 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentinelBench: A Benchmark for Long-Running Monitoring Agents
Jun 03, 2026AI agents are increasingly asked to carry out work that spans minutes, hours, or longer. Yet the default model of agent behavior is continuous action: issuing tool calls, refreshing pages, searching for alternatives, or otherwise trying to force progress. This is the wrong approach for many long-running tasks, which are better served by a strategy of sustained attention. Instead, agents should monitor an environment, notice when an external event makes progress possible, then respond promptly without wasting resources while waiting. To measure progress on this class of tasks, we introduce SentinelBench, an open-source benchmark for time-evolving monitoring tasks. SentinelBench contains 100 tasks across 10 synthetic web environments, including email, calendars, finance, professional networking, and entertainment. Each environment exposes a live web interface and replays a scripted sequence of events, requiring agents to navigate and reason about web pages whose state shifts underfoot. SentinelBench measures task completion, reaction time, and resource use, exposing the tradeoff between responsiveness and cost. We report results across three models and two browser-agent harnesses, establishing performance baselines for future comparison and demonstrating how agent design choices can dramatically impact key metrics. Together, these results show that SentinelBench distinguishes meaningful differences in agent behavior.
Overseeing Agents Without Constant Oversight: Challenges and Opportunities
Feb 18, 2026To enable human oversight, agentic AI systems often provide a trace of reasoning and action steps. Designing traces to have an informative, but not overwhelming, level of detail remains a critical challenge. In three user studies on a Computer User Agent, we investigate the utility of basic action traces for verification, explore three alternatives via design probes, and test a novel interface's impact on error finding in question-answering tasks. As expected, we find that current practices are cumbersome, limiting their efficacy. Conversely, our proposed design reduced the time participants spent finding errors. However, although participants reported higher levels of confidence in their decisions, their final accuracy was not meaningfully improved. To this end, our study surfaces challenges for human verification of agentic systems, including managing built-in assumptions, users' subjective and changing correctness criteria, and the shortcomings, yet importance, of communicating the agent's process.
Magentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Navigating Rifts in Human-LLM Grounding: Study and Benchmark
Mar 18, 2025Language models excel at following instructions but often struggle with the collaborative aspects of conversation that humans naturally employ. This limitation in grounding -- the process by which conversation participants establish mutual understanding -- can lead to outcomes ranging from frustrated users to serious consequences in high-stakes scenarios. To systematically study grounding challenges in human-LLM interactions, we analyze logs from three human-assistant datasets: WildChat, MultiWOZ, and Bing Chat. We develop a taxonomy of grounding acts and build models to annotate and forecast grounding behavior. Our findings reveal significant differences in human-human and human-LLM grounding: LLMs were three times less likely to initiate clarification and sixteen times less likely to provide follow-up requests than humans. Additionally, early grounding failures predicted later interaction breakdowns. Building on these insights, we introduce RIFTS: a benchmark derived from publicly available LLM interaction data containing situations where LLMs fail to initiate grounding. We note that current frontier models perform poorly on RIFTS, highlighting the need to reconsider how we train and prompt LLMs for human interaction. To this end, we develop a preliminary intervention that mitigates grounding failures.
