 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop
Aug 28, 2025Generative AI (GenAI) radically expands the scope and capability of automation for work, education, and everyday tasks, a transformation posing both risks and opportunities for human cognition. How will human cognition change, and what opportunities are there for GenAI to augment it? Which theories, metrics, and other tools are needed to address these questions? The CHI 2025 workshop on Tools for Thought aimed to bridge an emerging science of how the use of GenAI affects human thought, from metacognition to critical thinking, memory, and creativity, with an emerging design practice for building GenAI tools that both protect and augment human thought. Fifty-six researchers, designers, and thinkers from across disciplines as well as industry and academia, along with 34 papers and portfolios, seeded a day of discussion, ideation, and community-building. We synthesize this material here to begin mapping the space of research and design opportunities and to catalyze a multidisciplinary community around this pressing area of research.
Orchid: Orchestrating Context Across Creative Workflows with Generative AI
Aug 27, 2025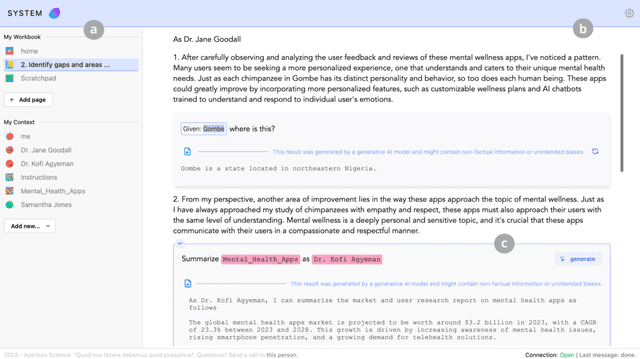

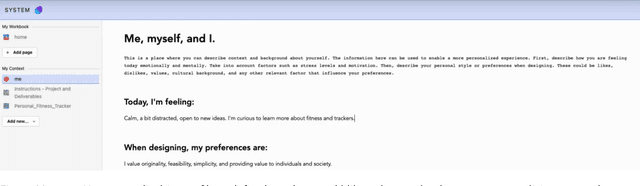
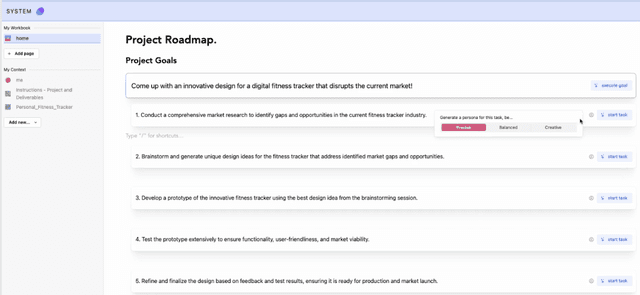
Context is critical for meaningful interactions between people and Generative AI (GenAI). Yet mainstream tools offer limited means to orchestrate it, particularly across workflows that span multiple interactions, sessions, and models, as often occurs in creative projects. Re specifying prior details, juggling diverse artifacts, and dealing with context drift overwhelm users, obscure intent, and curtail creativity. To address these challenges, we present Orchid, a system that gives its users affordances to specify, reference, and monitor context throughout evolving workflows. Specifically, Orchid enables users to (1) specify context related to the project, themselves, and different styles, (2) reference these via explicit mentions, inline selection, or implicit grounding, and (3) monitor context assigned to different interactions across the workflow. In a within-subjects study (n=12), participants using Orchid to execute creative tasks (compared to a baseline toolkit of web search, LLM-based chat, and digital notebooks) produced more novel and feasible outcomes, reporting greater alignment between their intent and the AI's responses, higher perceived control, and increased transparency. By prioritizing context orchestration, Orchid offers an actionable step toward next generation GenAI tools that support complex, iterative workflows - enabling creators and AI to stay aligned and augment their creative potential.
