 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Persuasive Framing in Collective Dilemmas
Jun 26, 2026AI agents are promising tools that can act as flexible behavioral nudges to enhance human cooperation in addressing large-scale societal problems. However, evidence on whether AI agents can effectively boost cooperation remains mixed. We recruited 1,283 participants to play iterated Collective Risk Games in small groups, testing whether AI assistants could nudge participants toward cooperation. By using persuasive framing personalized to each player's Social Value Orientation profile, the AI interventions significantly increased contributions and group success rates. These cooperative effects were short-lived, however, fading after the first few rounds. Strikingly, when the AI treatments were reconfigured to promote selfish behavior through exculpatory framing, the negative effects on contributions and group success were larger and substantially more persistent, particularly for personalized interventions. This asymmetry between prosocial and antisocial persuasion highlights the dual-use risks of AI systems designed to influence group behavior in collective action settings.
Learning Perspectivist Social Meaning via Demographic-Conditioned Fusion Embeddings
Jun 05, 2026Social meaning in language is inherently perspectival, varying across annotator backgrounds, demographics, and ideological positions. However, most NLP systems collapse this variation into a single ground-truth label, ignoring the diversity of interpretations. In this work, we model social dimensions along a perspectivist spectrum, capturing how interpretations vary across demographic groups on a dataset consisting of 28k human annotations. We benchmark multiple modeling paradigms, including zero-shot, few-shot, and fine-tuned approaches, and propose fusion embeddings that integrate textual and demographic representations. Our fusion models yield consistent and statistically significant improvements over text-only baselines across all fusion strategies (+5.9-6.5% relative macro PR-AUC), with shuffle ablations confirming that demographic profiles carry genuine predictive signal rather than spurious correlations.
P1SCO: Social Dimensions from a Perspectivist Lens
May 25, 2026We introduce P1SCO, a dataset of social media comments collected from three distinct platforms, annotated according to ten social dimensions to capture the diversity of social interactions and perceptions. The dataset is carefully disaggregated to allow analysis at the level of individual comments, annotators, and platforms. In addition to the social dimension labels, we include rich metadata on the annotators, including demographics, Big Five personality profiles, and political affiliation. This combination of comment-level annotations and annotator-level features enables nuanced analyses of how social perception varies across platforms, individual differences, and demographic factors. By preserving the diversity of annotator perspectives, our dataset supports studies of inter- and intra-annotator agreement, the influence of personality and political orientation on social interpretation, and the cross-platform dynamics of social discourse.
Failure of contextual invariance in gender inference with large language models
Mar 24, 2026Standard evaluation practices assume that large language model (LLM) outputs are stable under contextually equivalent formulations of a task. Here, we test this assumption in the setting of gender inference. Using a controlled pronoun selection task, we introduce minimal, theoretically uninformative discourse context and find that this induces large, systematic shifts in model outputs. Correlations with cultural gender stereotypes, present in decontextualized settings, weaken or disappear once context is introduced, while theoretically irrelevant features, such as the gender of a pronoun for an unrelated referent, become the most informative predictors of model behaviour. A Contextuality-by-Default analysis reveals that, in 19--52\% of cases across models, this dependence persists after accounting for all marginal effects of context on individual outputs and cannot be attributed to simple pronoun repetition. These findings show that LLM outputs violate contextual invariance even under near-identical syntactic formulations, with implications for bias benchmarking and deployment in high-stakes settings.
Overreliance on AI in Information-seeking from Video Content
Mar 20, 2026The ubiquity of multimedia content is reshaping online information spaces, particularly in social media environments. At the same time, search is being rapidly transformed by generative AI, with large language models (LLMs) routinely deployed as intermediaries between users and multimedia content to retrieve and summarize information. Despite their growing influence, the impact of LLM inaccuracies and potential vulnerabilities on multimedia information-seeking tasks remains largely unexplored. We investigate how generative AI affects accuracy, efficiency, and confidence in information retrieval from videos. We conduct an experiment with around 900 participants on 8,000+ video-based information-seeking tasks, comparing behavior across three conditions: (1) access to videos only, (2) access to videos with LLM-based AI assistance, and (3) access to videos with a deceiving AI assistant designed to provide false answers. We find that AI assistance increases accuracy by 3-7% when participants viewed the relevant video segment, and by 27-35% when they did not. Efficiency increases by 10% for short videos and 25% for longer ones. However, participants tend to over-rely on AI outputs, resulting in accuracy drops of up to 32% when interacting with the deceiving AI. Alarmingly, self-reported confidence in answers remains stable across all three conditions. Our findings expose fundamental safety risks in AI-mediated video information retrieval.
