 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-Relying on Reliance: Towards Realistic Evaluations of AI-Based Clinical Decision Support
Apr 10, 2025As AI-based clinical decision support (AI-CDS) is introduced in more and more aspects of healthcare services, HCI research plays an increasingly important role in designing for complementarity between AI and clinicians. However, current evaluations of AI-CDS often fail to capture when AI is and is not useful to clinicians. This position paper reflects on our work and influential AI-CDS literature to advocate for moving beyond evaluation metrics like Trust, Reliance, Acceptance, and Performance on the AI's task (what we term the "trap" of human-AI collaboration). Although these metrics can be meaningful in some simple scenarios, we argue that optimizing for them ignores important ways that AI falls short of clinical benefit, as well as ways that clinicians successfully use AI. As the fields of HCI and AI in healthcare develop new ways to design and evaluate CDS tools, we call on the community to prioritize ecologically valid, domain-appropriate study setups that measure the emergent forms of value that AI can bring to healthcare professionals.
Interactive Debugging and Steering of Multi-Agent AI Systems
Mar 03, 2025Fully autonomous teams of LLM-powered AI agents are emerging that collaborate to perform complex tasks for users. What challenges do developers face when trying to build and debug these AI agent teams? In formative interviews with five AI agent developers, we identify core challenges: difficulty reviewing long agent conversations to localize errors, lack of support in current tools for interactive debugging, and the need for tool support to iterate on agent configuration. Based on these needs, we developed an interactive multi-agent debugging tool, AGDebugger, with a UI for browsing and sending messages, the ability to edit and reset prior agent messages, and an overview visualization for navigating complex message histories. In a two-part user study with 14 participants, we identify common user strategies for steering agents and highlight the importance of interactive message resets for debugging. Our studies deepen understanding of interfaces for debugging increasingly important agentic workflows.
RECAST: Enabling User Recourse and Interpretability of Toxicity Detection Models with Interactive Visualization
Feb 10, 2021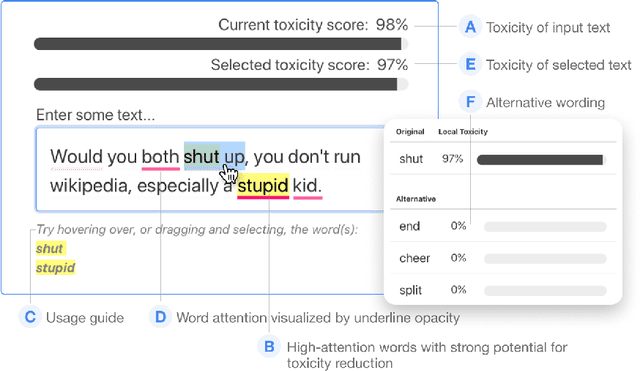


With the widespread use of toxic language online, platforms are increasingly using automated systems that leverage advances in natural language processing to automatically flag and remove toxic comments. However, most automated systems -- when detecting and moderating toxic language -- do not provide feedback to their users, let alone provide an avenue of recourse for these users to make actionable changes. We present our work, RECAST, an interactive, open-sourced web tool for visualizing these models' toxic predictions, while providing alternative suggestions for flagged toxic language. Our work also provides users with a new path of recourse when using these automated moderation tools. RECAST highlights text responsible for classifying toxicity, and allows users to interactively substitute potentially toxic phrases with neutral alternatives. We examined the effect of RECAST via two large-scale user evaluations, and found that RECAST was highly effective at helping users reduce toxicity as detected through the model. Users also gained a stronger understanding of the underlying toxicity criterion used by black-box models, enabling transparency and recourse. In addition, we found that when users focus on optimizing language for these models instead of their own judgement (which is the implied incentive and goal of deploying automated models), these models cease to be effective classifiers of toxicity compared to human annotations. This opens a discussion for how toxicity detection models work and should work, and their effect on the future of online discourse.
RECAST: Interactive Auditing of Automatic Toxicity Detection Models
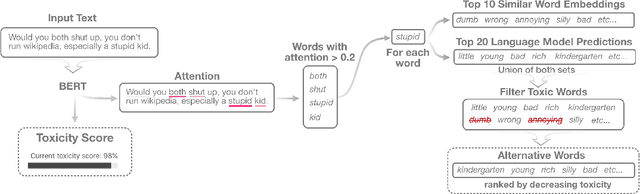
Jan 07, 2020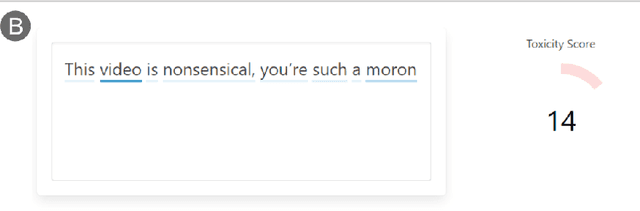
As toxic language becomes nearly pervasive online, there has been increasing interest in leveraging the advancements in natural language processing (NLP), from very large transformer models to automatically detecting and removing toxic comments. Despite the fairness concerns, lack of adversarial robustness, and limited prediction explainability for deep learning systems, there is currently little work for auditing these systems and understanding how they work for both developers and users. We present our ongoing work, RECAST, an interactive tool for examining toxicity detection models by visualizing explanations for predictions and providing alternative wordings for detected toxic speech.