Longitudinal Study on Social and Emotional Use of AI Conversational Agent
Apr 19, 2025Development in digital technologies has continuously reshaped how individuals seek and receive social and emotional support. While online platforms and communities have long served this need, the increased integration of general-purpose conversational AI into daily lives has introduced new dynamics in how support is provided and experienced. Existing research has highlighted both benefits (e.g., wider access to well-being resources) and potential risks (e.g., over-reliance) of using AI for support seeking. In this five-week, exploratory study, we recruited 149 participants divided into two usage groups: a baseline usage group (BU, n=60) that used the internet and AI as usual, and an active usage group (AU, n=89) encouraged to use one of four commercially available AI tools (Microsoft Copilot, Google Gemini, PI AI, ChatGPT) for social and emotional interactions. Our analysis revealed significant increases in perceived attachment towards AI (32.99 percentage points), perceived AI empathy (25.8 p.p.), and motivation to use AI for entertainment (22.90 p.p.) among the AU group. We also observed that individual differences (e.g., gender identity, prior AI usage) influenced perceptions of AI empathy and attachment. Lastly, the AU group expressed higher comfort in seeking personal help, managing stress, obtaining social support, and talking about health with AI, indicating potential for broader emotional support while highlighting the need for safeguards against problematic usage. Overall, our exploratory findings underscore the importance of developing consumer-facing AI tools that support emotional well-being responsibly, while empowering users to understand the limitations of these tools.
From Lived Experience to Insight: Unpacking the Psychological Risks of Using AI Conversational Agents
Dec 12, 2024Recent gain in popularity of AI conversational agents has led to their increased use for improving productivity and supporting well-being. While previous research has aimed to understand the risks associated with interactions with AI conversational agents, these studies often fall short in capturing the lived experiences. Additionally, psychological risks have often been presented as a sub-category within broader AI-related risks in past taxonomy works, leading to under-representation of the impact of psychological risks of AI use. To address these challenges, our work presents a novel risk taxonomy focusing on psychological risks of using AI gathered through lived experience of individuals. We employed a mixed-method approach, involving a comprehensive survey with 283 individuals with lived mental health experience and workshops involving lived experience experts to develop a psychological risk taxonomy. Our taxonomy features 19 AI behaviors, 21 negative psychological impacts, and 15 contexts related to individuals. Additionally, we propose a novel multi-path vignette based framework for understanding the complex interplay between AI behaviors, psychological impacts, and individual user contexts. Finally, based on the feedback obtained from the workshop sessions, we present design recommendations for developing safer and more robust AI agents. Our work offers an in-depth understanding of the psychological risks associated with AI conversational agents and provides actionable recommendations for policymakers, researchers, and developers.
Data Analysis in the Era of Generative AI
Sep 27, 2024



This paper explores the potential of AI-powered tools to reshape data analysis, focusing on design considerations and challenges. We explore how the emergence of large language and multimodal models offers new opportunities to enhance various stages of data analysis workflow by translating high-level user intentions into executable code, charts, and insights. We then examine human-centered design principles that facilitate intuitive interactions, build user trust, and streamline the AI-assisted analysis workflow across multiple apps. Finally, we discuss the research challenges that impede the development of these AI-based systems such as enhancing model capabilities, evaluating and benchmarking, and understanding end-user needs.
GhostWriter: Augmenting Collaborative Human-AI Writing Experiences Through Personalization and Agency
Feb 13, 2024

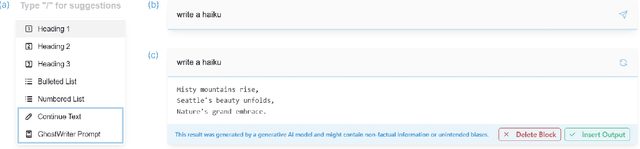
Large language models (LLMs) are becoming more prevalent and have found a ubiquitous use in providing different forms of writing assistance. However, LLM-powered writing systems can frustrate users due to their limited personalization and control, which can be exacerbated when users lack experience with prompt engineering. We see design as one way to address these challenges and introduce GhostWriter, an AI-enhanced writing design probe where users can exercise enhanced agency and personalization. GhostWriter leverages LLMs to learn the user's intended writing style implicitly as they write, while allowing explicit teaching moments through manual style edits and annotations. We study 18 participants who use GhostWriter on two different writing tasks, observing that it helps users craft personalized text generations and empowers them by providing multiple ways to control the system's writing style. From this study, we present insights regarding people's relationship with AI-assisted writing and offer design recommendations for future work.
