 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Styles and Reader Preferences of LLM and Human Experts in Explaining Health Information
May 13, 2025
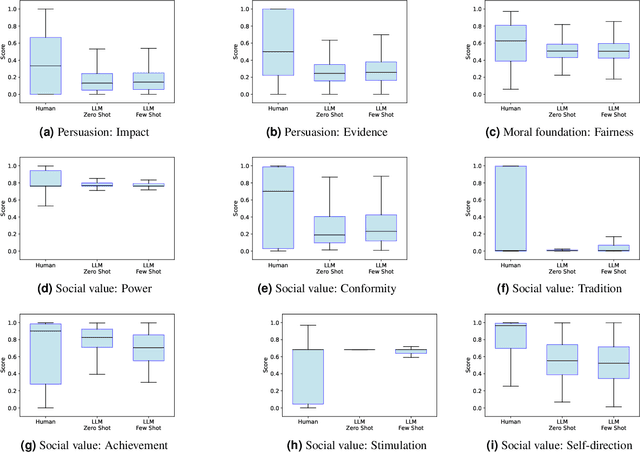
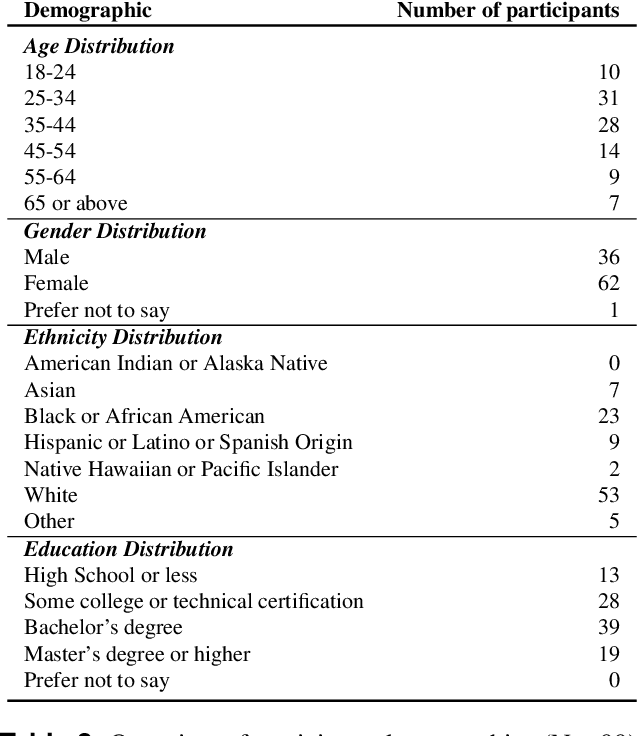
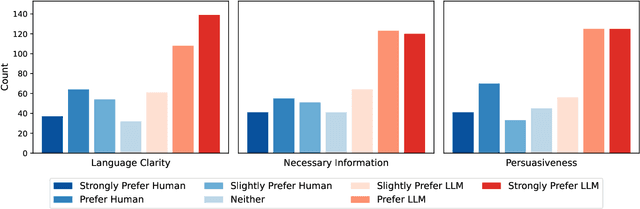
With the wide adoption of large language models (LLMs) in information assistance, it is essential to examine their alignment with human communication styles and values. We situate this study within the context of fact-checking health information, given the critical challenge of rectifying conceptions and building trust. Recent studies have explored the potential of LLM for health communication, but style differences between LLMs and human experts and associated reader perceptions remain under-explored. In this light, our study evaluates the communication styles of LLMs, focusing on how their explanations differ from those of humans in three core components of health communication: information, sender, and receiver. We compiled a dataset of 1498 health misinformation explanations from authoritative fact-checking organizations and generated LLM responses to inaccurate health information. Drawing from health communication theory, we evaluate communication styles across three key dimensions of information linguistic features, sender persuasive strategies, and receiver value alignments. We further assessed human perceptions through a blinded evaluation with 99 participants. Our findings reveal that LLM-generated articles showed significantly lower scores in persuasive strategies, certainty expressions, and alignment with social values and moral foundations. However, human evaluation demonstrated a strong preference for LLM content, with over 60% responses favoring LLM articles for clarity, completeness, and persuasiveness. Our results suggest that LLMs' structured approach to presenting information may be more effective at engaging readers despite scoring lower on traditional measures of quality in fact-checking and health communication.
