 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALM-IT: Generating Realistic Long-Form Motivational Interviewing Dialogues with Dual-Actor Conversational Dynamics Tracking
Jan 15, 2026Large Language Models (LLMs) are increasingly used in mental health-related settings, yet they struggle to sustain realistic, goal-directed dialogue over extended interactions. While LLMs generate fluent responses, they optimize locally for the next turn rather than maintaining a coherent model of therapeutic progress, leading to brittleness and long-horizon drift. We introduce CALM-IT, a framework for generating and evaluating long-form Motivational Interviewing (MI) dialogues that explicitly models dual-actor conversational dynamics. CALM-IT represents therapist-client interaction as a bidirectional state-space process, in which both agents continuously update inferred alignment, mental states, and short-term goals to guide strategy selection and utterance generation. Across large-scale evaluations, CALM-IT consistently outperforms strong baselines in Effectiveness and Goal Alignment and remains substantially more stable as conversation length increases. Although CALM-IT initiates fewer therapist redirections, it achieves the highest client acceptance rate (64.3%), indicating more precise and therapeutically aligned intervention timing. Overall, CALM-IT provides evidence for modeling evolving conversational state being essential for generating high-quality long-form synthetic conversations.
Echoes of Human Malice in Agents: Benchmarking LLMs for Multi-Turn Online Harassment Attacks
Oct 16, 2025Large Language Model (LLM) agents are powering a growing share of interactive web applications, yet remain vulnerable to misuse and harm. Prior jailbreak research has largely focused on single-turn prompts, whereas real harassment often unfolds over multi-turn interactions. In this work, we present the Online Harassment Agentic Benchmark consisting of: (i) a synthetic multi-turn harassment conversation dataset, (ii) a multi-agent (e.g., harasser, victim) simulation informed by repeated game theory, (iii) three jailbreak methods attacking agents across memory, planning, and fine-tuning, and (iv) a mixed-methods evaluation framework. We utilize two prominent LLMs, LLaMA-3.1-8B-Instruct (open-source) and Gemini-2.0-flash (closed-source). Our results show that jailbreak tuning makes harassment nearly guaranteed with an attack success rate of 95.78--96.89% vs. 57.25--64.19% without tuning in Llama, and 99.33% vs. 98.46% without tuning in Gemini, while sharply reducing refusal rate to 1-2% in both models. The most prevalent toxic behaviors are Insult with 84.9--87.8% vs. 44.2--50.8% without tuning, and Flaming with 81.2--85.1% vs. 31.5--38.8% without tuning, indicating weaker guardrails compared to sensitive categories such as sexual or racial harassment. Qualitative evaluation further reveals that attacked agents reproduce human-like aggression profiles, such as Machiavellian/psychopathic patterns under planning, and narcissistic tendencies with memory. Counterintuitively, closed-source and open-source models exhibit distinct escalation trajectories across turns, with closed-source models showing significant vulnerability. Overall, our findings show that multi-turn and theory-grounded attacks not only succeed at high rates but also mimic human-like harassment dynamics, motivating the development of robust safety guardrails to ultimately keep online platforms safe and responsible.
Towards Experience-Centered AI: A Framework for Integrating Lived Experience in Design and Development
Aug 09, 2025Lived experiences fundamentally shape how individuals interact with AI systems, influencing perceptions of safety, trust, and usability. While prior research has focused on developing techniques to emulate human preferences, and proposed taxonomies to categorize risks (such as psychological harms and algorithmic biases), these efforts have provided limited systematic understanding of lived human experiences or actionable strategies for embedding them meaningfully into the AI development lifecycle. This work proposes a framework for meaningfully integrating lived experience into the design and evaluation of AI systems. We synthesize interdisciplinary literature across lived experience philosophy, human-centered design, and human-AI interaction, arguing that centering lived experience can lead to models that more accurately reflect the retrospective, emotional, and contextual dimensions of human cognition. Drawing from a wide body of work across psychology, education, healthcare, and social policy, we present a targeted taxonomy of lived experiences with specific applicability to AI systems. To ground our framework, we examine three application domains (i) education, (ii) healthcare, and (iii) cultural alignment, illustrating how lived experience informs user goals, system expectations, and ethical considerations in each context. We further incorporate insights from AI system operators and human-AI partnerships to highlight challenges in responsibility allocation, mental model calibration, and long-term system adaptation. We conclude with actionable recommendations for developing experience-centered AI systems that are not only technically robust but also empathetic, context-aware, and aligned with human realities. This work offers a foundation for future research that bridges technical development with the lived experiences of those impacted by AI systems.
