporates road features, user historical sequences, and previously generated routes into a Link Cost Model to update road costs, followed by route generation using the Dijkstra algorithm. Extensive experiments show that GenMRP achieves state-of-the-art performance with high efficiency in both offline and online environments. To facilitate further research, we have publicly released the training and evaluation dataset. GenMRP has been fully deployed in a real-world navigation app, demonstrating its effectiveness and benefits.
Exploiting inter-agent coupling information for efficient reinforcement learning of cooperative LQR
Apr 29, 2025

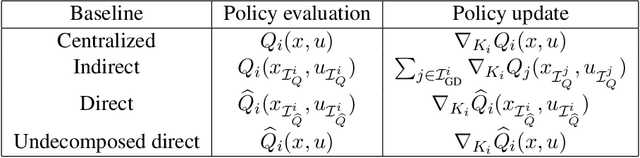

Developing scalable and efficient reinforcement learning algorithms for cooperative multi-agent control has received significant attention over the past years. Existing literature has proposed inexact decompositions of local Q-functions based on empirical information structures between the agents. In this paper, we exploit inter-agent coupling information and propose a systematic approach to exactly decompose the local Q-function of each agent. We develop an approximate least square policy iteration algorithm based on the proposed decomposition and identify two architectures to learn the local Q-function for each agent. We establish that the worst-case sample complexity of the decomposition is equal to the centralized case and derive necessary and sufficient graphical conditions on the inter-agent couplings to achieve better sample efficiency. We demonstrate the improved sample efficiency and computational efficiency on numerical examples.
Training Bilingual LMs with Data Constraints in the Targeted Language
Nov 20, 2024



Large language models are trained on massive scrapes of the web, as required by current scaling laws. Most progress is made for English, given its abundance of high-quality pretraining data. For most other languages, however, such high quality pretraining data is unavailable. In this work, we study how to boost pretrained model performance in a data constrained target language by enlisting data from an auxiliary language for which high quality data is available. We study this by quantifying the performance gap between training with data in a data-rich auxiliary language compared with training in the target language, exploring the benefits of translation systems, studying the limitations of model scaling for data constrained languages, and proposing new methods for upsampling data from the auxiliary language. Our results show that stronger auxiliary datasets result in performance gains without modification to the model or training objective for close languages, and, in particular, that performance gains due to the development of more information-rich English pretraining datasets can extend to targeted language settings with limited data.
Impact of Tactile Sensor Quantities and Placements on Learning-based Dexterous Manipulation
Sep 30, 2024



Tactile information effectively enables faster training and better task performance for learning-based in-hand manipulation. Existing approaches are validated in simulated environments with a large number of tactile sensors. However, attaching such sensors to a real robot hand is not applicable due to high cost and physical limitations. To enable real-world adoption of tactile sensors, this study investigates the impact of tactile sensors, including their varying quantities and placements on robot hands, on the dexterous manipulation task performance and analyzes the importance of each. Through empirically decreasing the sensor quantities, we successfully find an optimized set of tactile sensors (21 sensors) configuration, which keeps over 93% task performance with only 20% sensor quantities compared to the original set (92 sensors) for the block manipulation task, leading to a potential reduction of over 80% in sensor manufacturing and design costs. To transform the empirical results into a generalizable understanding, we build a task performance prediction model with a weighted linear regression algorithm and use it to forecast the task performance with different sensor configurations. To show its generalizability, we verified this model in egg and pen manipulation tasks and achieved an average prediction error of 3.12%.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Real-time Dexterous Telemanipulation with an End-Effect-Oriented Learning-based Approach
Aug 01, 2024



Dexterous telemanipulation is crucial in advancing human-robot systems, especially in tasks requiring precise and safe manipulation. However, it faces significant challenges due to the physical differences between human and robotic hands, the dynamic interaction with objects, and the indirect control and perception of the remote environment. Current approaches predominantly focus on mapping the human hand onto robotic counterparts to replicate motions, which exhibits a critical oversight: it often neglects the physical interaction with objects and relegates the interaction burden to the human to adapt and make laborious adjustments in response to the indirect and counter-intuitive observation of the remote environment. This work develops an End-Effects-Oriented Learning-based Dexterous Telemanipulation (EFOLD) framework to address telemanipulation tasks. EFOLD models telemanipulation as a Markov Game, introducing multiple end-effect features to interpret the human operator's commands during interaction with objects. These features are used by a Deep Reinforcement Learning policy to control the robot and reproduce such end effects. EFOLD was evaluated with real human subjects and two end-effect extraction methods for controlling a virtual Shadow Robot Hand in telemanipulation tasks. EFOLD achieved real-time control capability with low command following latency (delay<0.11s) and highly accurate tracking (MSE<0.084 rad).
dMel: Speech Tokenization made Simple
Jul 22, 2024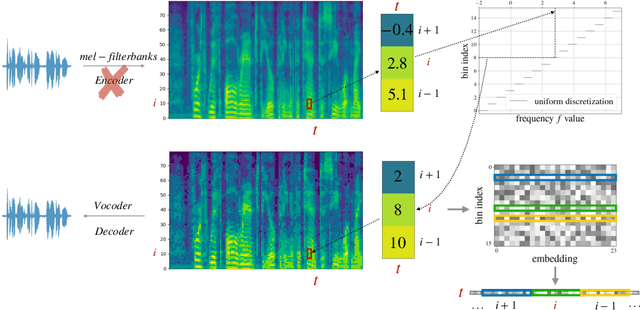