Mysterious Projections: Multimodal LLMs Gain Domain-Specific Visual Capabilities Without Richer Cross-Modal Projections
Feb 26, 2024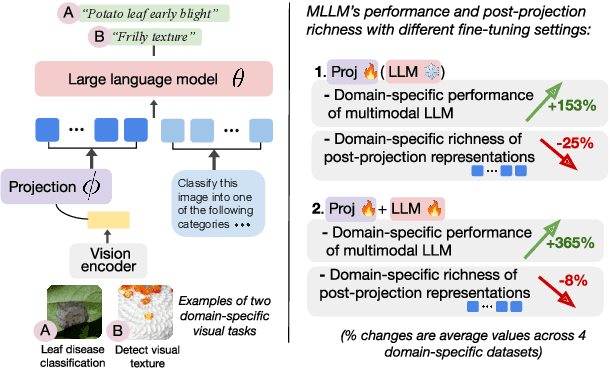
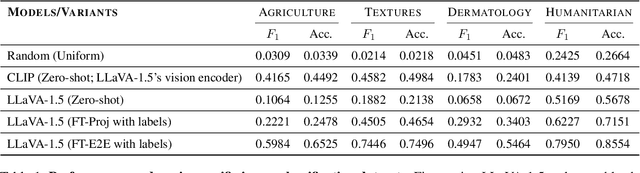
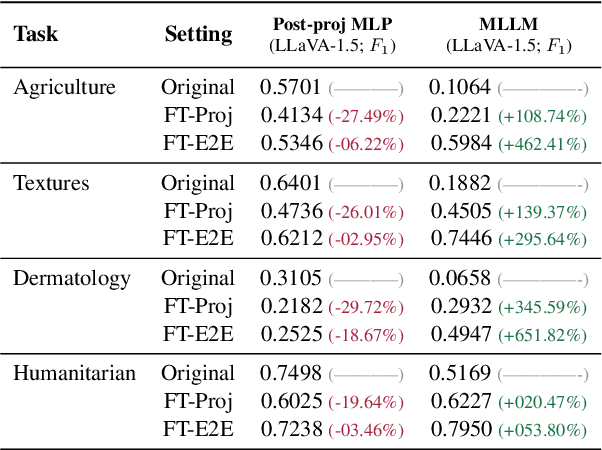
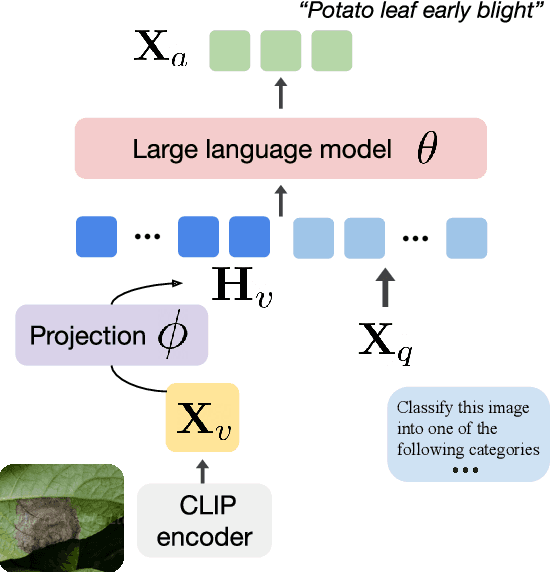
Multimodal large language models (MLLMs) like LLaVA and GPT-4(V) enable general-purpose conversations about images with the language modality. As off-the-shelf MLLMs may have limited capabilities on images from domains like dermatology and agriculture, they must be fine-tuned to unlock domain-specific applications. The prevalent architecture of current open-source MLLMs comprises two major modules: an image-language (cross-modal) projection network and a large language model. It is desirable to understand the roles of these two modules in modeling domain-specific visual attributes to inform the design of future models and streamline the interpretability efforts on the current models. To this end, via experiments on 4 datasets and under 2 fine-tuning settings, we find that as the MLLM is fine-tuned, it indeed gains domain-specific visual capabilities, but the updates do not lead to the projection extracting relevant domain-specific visual attributes. Our results indicate that the domain-specific visual attributes are modeled by the LLM, even when only the projection is fine-tuned. Through this study, we offer a potential reinterpretation of the role of cross-modal projections in MLLM architectures. Projection webpage: https://claws-lab.github.io/projection-in-MLLMs/
MM-Soc: Benchmarking Multimodal Large Language Models in Social Media Platforms
Feb 21, 2024



Social media platforms are hubs for multimodal information exchange, encompassing text, images, and videos, making it challenging for machines to comprehend the information or emotions associated with interactions in online spaces. Multimodal Large Language Models (MLLMs) have emerged as a promising solution to address these challenges, yet struggle with accurately interpreting human emotions and complex contents like misinformation. This paper introduces MM-Soc, a comprehensive benchmark designed to evaluate MLLMs' understanding of multimodal social media content. MM-Soc