 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
Sep 16, 2024Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.
The Role of Network and Identity in the Diffusion of Hashtags
Jul 17, 2024


Although the spread of behaviors is influenced by many social factors, existing literature tends to study the effects of single factors -- most often, properties of the social network -- on the final cascade. In order to move towards a more integrated view of cascades, this paper offers the first comprehensive investigation into the role of two social factors in the diffusion of 1,337 popular hashtags representing the production of novel culture on Twitter: 1) the topology of the Twitter social network and 2) performance of each user's probable demographic identity. Here, we show that cascades are best modeled using a combination of network and identity, rather than either factor alone. This combined model best reproduces a composite index of ten cascade properties across all 1,337 hashtags. However, there is important heterogeneity in what social factors are required to reproduce different properties of hashtag cascades. For instance, while a combined network+identity model best predicts the popularity of cascades, a network-only model has better performance in predicting cascade growth and an identity-only model in adopter composition. We are able to predict what type of hashtag is best modeled by each combination of features and use this to further improve performance. Additionally, consistent with prior literature on the combined network+identity model most outperforms the single-factor counterfactuals among hashtags used for expressing racial or regional identity, stance-taking, talking about sports, or variants of existing cultural trends with very slow- or fast-growing communicative need. In sum, our results imply the utility of multi-factor models in predicting cascades, in order to account for the varied ways in which network, identity, and other social factors play a role in the diffusion of hashtags on Twitter.
Exploring Linguistic Style Matching in Online Communities: The Role of Social Context and Conversation Dynamics
Jul 06, 2023



Linguistic style matching (LSM) in conversations can be reflective of several aspects of social influence such as power or persuasion. However, how LSM relates to the outcomes of online communication on platforms such as Reddit is an unknown question. In this study, we analyze a large corpus of two-party conversation threads in Reddit where we identify all occurrences of LSM using two types of style: the use of function words and formality. Using this framework, we examine how levels of LSM differ in conversations depending on several social factors within Reddit: post and subreddit features, conversation depth, user tenure, and the controversiality of a comment. Finally, we measure the change of LSM following loss of status after community banning. Our findings reveal the interplay of LSM in Reddit conversations with several community metrics, suggesting the importance of understanding conversation engagement when understanding community dynamics.
POTATO: The Portable Text Annotation Tool
Dec 16, 2022We present POTATO, the Portable text annotation tool, a free, fully open-sourced annotation system that 1) supports labeling many types of text and multimodal data; 2) offers easy-to-configure features to maximize the productivity of both deployers and annotators (convenient templates for common ML/NLP tasks, active learning, keypress shortcuts, keyword highlights, tooltips); and 3) supports a high degree of customization (editable UI, inserting pre-screening questions, attention and qualification tests). Experiments over two annotation tasks suggest that POTATO improves labeling speed through its specially-designed productivity features, especially for long documents and complex tasks. POTATO is available at https://github.com/davidjurgens/potato and will continue to be updated.
Networks and Identity Drive Geographic Properties of the Diffusion of Linguistic Innovation
Feb 10, 2022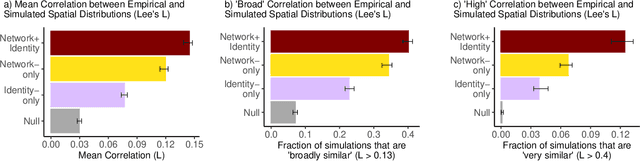
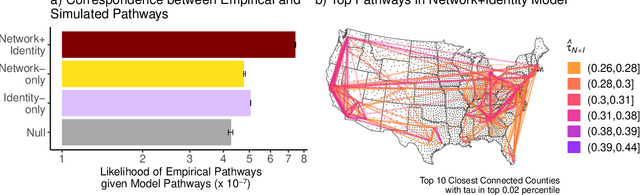
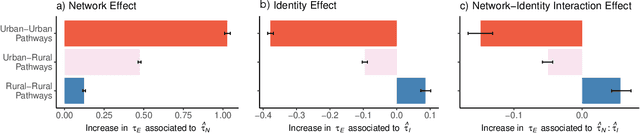
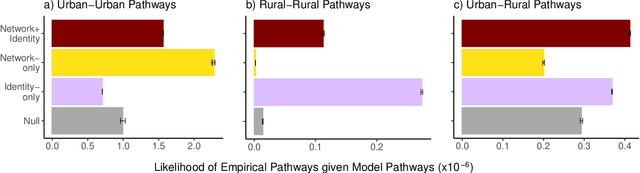
Adoption of cultural innovation (e.g., music, beliefs, language) is often geographically correlated, with adopters largely residing within the boundaries of relatively few well-studied, socially significant areas. These cultural regions are often hypothesized to be the result of either (i) identity performance driving the adoption of cultural innovation, or (ii) homophily in the networks underlying diffusion. In this study, we show that demographic identity and network topology are both required to model the diffusion of innovation, as they play complementary roles in producing its spatial properties. We develop an agent-based model of cultural adoption, and validate geographic patterns of transmission in our model against a novel dataset of innovative words that we identify from a 10% sample of Twitter. Using our model, we are able to directly compare a combined network + identity model of diffusion to simulated network-only and identity-only counterfactuals -- allowing us to test the separate and combined roles of network and identity. While social scientists often treat either network or identity as the core social structure in modeling culture change, we show that key geographic properties of diffusion actually depend on both factors as each one influences different mechanisms of diffusion. Specifically, the network principally drives spread among urban counties via weak-tie diffusion, while identity plays a disproportionate role in transmission among rural counties via strong-tie diffusion. Diffusion between urban and rural areas, a key component in innovation diffusing nationally, requires both network and identity. Our work suggests that models must integrate both factors in order to understand and reproduce the adoption of innovation.