From User Surveys to Telemetry-Driven Agents: Exploring the Potential of Personalized Productivity Solutions
Jan 17, 2024
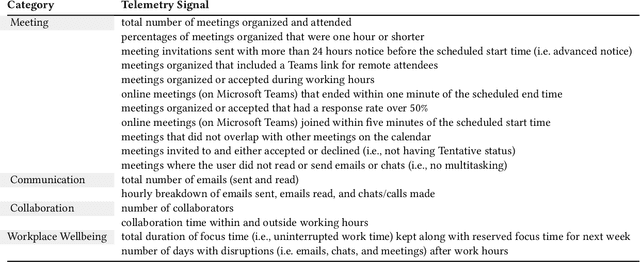
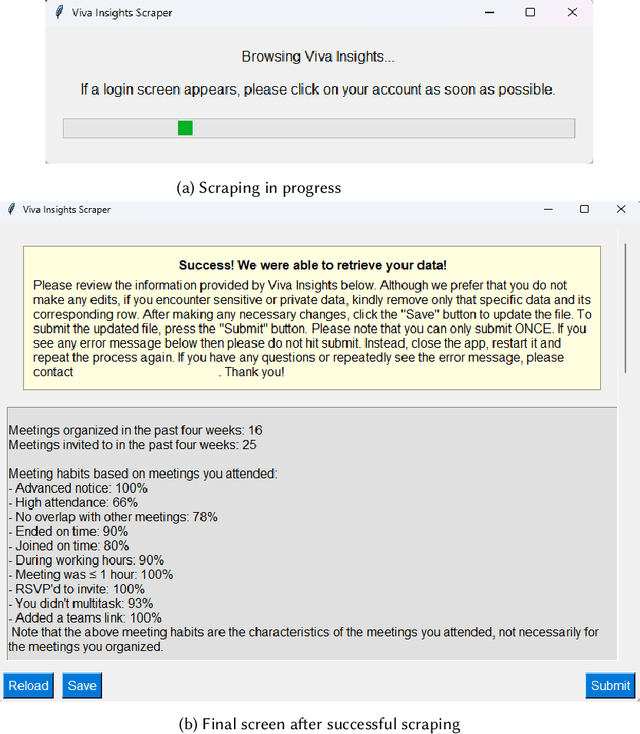
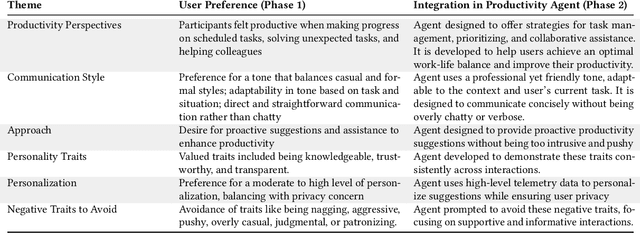
We present a comprehensive, user-centric approach to understand preferences in AI-based productivity agents and develop personalized solutions tailored to users' needs. Utilizing a two-phase method, we first conducted a survey with 363 participants, exploring various aspects of productivity, communication style, agent approach, personality traits, personalization, and privacy. Drawing on the survey insights, we developed a GPT-4 powered personalized productivity agent that utilizes telemetry data gathered via Viva Insights from information workers to provide tailored assistance. We compared its performance with alternative productivity-assistive tools, such as dashboard and narrative, in a study involving 40 participants. Our findings highlight the importance of user-centric design, adaptability, and the balance between personalization and privacy in AI-assisted productivity tools. By building on the insights distilled from our study, we believe that our work can enable and guide future research to further enhance productivity solutions, ultimately leading to optimized efficiency and user experiences for information workers.
