 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Knowledge Transfer under Data Constraints via Lexical Interventions
May 22, 2026Cross-lingual knowledge transfer is critical for building high-performing multilingual language models for languages with insufficient training data. When target language data is scarce, the knowledge required for many downstream tasks involving scientific reasoning, commonsense inference, and world knowledge must be acquired primarily from the high-resource language, making effective knowledge transfer essential. Existing methods for improving such cross-lingual knowledge transfer require large amounts of parallel data, translation systems, auxiliary models, or additional training stages that are largely unavailable for many languages. We propose LINK - a data-level intervention method that improves knowledge transfer during model pretraining through lexical substitutions in high-resource part of pretraining data using bilingual vocabularies. For a given replacement ratio, randomly selected words in a portion of the high-resource (English) training corpus are swapped with their word-level translations, requiring no additional model training and only a bilingual vocabulary, which can be obtained at near-zero cost for virtually any language. Evaluation on eight languages across five model sizes shows notable improvements on downstream tasks in the target language, with up to a 2x speedup in training to reach equivalent performance.
Mix, Don't Tune: Bilingual Pre-Training Outperforms Hyperparameter Search in Data-Constrained Settings
May 13, 2026For most languages of the world, language model pre-training operates in a data-constrained regime where models must repeat their training data many times, degrading generalization. Two remedies exist: aggressive hyperparameter tuning such as high weight decay, and mixing in data from a high-resource auxiliary language to directly aid the low-resource target. While hyperparameter tuning regularizes the model by shrinking weights to restrict network capacity, auxiliary data mixing uses a tunable mixing ratio to expand the training distribution and diversify the training signal with new knowledge. Both offer a principled way to improve training in a data-constrained domain. We compare these levers systematically across four model scales from 150M to 1.43B parameters, using Arabic as the low-resource target and English as the auxiliary, over approximately 1000 pre-training runs. Three findings emerge. First, mixing yields larger improvements than hyperparameter tuning on both validation loss and downstream task accuracy, and the gap grows with model size. Second, we quantify how much mixing helps: it boosts performance by an amount equivalent to 2--3$\times$ the unique target data on validation loss and 2--13$\times$ on downstream task accuracy, with the gain scaling steeply with model size. Third, this divergence reveals that target-language validation loss systematically underestimates mixing's value. Mixing regularizes by diversifying the training signal and contributes knowledge the repeated target corpus cannot supply; validation loss captures only the first effect. Our practical recommendations are: mix in a high-resource language, prioritize the mixing ratio over hyperparameter tuning, and transfer hyperparameters from a small proxy model via $μ$P.
Scaling Laws for Mixture Pretraining Under Data Constraints
May 12, 2026As language models scale, the amount of data they require grows -- yet many target data sources, such as low-resource languages or specialized domains, are inherently limited in size. A common strategy is to mix this scarce but valuable target data with abundant generic data, which presents a fundamental trade-off: too little target data in the mixture underexposes the model to the target domain, while too much target data repeats the same examples excessively, yielding diminishing returns and eventual overfitting. We study this trade-off across more than 2,000 language-model training runs spanning multiple model and target dataset sizes, as well as several data types, including multilingual, domain-specific, and quality-filtered mixtures. Across all settings, we find that repetition is a central driver of target-domain performance, and that mixture training tolerates much higher repetition than single-source training: scarce target corpora can be reused 15-20 times, with the optimal number of repetitions depending on the target data size, compute budget, and model scale. Next, we introduce a repetition-aware mixture scaling law that accounts for the decreasing value of repeated target tokens and the regularizing role of generic data. Optimizing the scaling law provides a principled way to compute effective mixture configurations, yielding practical mixture recommendations for pretraining under data constraints.
Pitch Accent Detection improves Pretrained Automatic Speech Recognition
Aug 06, 2025We show the performance of Automatic Speech Recognition (ASR) systems that use semi-supervised speech representations can be boosted by a complimentary pitch accent detection module, by introducing a joint ASR and pitch accent detection model. The pitch accent detection component of our model achieves a significant improvement on the state-of-the-art for the task, closing the gap in F1-score by 41%. Additionally, the ASR performance in joint training decreases WER by 28.3% on LibriSpeech, under limited resource fine-tuning. With these results, we show the importance of extending pretrained speech models to retain or re-learn important prosodic cues such as pitch accent.
