 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANSK and DaCy 2.6.0: Domain Generalization of Danish Named Entity Recognition
Feb 28, 2024Named entity recognition is one of the cornerstones of Danish NLP, essential for language technology applications within both industry and research. However, Danish NER is inhibited by a lack of available datasets. As a consequence, no current models are capable of fine-grained named entity recognition, nor have they been evaluated for potential generalizability issues across datasets and domains. To alleviate these limitations, this paper introduces: 1) DANSK: a named entity dataset providing for high-granularity tagging as well as within-domain evaluation of models across a diverse set of domains; 2) DaCy 2.6.0 that includes three generalizable models with fine-grained annotation; and 3) an evaluation of current state-of-the-art models' ability to generalize across domains. The evaluation of existing and new models revealed notable performance discrepancies across domains, which should be addressed within the field. Shortcomings of the annotation quality of the dataset and its impact on model training and evaluation are also discussed. Despite these limitations, we advocate for the use of the new dataset DANSK alongside further work on the generalizability within Danish NER.
Natural Language Processing 4 All : A New Online Platform for Teaching and Learning NLP Concepts
May 28, 2021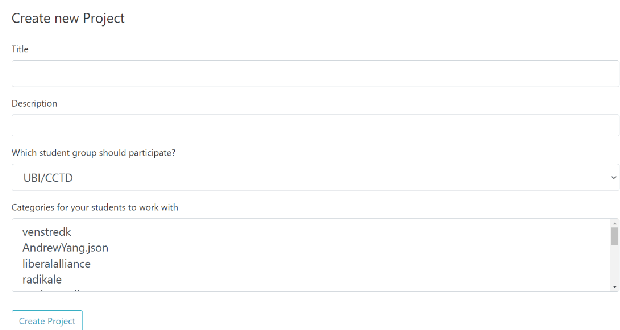
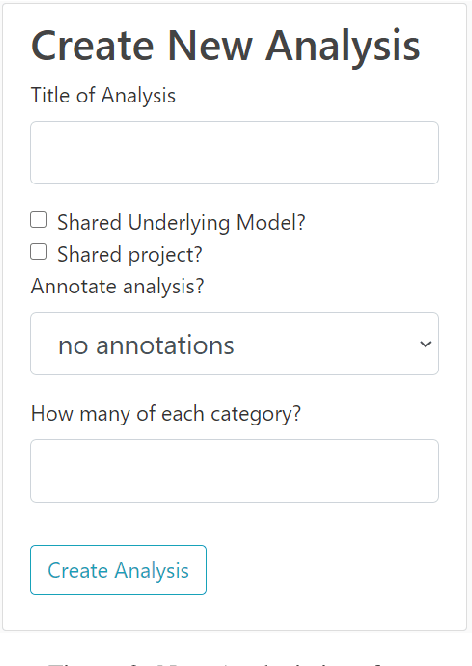
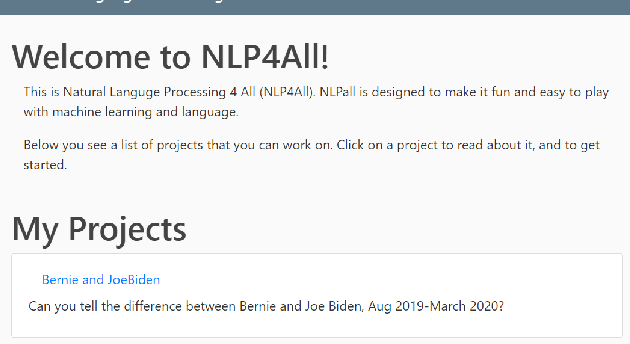
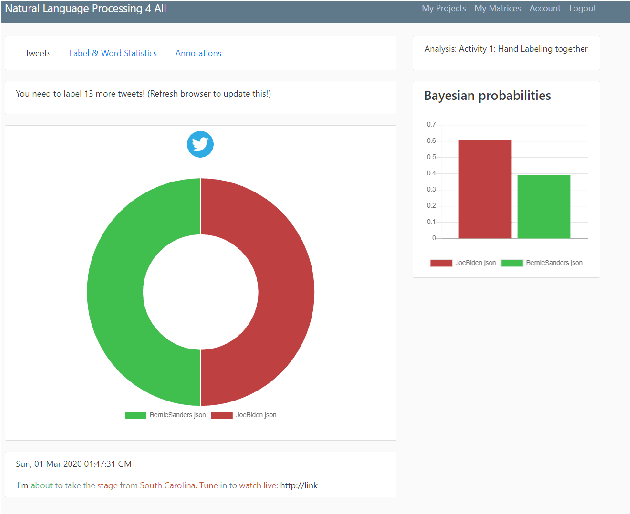
Natural Language Processing offers new insights into language data across almost all disciplines and domains, and allows us to corroborate and/or challenge existing knowledge. The primary hurdles to widening participation in and use of these new research tools are, first, a lack of coding skills in students across K-16, and in the population at large, and second, a lack of knowledge of how NLP-methods can be used to answer questions of disciplinary interest outside of linguistics and/or computer science. To broaden participation in NLP and improve NLP-literacy, we introduced a new tool web-based tool called Natural Language Processing 4 All (NLP4All). The intended purpose of NLP4All is to help teachers facilitate learning with and about NLP, by providing easy-to-use interfaces to NLP-methods, data, and analyses, making it possible for non- and novice-programmers to learn NLP concepts interactively.
The Danish Gigaword Project
May 08, 2020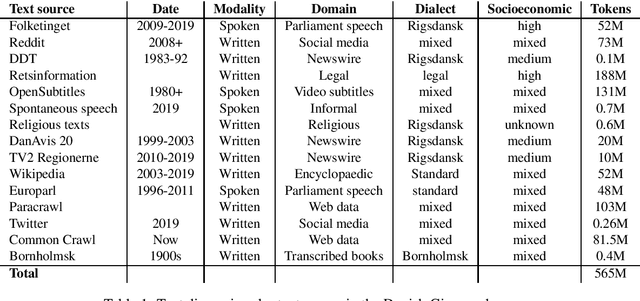
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.