 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-to-Sequence Methods in Machine Learning: a Review
Mar 17, 2021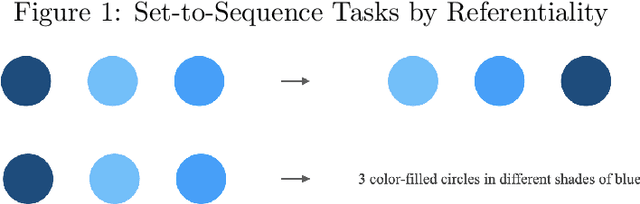
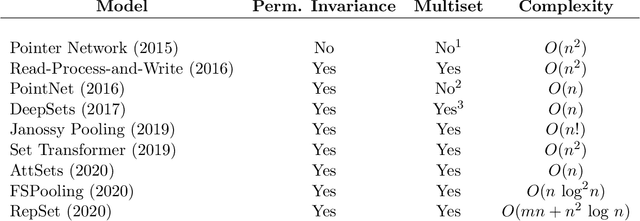
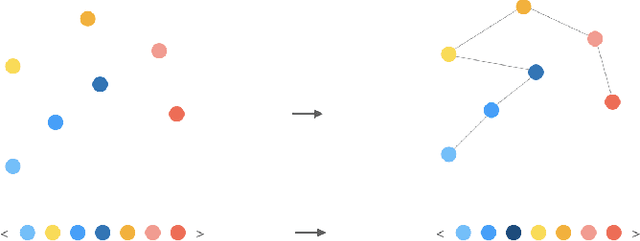
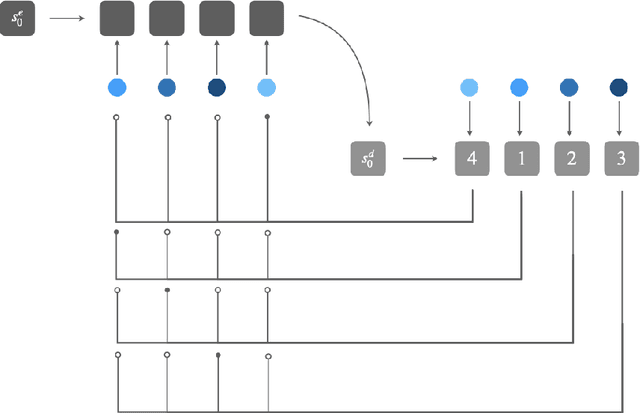
Machine learning on sets towards sequential output is an important and ubiquitous task, with applications ranging from language modelling and meta-learning to multi-agent strategy games and power grid optimization. Combining elements of representation learning and structured prediction, its two primary challenges include obtaining a meaningful, permutation invariant set representation and subsequently utilizing this representation to output a complex target permutation. This paper provides a comprehensive introduction to the field as well as an overview of important machine learning methods tackling both of these key challenges, with a detailed qualitative comparison of selected model architectures.
The Danish Gigaword Project
May 08, 2020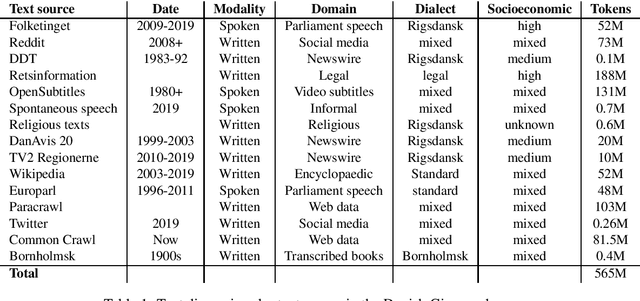
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.