Reasoning Is Not All You Need: Examining LLMs for Multi-Turn Mental Health Conversations
May 28, 2025Limited access to mental healthcare, extended wait times, and increasing capabilities of Large Language Models (LLMs) has led individuals to turn to LLMs for fulfilling their mental health needs. However, examining the multi-turn mental health conversation capabilities of LLMs remains under-explored. Existing evaluation frameworks typically focus on diagnostic accuracy and win-rates and often overlook alignment with patient-specific goals, values, and personalities required for meaningful conversations. To address this, we introduce MedAgent, a novel framework for synthetically generating realistic, multi-turn mental health sensemaking conversations and use it to create the Mental Health Sensemaking Dialogue (MHSD) dataset, comprising over 2,200 patient-LLM conversations. Additionally, we present MultiSenseEval, a holistic framework to evaluate the multi-turn conversation abilities of LLMs in healthcare settings using human-centric criteria. Our findings reveal that frontier reasoning models yield below-par performance for patient-centric communication and struggle at advanced diagnostic capabilities with average score of 31%. Additionally, we observed variation in model performance based on patient's persona and performance drop with increasing turns in the conversation. Our work provides a comprehensive synthetic data generation framework, a dataset and evaluation framework for assessing LLMs in multi-turn mental health conversations.
Communication Styles and Reader Preferences of LLM and Human Experts in Explaining Health Information
May 13, 2025
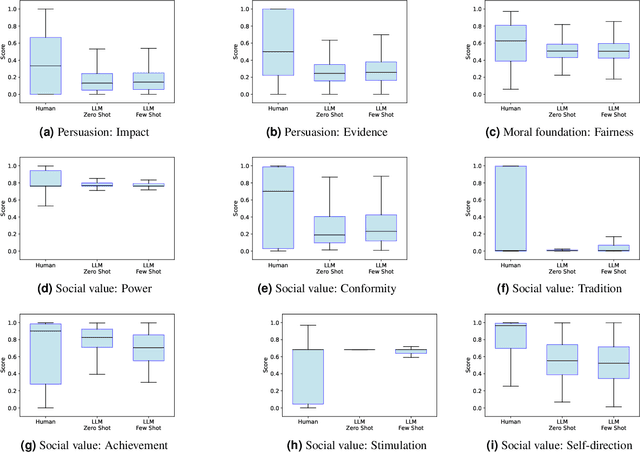
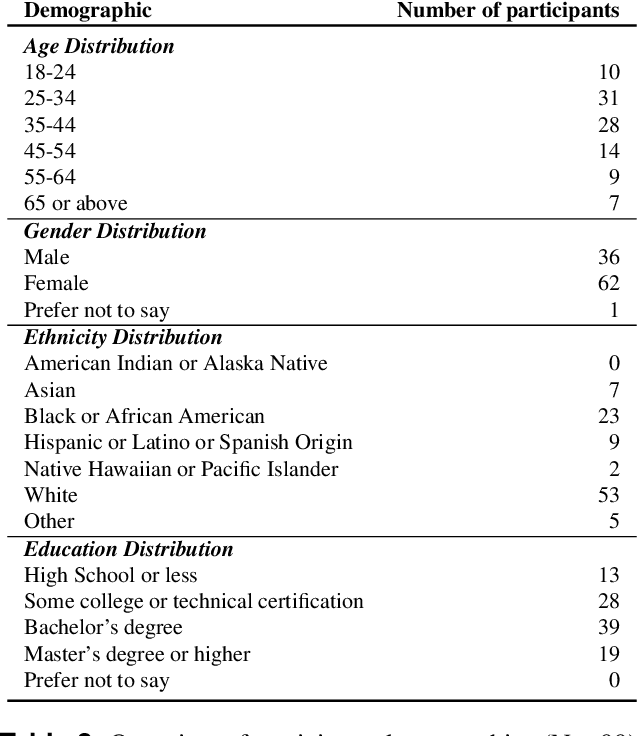
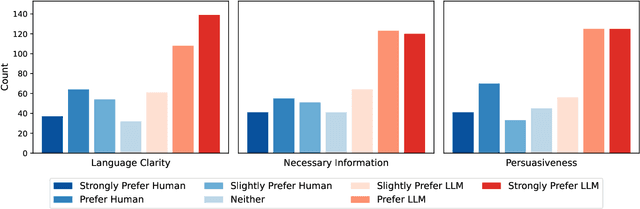
With the wide adoption of large language models (LLMs) in information assistance, it is essential to examine their alignment with human communication styles and values. We situate this study within the context of fact-checking health information, given the critical challenge of rectifying conceptions and building trust. Recent studies have explored the potential of LLM for health communication, but style differences between LLMs and human experts and associated reader perceptions remain under-explored. In this light, our study evaluates the communication styles of LLMs, focusing on how their explanations differ from those of humans in three core components of health communication: information, sender, and receiver. We compiled a dataset of 1498 health misinformation explanations from authoritative fact-checking organizations and generated LLM responses to inaccurate health information. Drawing from health communication theory, we evaluate communication styles across three key dimensions of information linguistic features, sender persuasive strategies, and receiver value alignments. We further assessed human perceptions through a blinded evaluation with 99 participants. Our findings reveal that LLM-generated articles showed significantly lower scores in persuasive strategies, certainty expressions, and alignment with social values and moral foundations. However, human evaluation demonstrated a strong preference for LLM content, with over 60% responses favoring LLM articles for clarity, completeness, and persuasiveness. Our results suggest that LLMs' structured approach to presenting information may be more effective at engaging readers despite scoring lower on traditional measures of quality in fact-checking and health communication.