compiles prominent multimodal datasets and incorporates a novel large-scale YouTube tagging dataset, targeting a range of tasks from misinformation detection, hate speech detection, and social context generation. Through our exhaustive evaluation on ten size-variants of four open-source MLLMs, we have identified significant performance disparities, highlighting the need for advancements in models' social understanding capabilities. Our analysis reveals that, in a zero-shot setting, various types of MLLMs generally exhibit difficulties in handling social media tasks. However, MLLMs demonstrate performance improvements post fine-tuning, suggesting potential pathways for improvement.
Aligning with Whom? Large Language Models Have Gender and Racial Biases in Subjective NLP Tasks
Nov 16, 2023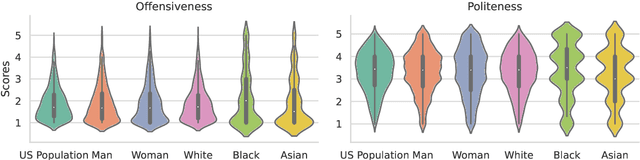

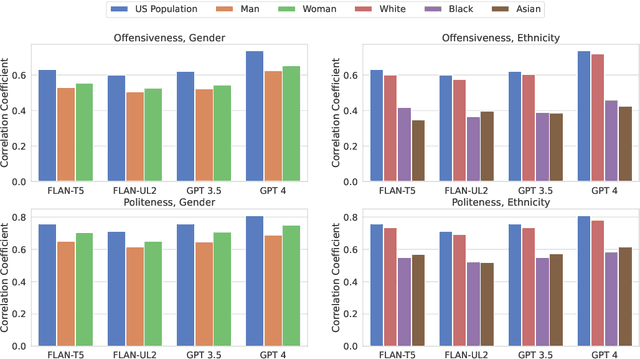

Human perception of language depends on personal backgrounds like gender and ethnicity. While existing studies have shown that large language models (LLMs) hold values that are closer to certain societal groups, it is unclear whether their prediction behaviors on subjective NLP tasks also exhibit a similar bias. In this study, leveraging the POPQUORN dataset which contains annotations of diverse demographic backgrounds, we conduct a series of experiments on four popular LLMs to investigate their capability to understand group differences and potential biases in their predictions for politeness and offensiveness. We find that for both tasks, model predictions are closer to the labels from White and female participants. We further explore prompting with the target demographic labels and show that including the target demographic in the prompt actually worsens the model's performance. More specifically, when being prompted to respond from the perspective of "Black" and "Asian" individuals, models show lower performance in predicting both overall scores as well as the scores from corresponding groups. Our results suggest that LLMs hold gender and racial biases for subjective NLP tasks and that demographic-infused prompts alone may be insufficient to mitigate such effects. Code and data are available at https://github.com/Jiaxin-Pei/LLM-Group-Bias.