Interactive Debugging and Steering of Multi-Agent AI Systems
Mar 03, 2025Fully autonomous teams of LLM-powered AI agents are emerging that collaborate to perform complex tasks for users. What challenges do developers face when trying to build and debug these AI agent teams? In formative interviews with five AI agent developers, we identify core challenges: difficulty reviewing long agent conversations to localize errors, lack of support in current tools for interactive debugging, and the need for tool support to iterate on agent configuration. Based on these needs, we developed an interactive multi-agent debugging tool, AGDebugger, with a UI for browsing and sending messages, the ability to edit and reset prior agent messages, and an overview visualization for navigating complex message histories. In a two-part user study with 14 participants, we identify common user strategies for steering agents and highlight the importance of interactive message resets for debugging. Our studies deepen understanding of interfaces for debugging increasingly important agentic workflows.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024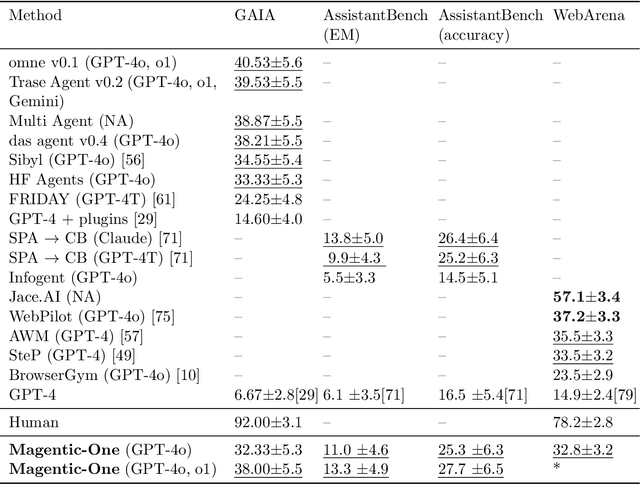
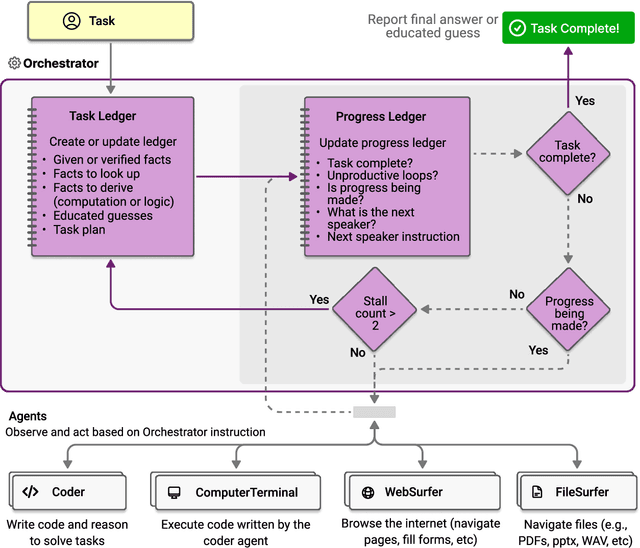
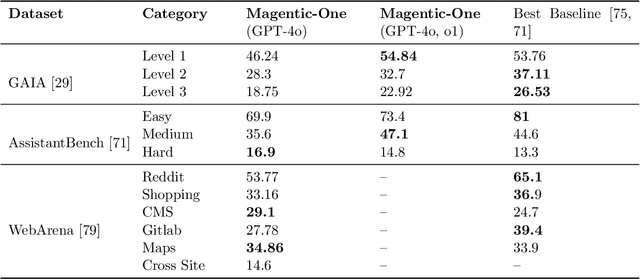
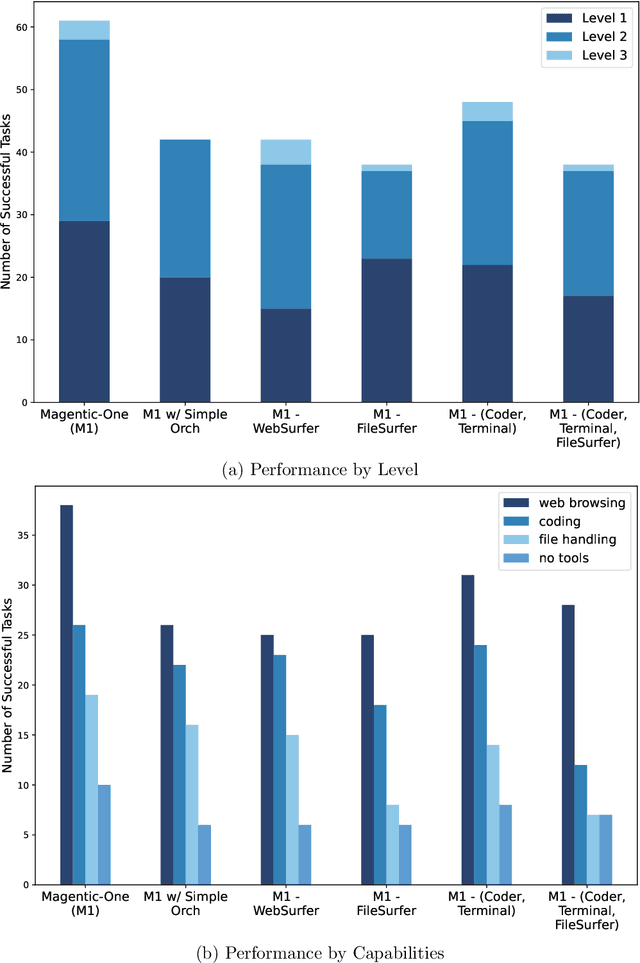
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Towards better Human-Agent Alignment: Assessing Task Utility in LLM-Powered Applications
Feb 22, 2024The rapid development in the field of Large Language Models (LLMs) has led to a surge in applications that facilitate collaboration among multiple agents to assist humans in their daily tasks. However, a significant gap remains in assessing whether LLM-powered applications genuinely enhance user experience and task execution efficiency. This highlights the pressing need for methods to verify utility of LLM-powered applications, particularly by ensuring alignment between the application's functionality and end-user needs. We introduce AgentEval provides an implementation for the math problems, a novel framework designed to simplify the utility verification process by automatically proposing a set of criteria tailored to the unique purpose of any given application. This allows for a comprehensive assessment, quantifying the utility of an application against the suggested criteria. We present a comprehensive analysis of the robustness of quantifier's work.
