 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith Good MT There is No Need For End-to-End: A Case for Translate-then-Summarize Cross-lingual Summarization
Aug 31, 2024


Recent work has suggested that end-to-end system designs for cross-lingual summarization are competitive solutions that perform on par or even better than traditional pipelined designs. A closer look at the evidence reveals that this intuition is based on the results of only a handful of languages or using underpowered pipeline baselines. In this work, we compare these two paradigms for cross-lingual summarization on 39 source languages into English and show that a simple \textit{translate-then-summarize} pipeline design consistently outperforms even an end-to-end system with access to enormous amounts of parallel data. For languages where our pipeline model does not perform well, we show that system performance is highly correlated with publicly distributed BLEU scores, allowing practitioners to establish the feasibility of a language pair a priori. Contrary to recent publication trends, our result suggests that the combination of individual progress of monolingual summarization and translation tasks offers better performance than an end-to-end system, suggesting that end-to-end designs should be considered with care.
Experimental Standards for Deep Learning Research: A Natural Language Processing Perspective
Apr 13, 2022

The field of Deep Learning (DL) has undergone explosive growth during the last decade, with a substantial impact on Natural Language Processing (NLP) as well. Yet, as with other fields employing DL techniques, there has been a lack of common experimental standards compared to more established disciplines. Starting from fundamental scientific principles, we distill ongoing discussions on experimental standards in DL into a single, widely-applicable methodology. Following these best practices is crucial to strengthening experimental evidence, improve reproducibility and enable scientific progress. These standards are further collected in a public repository to help them transparently adapt to future needs.
The Danish Gigaword Project
May 08, 2020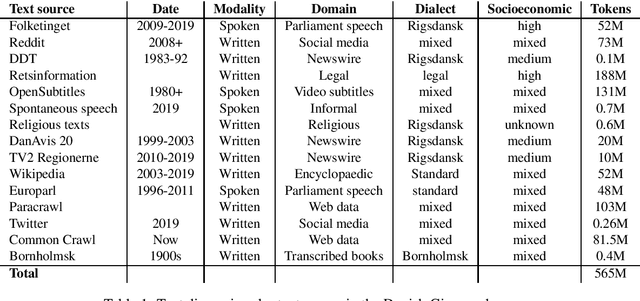
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.
UniParse: A universal graph-based parsing toolkit
Jul 11, 2018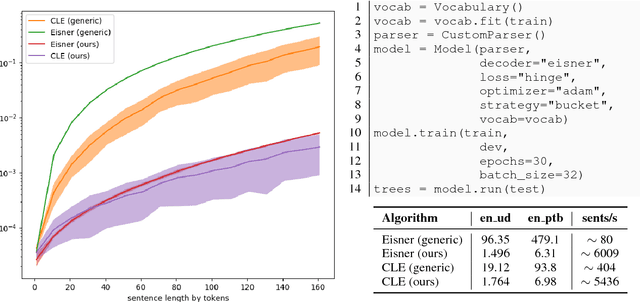
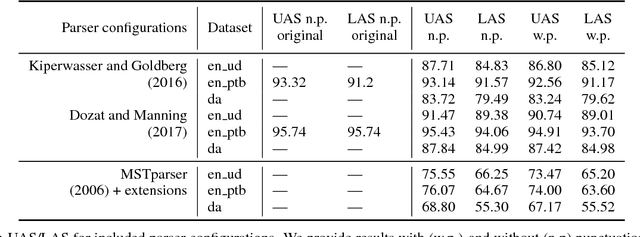
This paper describes the design and use of the graph-based parsing framework and toolkit UniParse, released as an open-source python software package. UniParse as a framework novelly streamlines research prototyping, development and evaluation of graph-based dependency parsing architectures. UniParse does this by enabling highly efficient, sufficiently independent, easily readable, and easily extensible implementations for all dependency parser components. We distribute the toolkit with ready-made configurations as re-implementations of all current state-of-the-art first-order graph-based parsers, including even more efficient Cython implementations of both encoders and decoders, as well as the required specialised loss functions.