 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT Speech: Danish Parliament Speech Corpus
May 25, 2020
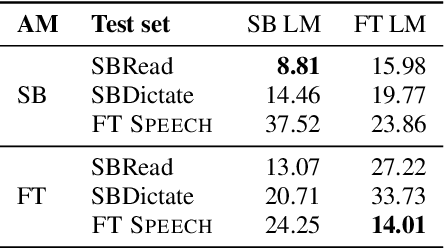
This paper introduces FT Speech, a new speech corpus created from the recorded meetings of the Danish Parliament, otherwise known as the Folketing (FT). The corpus contains over 1,800 hours of transcribed speech by a total of 434 speakers. It is significantly larger in duration, vocabulary, and amount of spontaneous speech than the existing public speech corpora for Danish, which are largely limited to read-aloud and dictation data. We outline design considerations, including the preprocessing methods and the alignment procedure. To evaluate the quality of the corpus, we train automatic speech recognition systems on the new resource and compare them to the systems trained on the Danish part of Spr\r{a}kbanken, the largest public ASR corpus for Danish to date. Our baseline results show that we achieve a 14.01 WER on the new corpus. A combination of FT Speech with in-domain language data provides comparable results to models trained specifically on Spr\r{a}kbanken, showing that FT Speech transfers well to this data set. Interestingly, our results demonstrate that the opposite is not the case. This shows that FT Speech provides a valuable resource for promoting research on Danish ASR with more spontaneous speech.
The Danish Gigaword Project
May 08, 2020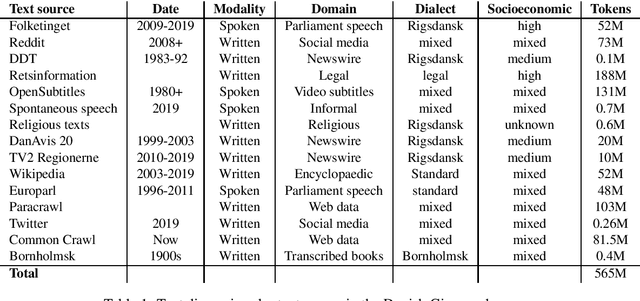
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.