 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverreliance on AI in Information-seeking from Video Content
Mar 20, 2026The ubiquity of multimedia content is reshaping online information spaces, particularly in social media environments. At the same time, search is being rapidly transformed by generative AI, with large language models (LLMs) routinely deployed as intermediaries between users and multimedia content to retrieve and summarize information. Despite their growing influence, the impact of LLM inaccuracies and potential vulnerabilities on multimedia information-seeking tasks remains largely unexplored. We investigate how generative AI affects accuracy, efficiency, and confidence in information retrieval from videos. We conduct an experiment with around 900 participants on 8,000+ video-based information-seeking tasks, comparing behavior across three conditions: (1) access to videos only, (2) access to videos with LLM-based AI assistance, and (3) access to videos with a deceiving AI assistant designed to provide false answers. We find that AI assistance increases accuracy by 3-7% when participants viewed the relevant video segment, and by 27-35% when they did not. Efficiency increases by 10% for short videos and 25% for longer ones. However, participants tend to over-rely on AI outputs, resulting in accuracy drops of up to 32% when interacting with the deceiving AI. Alarmingly, self-reported confidence in answers remains stable across all three conditions. Our findings expose fundamental safety risks in AI-mediated video information retrieval.
Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
Sep 16, 2024Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.
Prompt Refinement or Fine-tuning? Best Practices for using LLMs in Computational Social Science Tasks
Aug 02, 2024
Large Language Models are expressive tools that enable complex tasks of text understanding within Computational Social Science. Their versatility, while beneficial, poses a barrier for establishing standardized best practices within the field. To bring clarity on the values of different strategies, we present an overview of the performance of modern LLM-based classification methods on a benchmark of 23 social knowledge tasks. Our results point to three best practices: select models with larger vocabulary and pre-training corpora; avoid simple zero-shot in favor of AI-enhanced prompting; fine-tune on task-specific data, and consider more complex forms instruction-tuning on multiple datasets only when only training data is more abundant.
The Persuasive Power of Large Language Models
Dec 24, 2023



The increasing capability of Large Language Models to act as human-like social agents raises two important questions in the area of opinion dynamics. First, whether these agents can generate effective arguments that could be injected into the online discourse to steer the public opinion. Second, whether artificial agents can interact with each other to reproduce dynamics of persuasion typical of human social systems, opening up opportunities for studying synthetic social systems as faithful proxies for opinion dynamics in human populations. To address these questions, we designed a synthetic persuasion dialogue scenario on the topic of climate change, where a 'convincer' agent generates a persuasive argument for a 'skeptic' agent, who subsequently assesses whether the argument changed its internal opinion state. Different types of arguments were generated to incorporate different linguistic dimensions underpinning psycho-linguistic theories of opinion change. We then asked human judges to evaluate the persuasiveness of machine-generated arguments. Arguments that included factual knowledge, markers of trust, expressions of support, and conveyed status were deemed most effective according to both humans and agents, with humans reporting a marked preference for knowledge-based arguments. Our experimental framework lays the groundwork for future in-silico studies of opinion dynamics, and our findings suggest that artificial agents have the potential of playing an important role in collective processes of opinion formation in online social media.
Is a prompt and a few samples all you need? Using GPT-4 for data augmentation in low-resource classification tasks
Apr 26, 2023
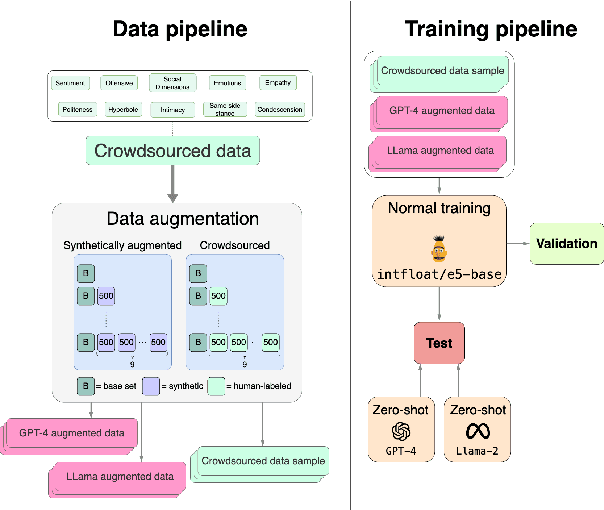


Obtaining and annotating data can be expensive and time-consuming, especially in complex, low-resource domains. We use GPT-4 and ChatGPT to augment small labeled datasets with synthetic data via simple prompts, in three different classification tasks with varying complexity. For each task, we randomly select a base sample of 500 texts to generate 5,000 new synthetic samples. We explore two augmentation strategies: one that preserves original label distribution and another that balances the distribution. Using a progressively larger training sample size, we train and evaluate a 110M parameter multilingual language model on the real and synthetic data separately. We also test GPT-4 and ChatGPT in a zero-shot setting on the test sets. We observe that GPT-4 and ChatGPT have strong zero-shot performance across all tasks. We find that data augmented with synthetic samples yields a good downstream performance, and particularly aids in low-resource settings, such as in identifying rare classes. Human-annotated data exhibits a strong predictive power, overtaking synthetic data in two out of the three tasks. This finding highlights the need for more complex prompts for synthetic datasets to consistently surpass human-generated ones.