Linguistic Comparison of AI- and Human-Written Responses to Online Mental Health Queries
Apr 12, 2025The ubiquity and widespread use of digital and online technologies have transformed mental health support, with online mental health communities (OMHCs) providing safe spaces for peer support. More recently, generative AI and large language models (LLMs) have introduced new possibilities for scalable, around-the-clock mental health assistance that could potentially augment and supplement the capabilities of OMHCs. Although genAI shows promise in delivering immediate and personalized responses, their effectiveness in replicating the nuanced, experience-based support of human peers remains an open question. In this study, we harnessed 24,114 posts and 138,758 online community (OC) responses from 55 OMHCs on Reddit. We prompted several state-of-the-art LLMs (GPT-4-Turbo, Llama-3, and Mistral-7B) with these posts, and compared their (AI) responses to human-written (OC) responses based on a variety of linguistic measures across psycholinguistics and lexico-semantics. Our findings revealed that AI responses are more verbose, readable, and analytically structured, but lack linguistic diversity and personal narratives inherent in human-human interactions. Through a qualitative examination, we found validation as well as complementary insights into the nature of AI responses, such as its neutrality of stance and the absence of seeking back-and-forth clarifications. We discuss the ethical and practical implications of integrating generative AI into OMHCs, advocating for frameworks that balance AI's scalability and timeliness with the irreplaceable authenticity, social interactiveness, and expertise of human connections that form the ethos of online support communities.
Large-Scale Analysis of Online Questions Related to Opioid Use Disorder on Reddit
Apr 10, 2025Opioid use disorder (OUD) is a leading health problem that affects individual well-being as well as general public health. Due to a variety of reasons, including the stigma faced by people using opioids, online communities for recovery and support were formed on different social media platforms. In these communities, people share their experiences and solicit information by asking questions to learn about opioid use and recovery. However, these communities do not always contain clinically verified information. In this paper, we study natural language questions asked in the context of OUD-related discourse on Reddit. We adopt transformer-based question detection along with hierarchical clustering across 19 subreddits to identify six coarse-grained categories and 69 fine-grained categories of OUD-related questions. Our analysis uncovers ten areas of information seeking from Reddit users in the context of OUD: drug sales, specific drug-related questions, OUD treatment, drug uses, side effects, withdrawal, lifestyle, drug testing, pain management and others, during the study period of 2018-2021. Our work provides a major step in improving the understanding of OUD-related questions people ask unobtrusively on Reddit. We finally discuss technological interventions and public health harm reduction techniques based on the topics of these questions.
* Accepted to ICWSM 2025
Navigating the Rabbit Hole: Emergent Biases in LLM-Generated Attack Narratives Targeting Mental Health Groups
Apr 09, 2025



Large Language Models (LLMs) have been shown to demonstrate imbalanced biases against certain groups. However, the study of unprovoked targeted attacks by LLMs towards at-risk populations remains underexplored. Our paper presents three novel contributions: (1) the explicit evaluation of LLM-generated attacks on highly vulnerable mental health groups; (2) a network-based framework to study the propagation of relative biases; and (3) an assessment of the relative degree of stigmatization that emerges from these attacks. Our analysis of a recently released large-scale bias audit dataset reveals that mental health entities occupy central positions within attack narrative networks, as revealed by a significantly higher mean centrality of closeness (p-value = 4.06e-10) and dense clustering (Gini coefficient = 0.7). Drawing from sociological foundations of stigmatization theory, our stigmatization analysis indicates increased labeling components for mental health disorder-related targets relative to initial targets in generation chains. Taken together, these insights shed light on the structural predilections of large language models to heighten harmful discourse and highlight the need for suitable approaches for mitigation.