Discriminating Form and Meaning in Multilingual Models with Minimal-Pair ABX Tasks
May 23, 2025We introduce a set of training-free ABX-style discrimination tasks to evaluate how multilingual language models represent language identity (form) and semantic content (meaning). Inspired from speech processing, these zero-shot tasks measure whether minimal differences in representation can be reliably detected. This offers a flexible and interpretable alternative to probing. Applied to XLM-R (Conneau et al, 2020) across pretraining checkpoints and layers, we find that language discrimination declines over training and becomes concentrated in lower layers, while meaning discrimination strengthens over time and stabilizes in deeper layers. We then explore probing tasks, showing some alignment between our metrics and linguistic learning performance. Our results position ABX tasks as a lightweight framework for analyzing the structure of multilingual representations.
The Role of Prosody in Spoken Question Answering
Feb 08, 2025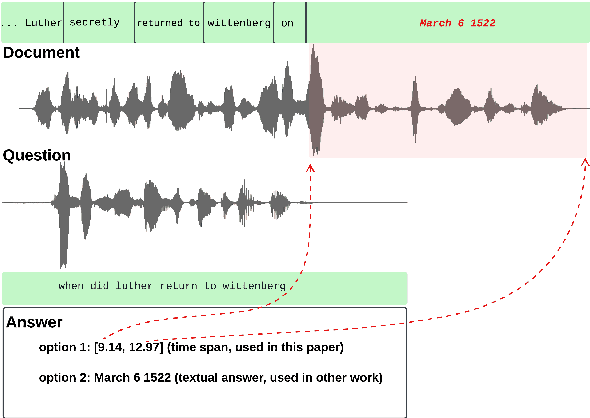
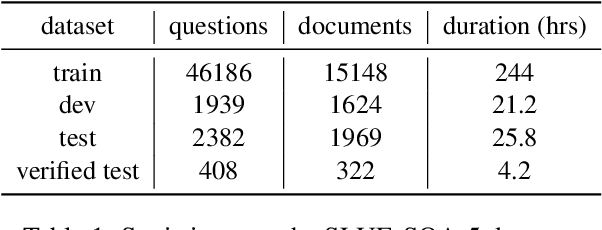
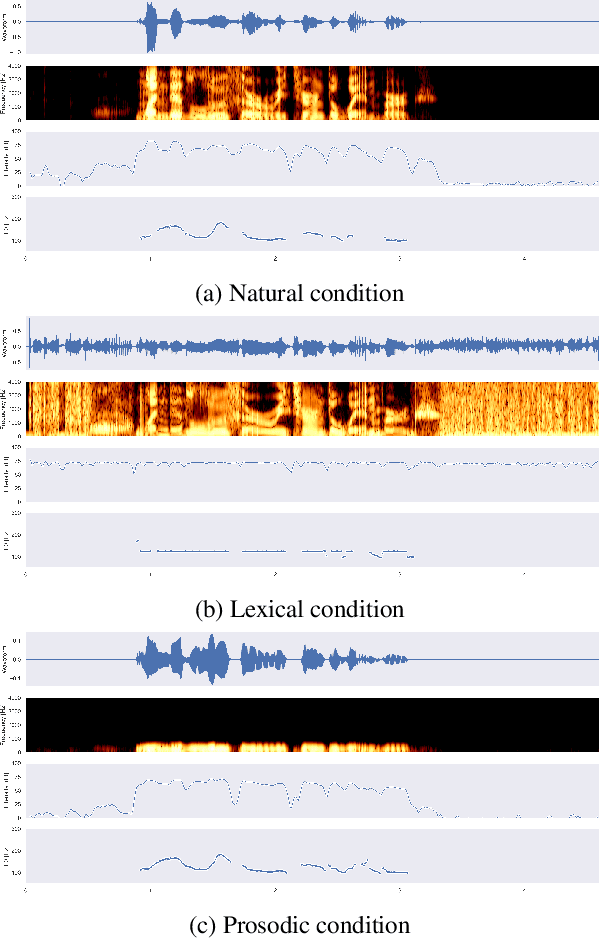
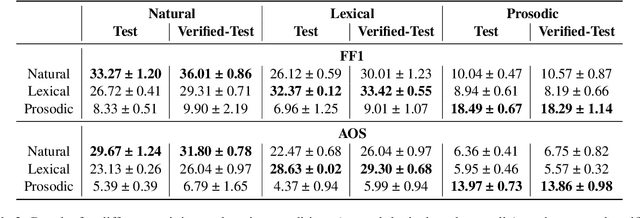
Spoken language understanding research to date has generally carried a heavy text perspective. Most datasets are derived from text, which is then subsequently synthesized into speech, and most models typically rely on automatic transcriptions of speech. This is to the detriment of prosody--additional information carried by the speech signal beyond the phonetics of the words themselves and difficult to recover from text alone. In this work, we investigate the role of prosody in Spoken Question Answering. By isolating prosodic and lexical information on the SLUE-SQA-5 dataset, which consists of natural speech, we demonstrate that models trained on prosodic information alone can perform reasonably well by utilizing prosodic cues. However, we find that when lexical information is available, models tend to predominantly rely on it. Our findings suggest that while prosodic cues provide valuable supplementary information, more effective integration methods are required to ensure prosody contributes more significantly alongside lexical features.
Training Bilingual LMs with Data Constraints in the Targeted Language
Nov 20, 2024



Large language models are trained on massive scrapes of the web, as required by current scaling laws. Most progress is made for English, given its abundance of high-quality pretraining data. For most other languages, however, such high quality pretraining data is unavailable. In this work, we study how to boost pretrained model performance in a data constrained target language by enlisting data from an auxiliary language for which high quality data is available. We study