FairVis: Visual Analytics for Discovering Intersectional Bias in Machine Learning
Apr 10, 2019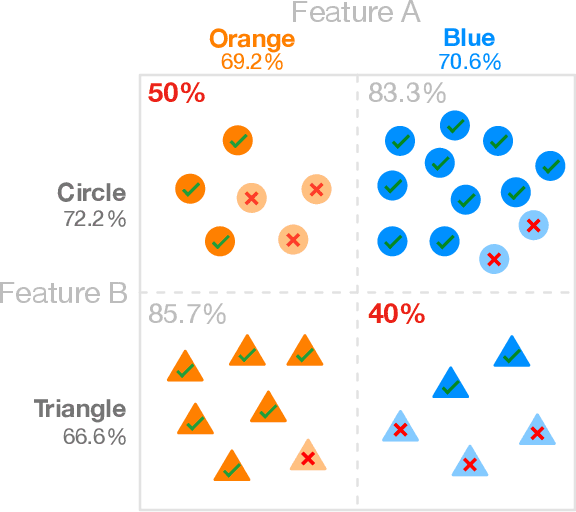
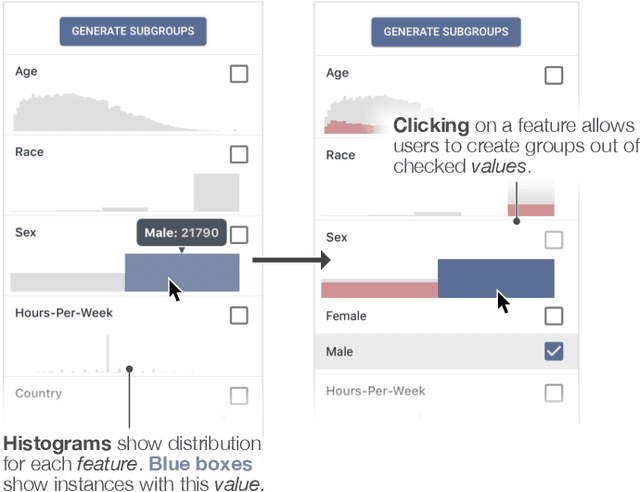
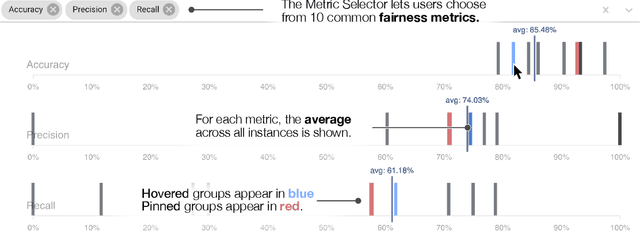
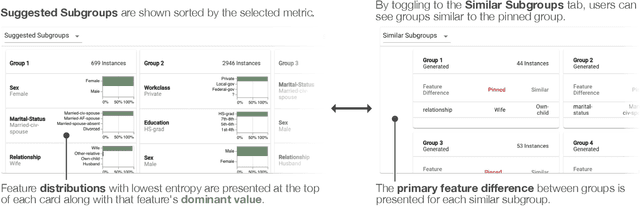
The growing capability and accessibility of machine learning has led to its application to many real-world domains and data about people. Despite the benefits algorithmic systems may bring, models can reflect, inject, or exacerbate implicit and explicit societal biases into their outputs, disadvantaging certain demographic subgroups. Discovering which biases a machine learning model has introduced is a great challenge, due to the numerous definitions of fairness and the large number of potentially impacted subgroups. We present FairVis, a mixed-initiative visual analytics system that integrates a novel subgroup discovery technique for users to audit the fairness of machine learning models. Through FairVis, users can apply domain knowledge to generate and investigate known subgroups, and explore suggested and similar subgroups. FairVis' coordinated views enable users to explore a high-level overview of subgroup performance and subsequently drill down into detailed investigation of specific subgroups. We show how FairVis helps to discover biases in two real datasets used in predicting income and recidivism. As a visual analytics system devoted to discovering bias in machine learning, FairVis demonstrates how interactive visualization may help data scientists and the general public in understanding and creating more equitable algorithmic systems.