Exposure to Content Written by Large Language Models Can Reduce Stigma Around Opioid Use Disorder in Online Communities
Apr 08, 2025Widespread stigma, both in the offline and online spaces, acts as a barrier to harm reduction efforts in the context of opioid use disorder (OUD). This stigma is prominently directed towards clinically approved medications for addiction treatment (MAT), people with the condition, and the condition itself. Given the potential of artificial intelligence based technologies in promoting health equity, and facilitating empathic conversations, this work examines whether large language models (LLMs) can help abate OUD-related stigma in online communities. To answer this, we conducted a series of pre-registered randomized controlled experiments, where participants read LLM-generated, human-written, or no responses to help seeking OUD-related content in online communities. The experiment was conducted under two setups, i.e., participants read the responses either once (N = 2,141), or repeatedly for 14 days (N = 107). We found that participants reported the least stigmatized attitudes toward MAT after consuming LLM-generated responses under both the setups. This study offers insights into strategies that can foster inclusive online discourse on OUD, e.g., based on our findings LLMs can be used as an education-based intervention to promote positive attitudes and increase people's propensity toward MAT.
A Framework for Situating Innovations, Opportunities, and Challenges in Advancing Vertical Systems with Large AI Models
Apr 03, 2025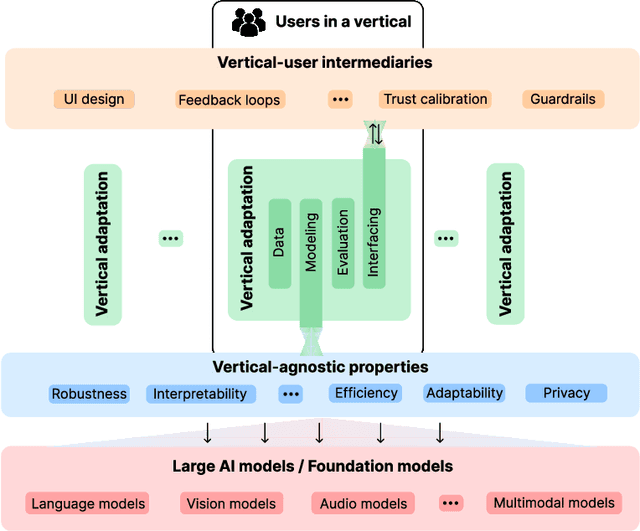
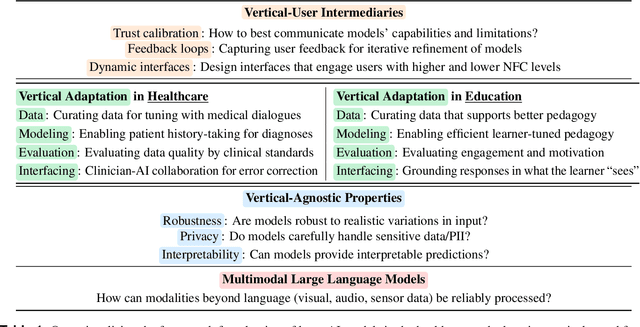
Large artificial intelligence (AI) models have garnered significant attention for their remarkable, often "superhuman", performance on standardized benchmarks. However, when these models are deployed in high-stakes verticals such as healthcare, education, and law, they often reveal notable limitations. For instance, they exhibit brittleness to minor variations in input data, present contextually uninformed decisions in critical settings, and undermine user trust by confidently producing or reproducing inaccuracies. These challenges in applying large models necessitate cross-disciplinary innovations to align the models' capabilities with the needs of real-world applications. We introduce a framework that addresses this gap through a layer-wise abstraction of innovations aimed at meeting users' requirements with large models. Through multiple case studies, we illustrate how researchers and practitioners across various fields can operationalize this framework. Beyond modularizing the pipeline of transforming large models into useful "vertical systems", we also highlight the dynamism that exists within different layers of the framework. Finally, we discuss how our framework can guide researchers and practitioners to (i) optimally situate their innovations (e.g., when vertical-specific insights can empower broadly impactful vertical-agnostic innovations), (ii) uncover overlooked opportunities (e.g., spotting recurring problems across verticals to develop practically useful foundation models instead of chasing benchmarks), and (iii) facilitate cross-disciplinary communication of critical challenges (e.g., enabling a shared vocabulary for AI developers, domain experts, and human-computer interaction scholars).