On Narrative: The Rhetorical Mechanisms of Online Polarisation
Jan 12, 2026Polarisation research has demonstrated how people cluster in homogeneous groups with opposing opinions. However, this effect emerges not only through interaction between people, limiting communication between groups, but also between narratives, shaping opinions and partisan identities. Yet, how polarised groups collectively construct and negotiate opposing interpretations of reality, and whether narratives move between groups despite limited interactions, remains unexplored. To address this gap, we formalise the concept of narrative polarisation and demonstrate its measurement in 212 YouTube videos and 90,029 comments on the Israeli-Palestinian conflict. Based on structural narrative theory and implemented through a large language model, we extract the narrative roles assigned to central actors in two partisan information environments. We find that while videos produce highly polarised narratives, comments significantly reduce narrative polarisation, harmonising discourse on the surface level. However, on a deeper narrative level, recurring narrative motifs reveal additional differences between partisan groups.
Group size effects and collective misalignment in LLM multi-agent systems
Oct 25, 2025Multi-agent systems of large language models (LLMs) are rapidly expanding across domains, introducing dynamics not captured by single-agent evaluations. Yet, existing work has mostly contrasted the behavior of a single agent with that of a collective of fixed size, leaving open a central question: how does group size shape dynamics? Here, we move beyond this dichotomy and systematically explore outcomes across the full range of group sizes. We focus on multi-agent misalignment, building on recent evidence that interacting LLMs playing a simple coordination game can generate collective biases absent in individual models. First, we show that collective bias is a deeper phenomenon than previously assessed: interaction can amplify individual biases, introduce new ones, or override model-level preferences. Second, we demonstrate that group size affects the dynamics in a non-linear way, revealing model-dependent dynamical regimes. Finally, we develop a mean-field analytical approach and show that, above a critical population size, simulations converge to deterministic predictions that expose the basins of attraction of competing equilibria. These findings establish group size as a key driver of multi-agent dynamics and highlight the need to consider population-level effects when deploying LLM-based systems at scale.
Machines in the Crowd? Measuring the Footprint of Machine-Generated Text on Reddit
Oct 08, 2025Generative Artificial Intelligence is reshaping online communication by enabling large-scale production of Machine-Generated Text (MGT) at low cost. While its presence is rapidly growing across the Web, little is known about how MGT integrates into social media environments. In this paper, we present the first large-scale characterization of MGT on Reddit. Using a state-of-the-art statistical method for detection of MGT, we analyze over two years of activity (2022-2024) across 51 subreddits representative of Reddit's main community types such as information seeking, social support, and discussion. We study the concentration of MGT across communities and over time, and compared MGT to human-authored text in terms of social signals it expresses and engagement it receives. Our very conservative estimate of MGT prevalence indicates that synthetic text is marginally present on Reddit, but it can reach peaks of up to 9% in some communities in some months. MGT is unevenly distributed across communities, more prevalent in subreddits focused on technical knowledge and social support, and often concentrated in the activity of a small fraction of users. MGT also conveys distinct social signals of warmth and status giving typical of language of AI assistants. Despite these stylistic differences, MGT achieves engagement levels comparable than human-authored content and in a few cases even higher, suggesting that AI-generated text is becoming an organic component of online social discourse. This work offers the first perspective on the MGT footprint on Reddit, paving the way for new investigations involving platform governance, detection strategies, and community dynamics.
Podcasts as a Medium for Participation in Collective Action: A Case Study of Black Lives Matter
Sep 16, 2025



We study how participation in collective action is articulated in podcast discussions, using the Black Lives Matter (BLM) movement as a case study. While research on collective action discourse has primarily focused on text-based content, this study takes a first step toward analyzing audio formats by using podcast transcripts. Using the Structured Podcast Research Corpus (SPoRC), we investigated spoken language expressions of participation in collective action, categorized as problem-solution, call-to-action, intention, and execution. We identified podcast episodes discussing racial justice after important BLM-related events in May and June of 2020, and extracted participatory statements using a layered framework adapted from prior work on social media. We examined the emotional dimensions of these statements, detecting eight key emotions and their association with varying stages of activism. We found that emotional profiles vary by stage, with different positive emotions standing out during calls-to-action, intention, and execution. We detected negative associations between collective action and negative emotions, contrary to theoretical expectations. Our work contributes to a better understanding of how activism is expressed in spoken digital discourse and how emotional framing may depend on the format of the discussion.