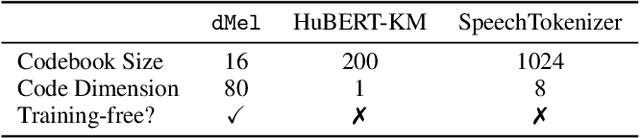
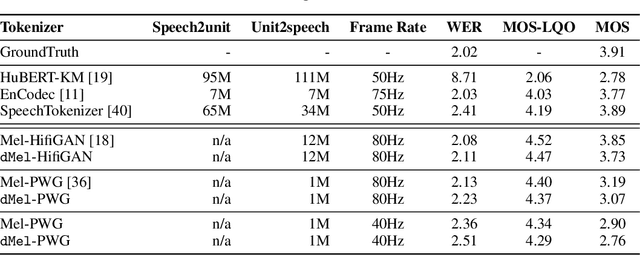
Large language models have revolutionized natural language processing by leveraging self-supervised pretraining on vast textual data. Inspired by this success, researchers have investigated complicated speech tokenization methods to discretize continuous speech signals so that language modeling techniques can be applied to speech data. However, existing approaches either model semantic tokens, potentially losing acoustic information, or model acoustic tokens, risking the loss of semantic information. Having multiple token types also complicates the architecture and requires additional pretraining. Here we show that discretizing mel-filterbank channels into discrete intensity bins produces a simple representation (dMel), that performs better than other existing speech tokenization methods. Using a transformer decoder-only architecture for speech-text modeling, we comprehensively evaluate different speech tokenization methods on speech recognition (ASR), speech synthesis (TTS). Our results demonstrate the effectiveness of dMel in achieving high performance on both tasks within a unified framework, paving the way for efficient and effective joint modeling of speech and text.
Denoising LM: Pushing the Limits of Error Correction Models for Speech Recognition
May 24, 2024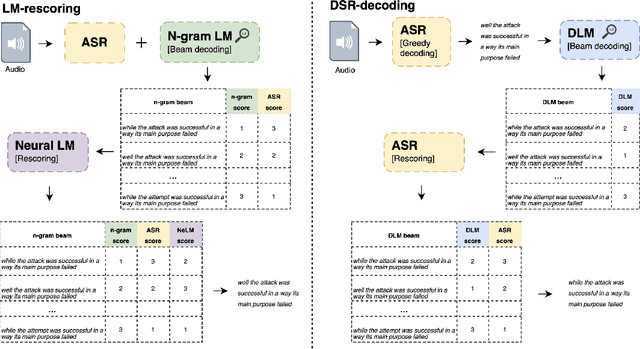
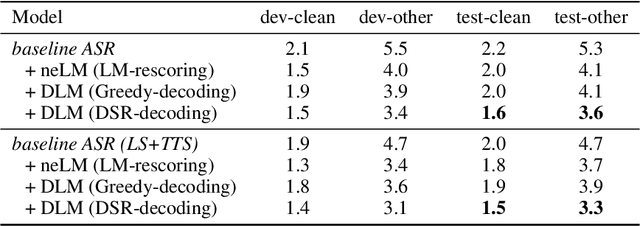

