 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Exploring Linguistic Style Matching in Online Communities: The Role of Social Context and Conversation Dynamics
Jul 06, 2023



Linguistic style matching (LSM) in conversations can be reflective of several aspects of social influence such as power or persuasion. However, how LSM relates to the outcomes of online communication on platforms such as Reddit is an unknown question. In this study, we analyze a large corpus of two-party conversation threads in Reddit where we identify all occurrences of LSM using two types of style: the use of function words and formality. Using this framework, we examine how levels of LSM differ in conversations depending on several social factors within Reddit: post and subreddit features, conversation depth, user tenure, and the controversiality of a comment. Finally, we measure the change of LSM following loss of status after community banning. Our findings reveal the interplay of LSM in Reddit conversations with several community metrics, suggesting the importance of understanding conversation engagement when understanding community dynamics.
TOM: Learning Policy-Aware Models for Model-Based Reinforcement Learning via Transition Occupancy Matching
May 22, 2023Standard model-based reinforcement learning (MBRL) approaches fit a transition model of the environment to all past experience, but this wastes model capacity on data that is irrelevant for policy improvement. We instead propose a new "transition occupancy matching" (TOM) objective for MBRL model learning: a model is good to the extent that the current policy experiences the same distribution of transitions inside the model as in the real environment. We derive TOM directly from a novel lower bound on the standard reinforcement learning objective. To optimize TOM, we show how to reduce it to a form of importance weighted maximum-likelihood estimation, where the automatically computed importance weights identify policy-relevant past experiences from a replay buffer, enabling stable optimization. TOM thus offers a plug-and-play model learning sub-routine that is compatible with any backbone MBRL algorithm. On various Mujoco continuous robotic control tasks, we show that TOM successfully focuses model learning on policy-relevant experience and drives policies faster to higher task rewards than alternative model learning approaches.
How Far I'll Go: Offline Goal-Conditioned Reinforcement Learning via $f$-Advantage Regression
Jun 07, 2022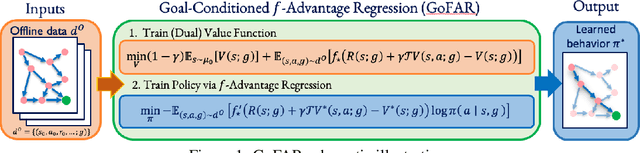
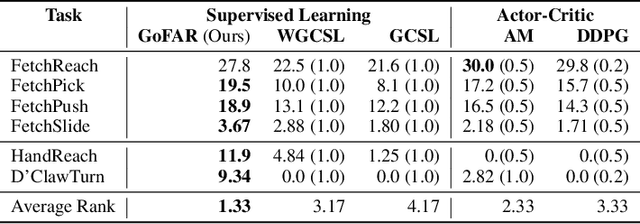

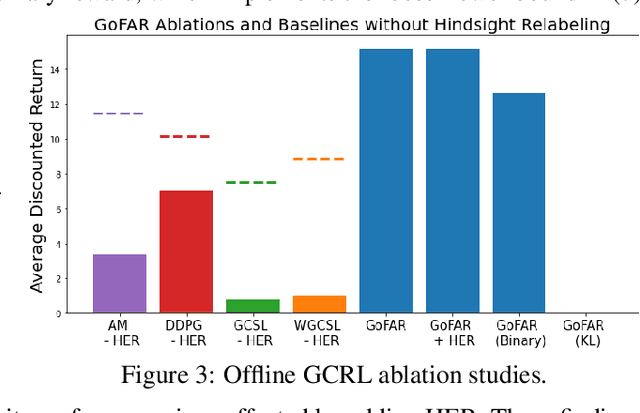
Offline goal-conditioned reinforcement learning (GCRL) promises general-purpose skill learning in the form of reaching diverse goals from purely offline datasets. We propose $\textbf{Go}$al-conditioned $f$-$\textbf{A}$dvantage $\textbf{R}$egression (GoFAR), a novel regression-based offline GCRL algorithm derived from a state-occupancy matching perspective; the key intuition is that the goal-reaching task can be formulated as a state-occupancy matching problem between a dynamics-abiding imitator agent and an expert agent that directly teleports to the goal. In contrast to prior approaches, GoFAR does not require any hindsight relabeling and enjoys uninterleaved optimization for its value and policy networks. These distinct features confer GoFAR with much better offline performance and stability as well as statistical performance guarantee that is unattainable for prior methods. Furthermore, we demonstrate that GoFAR's training objectives can be re-purposed to learn an agent-independent goal-conditioned planner from purely offline source-domain data, which enables zero-shot transfer to new target domains. Through extensive experiments, we validate GoFAR's effectiveness in various problem settings and tasks, significantly outperforming prior state-of-art. Notably, on a real robotic dexterous manipulation task, while no other method makes meaningful progress, GoFAR acquires complex manipulation behavior that successfully accomplishes diverse goals.