Affective Conversational Agents: Understanding Expectations and Personal Influences
Oct 19, 2023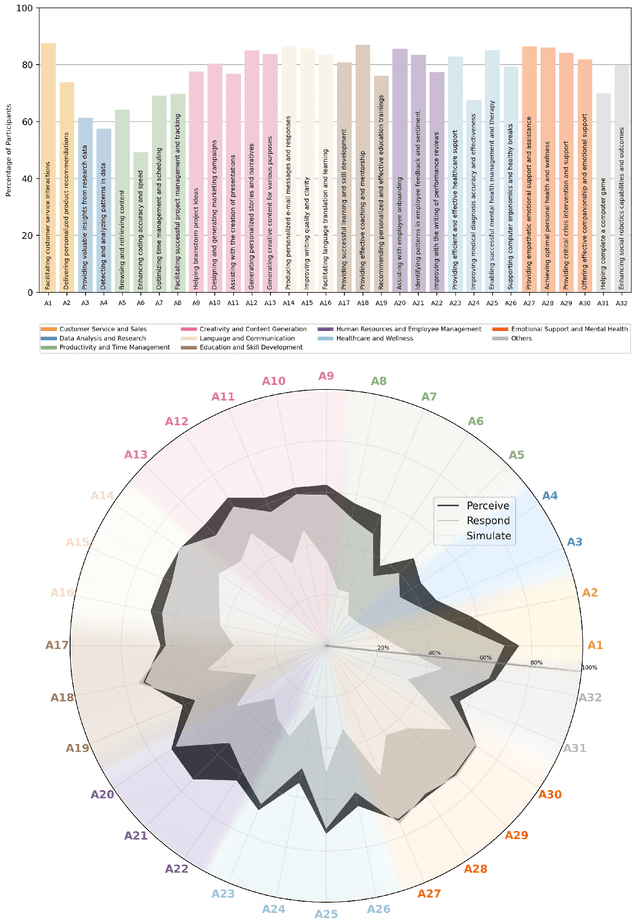
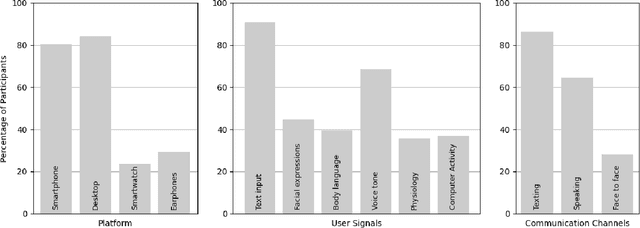
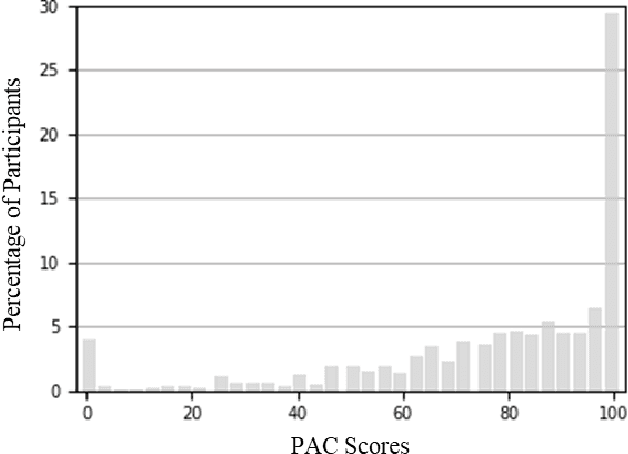

The rise of AI conversational agents has broadened opportunities to enhance human capabilities across various domains. As these agents become more prevalent, it is crucial to investigate the impact of different affective abilities on their performance and user experience. In this study, we surveyed 745 respondents to understand the expectations and preferences regarding affective skills in various applications. Specifically, we assessed preferences concerning AI agents that can perceive, respond to, and simulate emotions across 32 distinct scenarios. Our results indicate a preference for scenarios that involve human interaction, emotional support, and creative tasks, with influences from factors such as emotional reappraisal and personality traits. Overall, the desired affective skills in AI agents depend largely on the application's context and nature, emphasizing the need for adaptability and context-awareness in the design of affective AI conversational agents.