You don't need a personality test to know these models are unreliable: Assessing the Reliability of Large Language Models on Psychometric Instruments
Nov 16, 2023The versatility of Large Language Models (LLMs) on natural language understanding tasks has made them popular for research in social sciences. In particular, to properly understand the properties and innate personas of LLMs, researchers have performed studies that involve using prompts in the form of questions that ask LLMs of particular opinions. In this study, we take a cautionary step back and examine whether the current format of prompting enables LLMs to provide responses in a consistent and robust manner. We first construct a dataset that contains 693 questions encompassing 39 different instruments of persona measurement on 115 persona axes. Additionally, we design a set of prompts containing minor variations and examine LLM's capabilities to generate accurate answers, as well as consistency variations to examine their consistency towards simple perturbations such as switching the option order. Our experiments on 15 different open-source LLMs reveal that even simple perturbations are sufficient to significantly downgrade a model's question-answering ability, and that most LLMs have low negation consistency. Our results suggest that the currently widespread practice of prompting is insufficient to accurately capture model perceptions, and we discuss potential alternatives to improve such issues.
Exploring Linguistic Style Matching in Online Communities: The Role of Social Context and Conversation Dynamics
Jul 06, 2023



Linguistic style matching (LSM) in conversations can be reflective of several aspects of social influence such as power or persuasion. However, how LSM relates to the outcomes of online communication on platforms such as Reddit is an unknown question. In this study, we analyze a large corpus of two-party conversation threads in Reddit where we identify all occurrences of LSM using two types of style: the use of function words and formality. Using this framework, we examine how levels of LSM differ in conversations depending on several social factors within Reddit: post and subreddit features, conversation depth, user tenure, and the controversiality of a comment. Finally, we measure the change of LSM following loss of status after community banning. Our findings reveal the interplay of LSM in Reddit conversations with several community metrics, suggesting the importance of understanding conversation engagement when understanding community dynamics.
Do LLMs Understand Social Knowledge? Evaluating the Sociability of Large Language Models with SocKET Benchmark
May 24, 2023



Large language models (LLMs) have been shown to perform well at a variety of syntactic, discourse, and reasoning tasks. While LLMs are increasingly deployed in many forms including conversational agents that interact with humans, we lack a grounded benchmark to measure how well LLMs understand \textit{social} language. Here, we introduce a new theory-driven benchmark, SocKET, that contains 58 NLP tasks testing social knowledge which we group into five categories: humor & sarcasm, offensiveness, sentiment & emotion, and trustworthiness. In tests on the benchmark, we demonstrate that current models attain only moderate performance but reveal significant potential for task transfer among different types and categories of tasks, which were predicted from theory. Through zero-shot evaluations, we show that pretrained models already possess some innate but limited capabilities of social language understanding and training on one category of tasks can improve zero-shot testing on others. Our benchmark provides a systematic way to analyze model performance on an important dimension of language and points to clear room for improvement to build more socially-aware LLMs. The associated resources are released at https://github.com/minjechoi/SOCKET.
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Sep 21, 2018

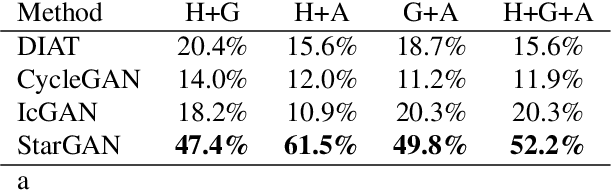
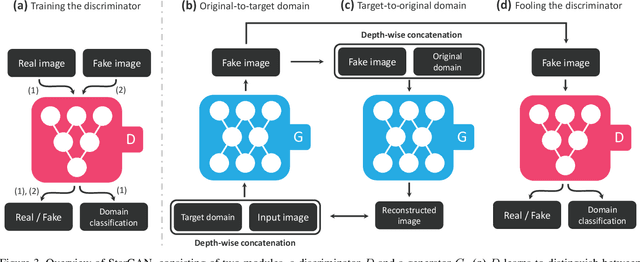
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN's superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
* Accepted to CVPR 2018 (Oral)