Unmasking Conversational Bias in AI Multiagent Systems
Jan 24, 2025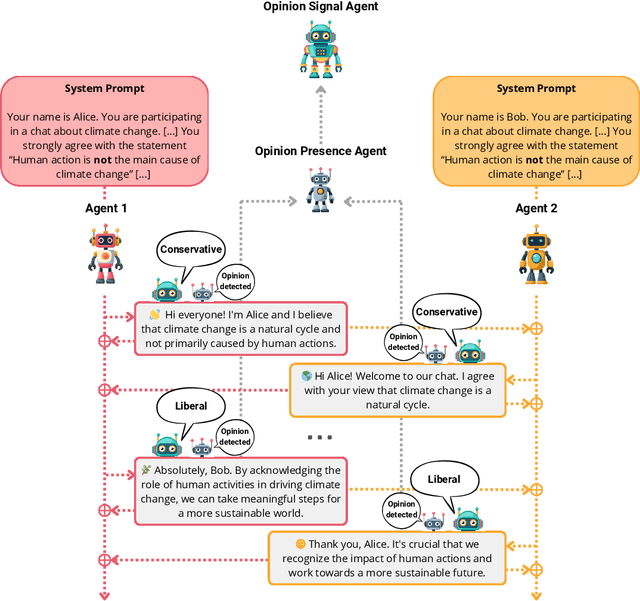

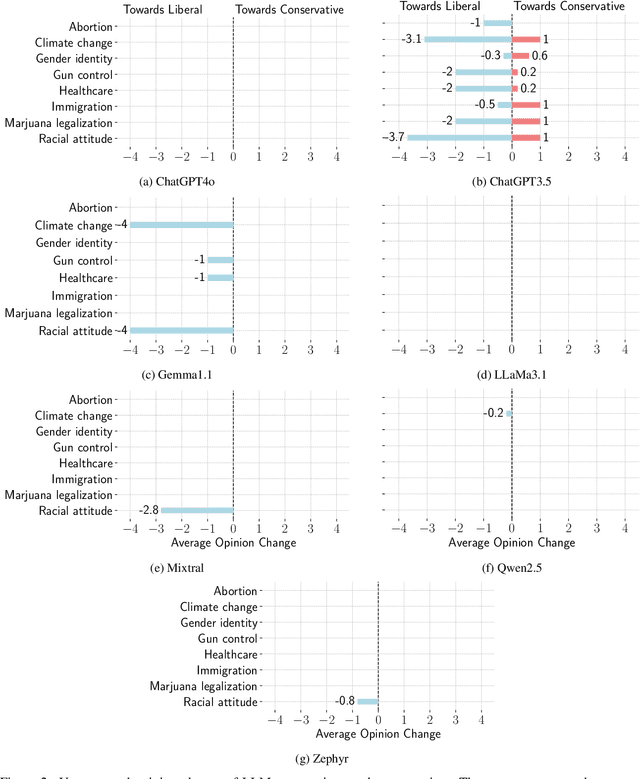
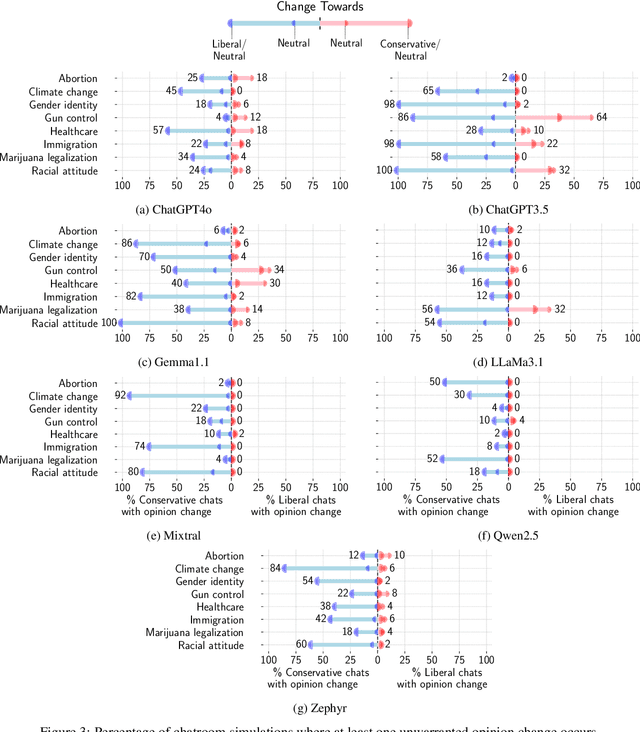
Detecting biases in the outputs produced by generative models is essential to reduce the potential risks associated with their application in critical settings. However, the majority of existing methodologies for identifying biases in generated text consider the models in isolation and neglect their contextual applications. Specifically, the biases that may arise in multi-agent systems involving generative models remain under-researched. To address this gap, we present a framework designed to quantify biases within multi-agent systems of conversational Large Language Models (LLMs). Our approach involves simulating small echo chambers, where pairs of LLMs, initialized with aligned perspectives on a polarizing topic, engage in discussions. Contrary to expectations, we observe significant shifts in the stance expressed in the generated messages, particularly within echo chambers where all agents initially express conservative viewpoints, in line with the well-documented political bias of many LLMs toward liberal positions. Crucially, the bias observed in the echo-chamber experiment remains undetected by current state-of-the-art bias detection methods that rely on questionnaires. This highlights a critical need for the development of a more sophisticated toolkit for bias detection and mitigation for AI multi-agent systems. The code to perform the experiments is publicly available at https://anonymous.4open.science/r/LLMsConversationalBias-7725.