Accurate Measures of Vaccination and Concerns of Vaccine Holdouts from Web Search Logs
Jun 12, 2023To design effective vaccine policies, policymakers need detailed data about who has been vaccinated, who is holding out, and why. However, existing data in the US are insufficient: reported vaccination rates are often delayed or missing, and surveys of vaccine hesitancy are limited by high-level questions and self-report biases. Here, we show how large-scale search engine logs and machine learning can be leveraged to fill these gaps and provide novel insights about vaccine intentions and behaviors. First, we develop a vaccine intent classifier that can accurately detect when a user is seeking the COVID-19 vaccine on search. Our classifier demonstrates strong agreement with CDC vaccination rates, with correlations above 0.86, and estimates vaccine intent rates to the level of ZIP codes in real time, allowing us to pinpoint more granular trends in vaccine seeking across regions, demographics, and time. To investigate vaccine hesitancy, we use our classifier to identify two groups, vaccine early adopters and vaccine holdouts. We find that holdouts, compared to early adopters matched on covariates, are 69% more likely to click on untrusted news sites. Furthermore, we organize 25,000 vaccine-related URLs into a hierarchical ontology of vaccine concerns, and we find that holdouts are far more concerned about vaccine requirements, vaccine development and approval, and vaccine myths, and even within holdouts, concerns vary significantly across demographic groups. Finally, we explore the temporal dynamics of vaccine concerns and vaccine seeking, and find that key indicators emerge when individuals convert from holding out to preparing to accept the vaccine.
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
Jun 08, 2023AI powered code-recommendation systems, such as Copilot and CodeWhisperer, provide code suggestions inside a programmer's environment (e.g., an IDE) with the aim to improve their productivity. Since, in these scenarios, programmers accept and reject suggestions, ideally, such a system should use this feedback in furtherance of this goal. In this work we leverage prior data of programmers interacting with Copilot to develop interventions that can save programmer time. We propose a utility theory framework, which models this interaction with programmers and decides when and which suggestions to display. Our framework Conditional suggestion Display from Human Feedback (CDHF) is based on predictive models of programmer actions. Using data from 535 programmers we build models that predict the likelihood of suggestion acceptance. In a retrospective evaluation on real-world programming tasks solved with AI-assisted programming, we find that CDHF can achieve favorable tradeoffs. Our findings show the promise of integrating human feedback to improve interaction with large language models in scenarios such as programming and possibly writing tasks.
Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
Feb 14, 2023



Large-scale generative models enabled the development of AI-powered code completion tools to assist programmers in writing code. However, much like other AI-powered tools, AI-powered code completions are not always accurate, potentially introducing bugs or even security vulnerabilities into code if not properly detected and corrected by a human programmer. One technique that has been proposed and implemented to help programmers identify potential errors is to highlight uncertain tokens. However, there have been no empirical studies exploring the effectiveness of this technique-- nor investigating the different and not-yet-agreed-upon notions of uncertainty in the context of generative models. We explore the question of whether conveying information about uncertainty enables programmers to more quickly and accurately produce code when collaborating with an AI-powered code completion tool, and if so, what measure of uncertainty best fits programmers' needs. Through a mixed-methods study with 30 programmers, we compare three conditions: providing the AI system's code completion alone, highlighting tokens with the lowest likelihood of being generated by the underlying generative model, and highlighting tokens with the highest predicted likelihood of being edited by a programmer. We find that highlighting tokens with the highest predicted likelihood of being edited leads to faster task completion and more targeted edits, and is subjectively preferred by study participants. In contrast, highlighting tokens according to their probability of being generated does not provide any benefit over the baseline with no highlighting. We further explore the design space of how to convey uncertainty in AI-powered code completion tools, and find that programmers prefer highlights that are granular, informative, interpretable, and not overwhelming.