 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKODIS: A Multicultural Dispute Resolution Dialogue Corpus
Apr 17, 2025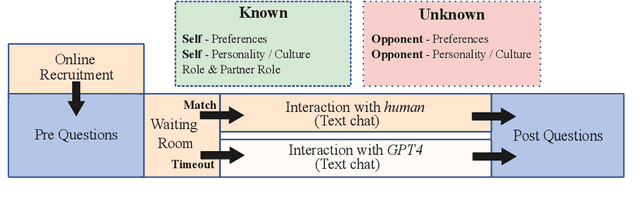
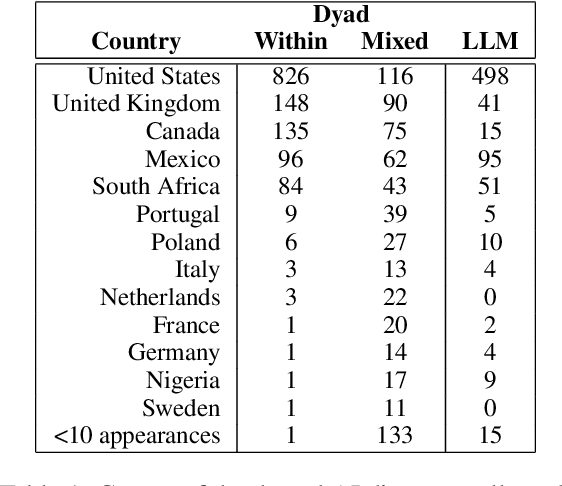

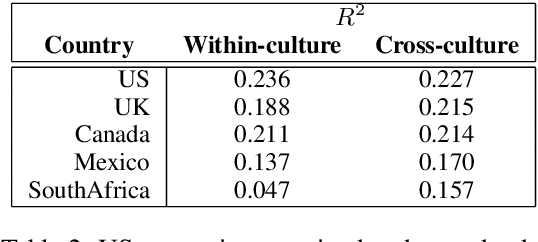
We present KODIS, a dyadic dispute resolution corpus containing thousands of dialogues from over 75 countries. Motivated by a theoretical model of culture and conflict, participants engage in a typical customer service dispute designed by experts to evoke strong emotions and conflict. The corpus contains a rich set of dispositional, process, and outcome measures. The initial analysis supports theories of how anger expressions lead to escalatory spirals and highlights cultural differences in emotional expression. We make this corpus and data collection framework available to the community.
Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
Sep 16, 2024Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.