 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs a prompt and a few samples all you need? Using GPT-4 for data augmentation in low-resource classification tasks
Apr 26, 2023
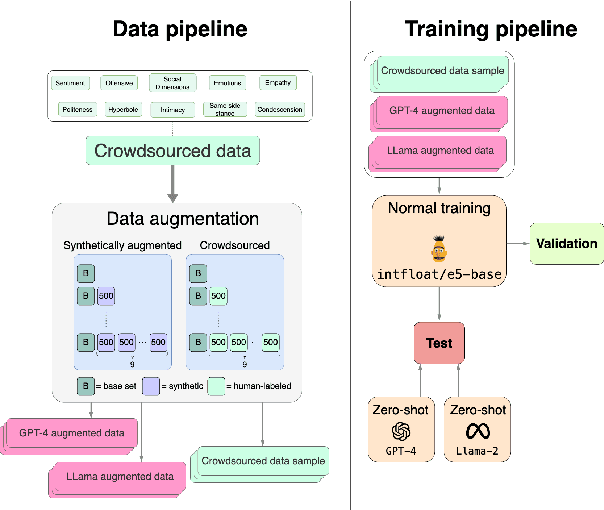


Obtaining and annotating data can be expensive and time-consuming, especially in complex, low-resource domains. We use GPT-4 and ChatGPT to augment small labeled datasets with synthetic data via simple prompts, in three different classification tasks with varying complexity. For each task, we randomly select a base sample of 500 texts to generate 5,000 new synthetic samples. We explore two augmentation strategies: one that preserves original label distribution and another that balances the distribution. Using a progressively larger training sample size, we train and evaluate a 110M parameter multilingual language model on the real and synthetic data separately. We also test GPT-4 and ChatGPT in a zero-shot setting on the test sets. We observe that GPT-4 and ChatGPT have strong zero-shot performance across all tasks. We find that data augmented with synthetic samples yields a good downstream performance, and particularly aids in low-resource settings, such as in identifying rare classes. Human-annotated data exhibits a strong predictive power, overtaking synthetic data in two out of the three tasks. This finding highlights the need for more complex prompts for synthetic datasets to consistently surpass human-generated ones.
The Danish Gigaword Project
May 08, 2020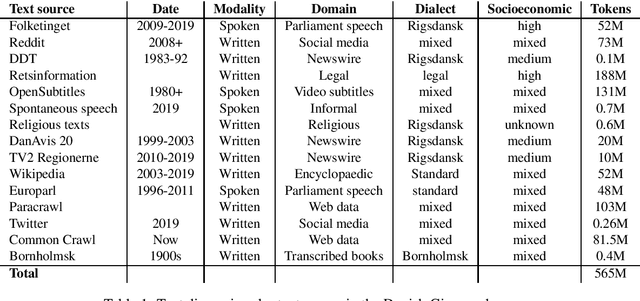
Danish is a North Germanic/Scandinavian language spoken primarily in Denmark, a country with a tradition of technological and scientific innovation. However, from a technological perspective, the Danish language has received relatively little attention and, as a result, Danish language technology is hard to develop, in part due to a lack of large or broad-coverage Danish corpora. This paper describes the Danish Gigaword project, which aims to construct a freely-available one billion word corpus of Danish text that represents the breadth of the written language.