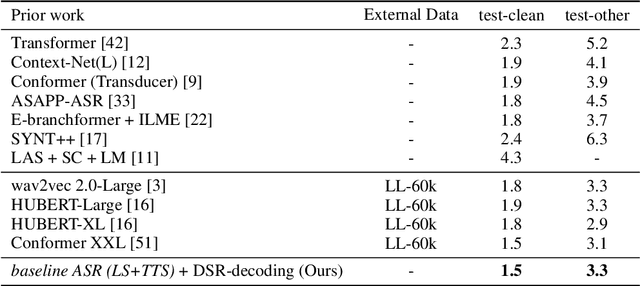
Language models (LMs) have long been used to improve results of automatic speech recognition (ASR) systems, but they are unaware of the errors that ASR systems make. Error correction models are designed to fix ASR errors, however, they showed little improvement over traditional LMs mainly due to the lack of supervised training data. In this paper, we present Denoising LM (DLM), which is a $\textit{scaled}$ error correction model trained with vast amounts of synthetic data, significantly exceeding prior attempts meanwhile achieving new state-of-the-art ASR performance. We use text-to-speech (TTS) systems to synthesize audio, which is fed into an ASR system to produce noisy hypotheses, which are then paired with the original texts to train the DLM. DLM has several $\textit{key ingredients}$: (i) up-scaled model and data; (ii) usage of multi-speaker TTS systems; (iii) combination of multiple noise augmentation strategies; and (iv) new decoding techniques. With a Transformer-CTC ASR, DLM achieves 1.5% word error rate (WER) on $\textit{test-clean}$ and 3.3% WER on $\textit{test-other}$ on Librispeech, which to our knowledge are the best reported numbers in the setting where no external audio data are used and even match self-supervised methods which use external audio data. Furthermore, a single DLM is applicable to different ASRs, and greatly surpassing the performance of conventional LM based beam-search rescoring. These results indicate that properly investigated error correction models have the potential to replace conventional LMs, holding the key to a new level of accuracy in ASR systems.
How Far Are We from Intelligent Visual Deductive Reasoning?
Mar 08, 2024
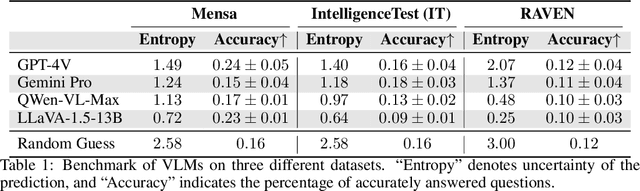
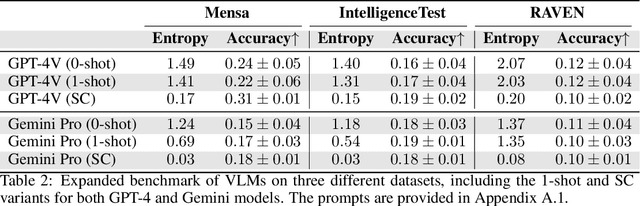
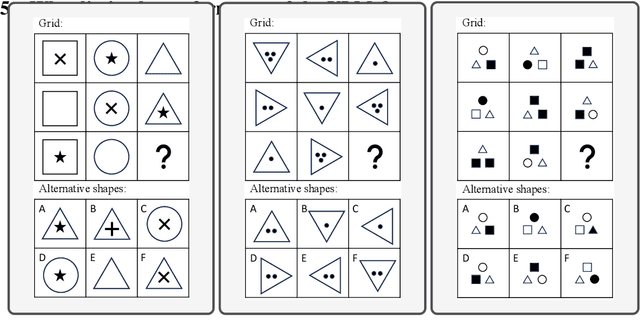
Vision-Language Models (VLMs) such as GPT-4V have recently demonstrated incredible strides on diverse vision language tasks. We dig into vision-based deductive reasoning, a more sophisticated but less explored realm, and find previously unexposed blindspots in the current SOTA VLMs. Specifically, we leverage Raven's Progressive Matrices (RPMs), to assess VLMs' abilities to perform multi-hop relational and deductive reasoning relying solely on visual clues. We perform comprehensive evaluations of several popular VLMs employing standard strategies such as in-context learning, self-consistency, and Chain-of-thoughts (CoT) on three diverse datasets, including the Mensa IQ test, IntelligenceTest, and RAVEN. The results reveal that despite the impressive capabilities of LLMs in text-based reasoning, we are still far from achieving comparable proficiency in visual deductive reasoning. We found that certain standard strategies that are effective when applied to LLMs do not seamlessly translate to the challenges presented by visual reasoning tasks. Moreover, a detailed analysis reveals that VLMs struggle to solve these tasks mainly because they are unable to perceive and comprehend multiple, confounding abstract patterns in RPM examples.
Divide-or-Conquer? Which Part Should You Distill Your LLM?
Feb 22, 2024



Recent methods have demonstrated that Large Language Models (LLMs) can solve reasoning tasks better when they are encouraged to solve subtasks of the main task first. In this paper we devise a similar strategy that breaks down reasoning tasks into a problem decomposition phase and a problem solving phase and show that the strategy is able to outperform a single stage solution. Further, we hypothesize that the decomposition should be easier to distill into a smaller model compared to the problem solving because the latter requires large amounts of domain knowledge while the former only requires learning general problem solving strategies. We propose methods to distill these two capabilities and evaluate their impact on reasoning outcomes and inference cost. We find that we can distill the problem decomposition phase and at the same time achieve good generalization across tasks, datasets, and models. However, it is harder to distill the problem solving capability without losing performance and the resulting distilled model struggles with generalization. These results indicate that by using smaller, distilled problem decomposition models in combination with problem solving LLMs we can achieve reasoning with cost-efficient inference and local adaptation.