Where does a computer vision model make mistakes? Using interactive visualizations to find where and how CV models can improve
May 19, 2023
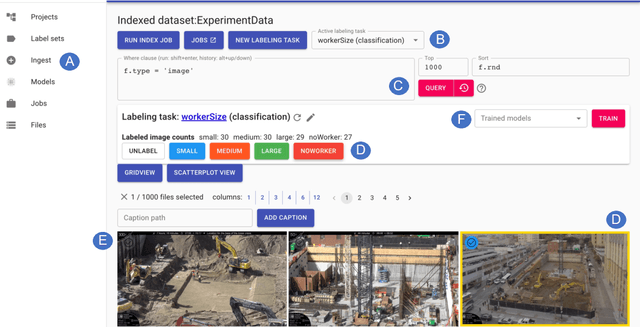
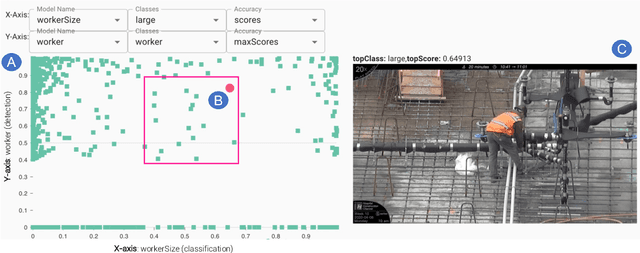
Creating Computer Vision (CV) models remains a complex and taxing practice for end-users to build, inspect, and improve these models. Interactive ML perspectives have helped address some of these issues by considering a teacher-in-the-loop where planning, teaching, and evaluating tasks take place. To improve the experience of end-users with various levels of ML expertise, we designed and evaluated two interactive visualizations in the context of Sprite, a system for creating CV classification and detection models for images originating from videos. We study how these visualizations, as part of the machine teaching loop, help users identify (evaluate) and select (plan) images where a model is struggling and improve the model being trained. We found that users who had used the visualizations found more images across a wider set of potential types of model errors, as well as in assessing and contrasting the prediction behavior of one or more models, thus reducing the potential effort required to improve a model.
NL-EDIT: Correcting semantic parse errors through natural language interaction
Mar 26, 2021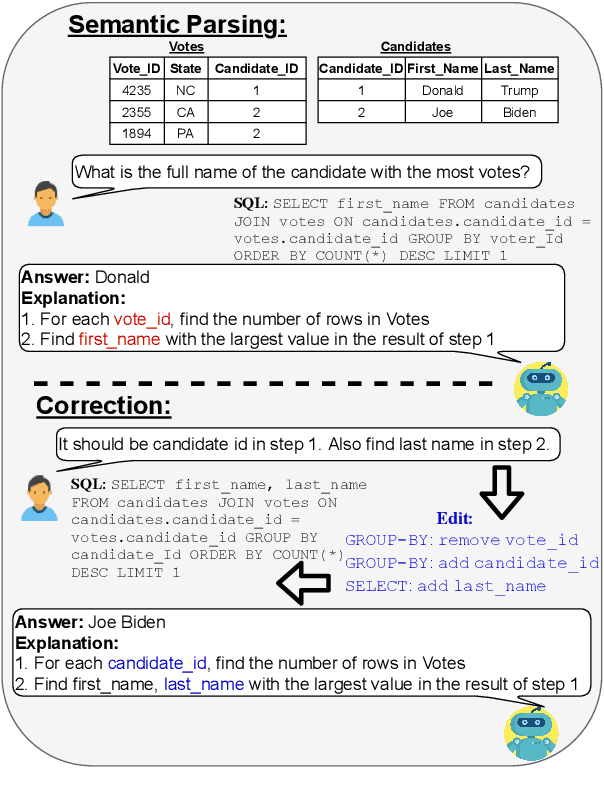


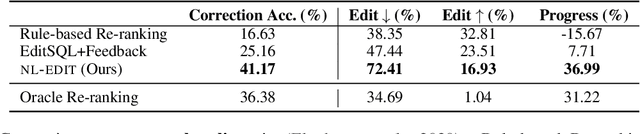
We study semantic parsing in an interactive setting in which users correct errors with natural language feedback. We present NL-EDIT, a model for interpreting natural language feedback in the interaction context to generate a sequence of edits that can be applied to the initial parse to correct its errors. We show that NL-EDIT can boost the accuracy of existing text-to-SQL parsers by up to 20% with only one turn of correction. We analyze the limitations of the model and discuss directions for improvement and evaluation. The code and datasets used in this paper are publicly available at http://aka.ms/NLEdit.