this by quantifying the performance gap between training with data in a data-rich auxiliary language compared with training in the target language, exploring the benefits of translation systems, studying the limitations of model scaling for data constrained languages, and proposing new methods for upsampling data from the auxiliary language. Our results show that stronger auxiliary datasets result in performance gains without modification to the model or training objective for close languages, and, in particular, that performance gains due to the development of more information-rich English pretraining datasets can extend to targeted language settings with limited data.
GrammaMT: Improving Machine Translation with Grammar-Informed In-Context Learning
Oct 24, 2024We introduce GrammaMT, a grammatically-aware prompting approach for machine translation that uses Interlinear Glossed Text (IGT), a common form of linguistic description providing morphological and lexical annotations for source sentences. GrammaMT proposes three prompting strategies: gloss-shot, chain-gloss and model-gloss. All are training-free, requiring only a few examples that involve minimal effort to collect, and making them well-suited for low-resource setups. Experiments show that GrammaMT enhances translation performance on open-source instruction-tuned LLMs for various low- to high-resource languages across three benchmarks: (1) the largest IGT corpus, (2) the challenging 2023 SIGMORPHON Shared Task data over endangered languages, and (3) even in an out-of-domain setting with FLORES. Moreover, ablation studies reveal that leveraging gloss resources could substantially boost MT performance (by over 17 BLEU points) if LLMs accurately generate or access input sentence glosses.
Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
Sep 20, 2023



Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.
High-Resource Methodological Bias in Low-Resource Investigations
Nov 14, 2022The central bottleneck for low-resource NLP is typically regarded to be the quantity of accessible data, overlooking the contribution of data quality. This is particularly seen in the development and evaluation of low-resource systems via down sampling of high-resource language data. In this work we investigate the validity of this approach, and we specifically focus on two well-known NLP tasks for our empirical investigations: POS-tagging and machine translation. We show that down sampling from a high-resource language results in datasets with different properties than the low-resource datasets, impacting the model performance for both POS-tagging and machine translation. Based on these results we conclude that naive down sampling of datasets results in a biased view of how well these systems work in a low-resource scenario.