 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Impact of Human Capital, Job History, and Language Factors on Job Seniority with a Large-scale Analysis of Resumes
Jun 15, 2021

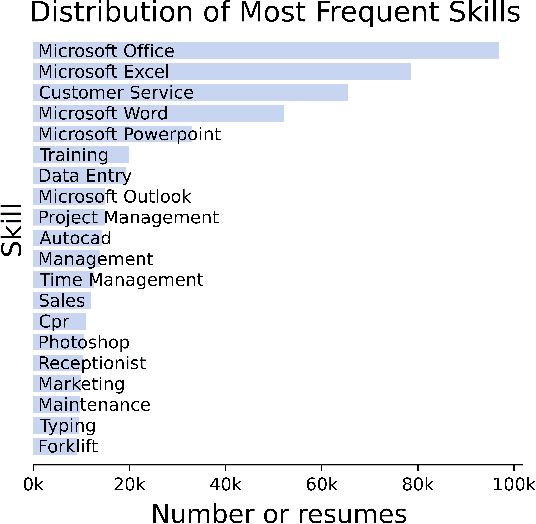
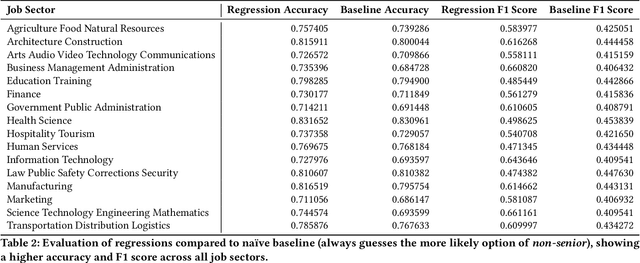
As job markets worldwide have become more competitive and applicant selection criteria have become more opaque, and different (and sometimes contradictory) information and advice is available for job seekers wishing to progress in their careers, it has never been more difficult to determine which factors in a r\'esum\'e most effectively help career progression. In this work we present a novel, large scale dataset of over half a million r\'esum\'es with preliminary analysis to begin to answer empirically which factors help or hurt people wishing to transition to more senior roles as they progress in their career. We find that previous experience forms the most important factor, outweighing other aspects of human capital, and find which language factors in a r\'esum\'e have significant effects. This lays the groundwork for future inquiry in career trajectories using large scale data analysis and natural language processing techniques.
EnergyVis: Interactively Tracking and Exploring Energy Consumption for ML Models
Mar 30, 2021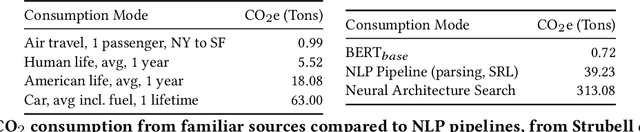
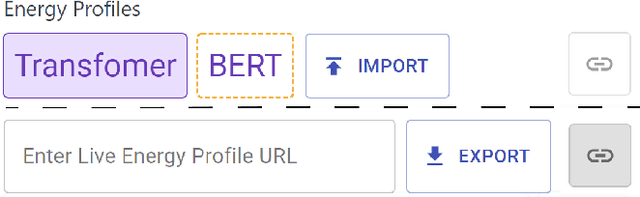
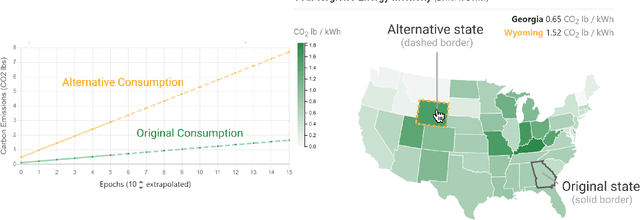
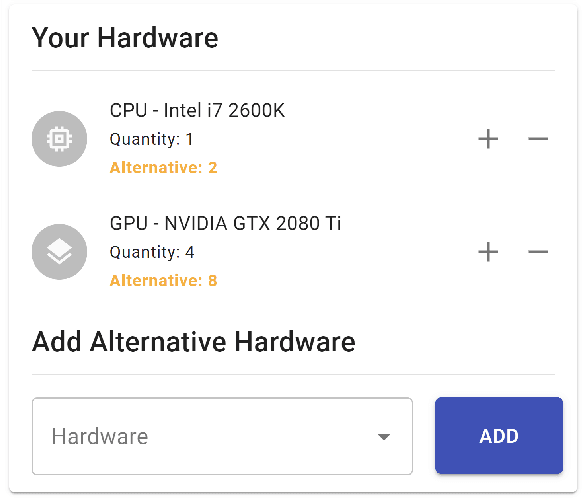
The advent of larger machine learning (ML) models have improved state-of-the-art (SOTA) performance in various modeling tasks, ranging from computer vision to natural language. As ML models continue increasing in size, so does their respective energy consumption and computational requirements. However, the methods for tracking, reporting, and comparing energy consumption remain limited. We presentEnergyVis, an interactive energy consumption tracker for ML models. Consisting of multiple coordinated views, EnergyVis enables researchers to interactively track, visualize and compare model energy consumption across key energy consumption and carbon footprint metrics (kWh and CO2), helping users explore alternative deployment locations and hardware that may reduce carbon footprints. EnergyVis aims to raise awareness concerning computational sustainability by interactively highlighting excessive energy usage during model training; and by providing alternative training options to reduce energy usage.
RECAST: Enabling User Recourse and Interpretability of Toxicity Detection Models with Interactive Visualization
Feb 10, 2021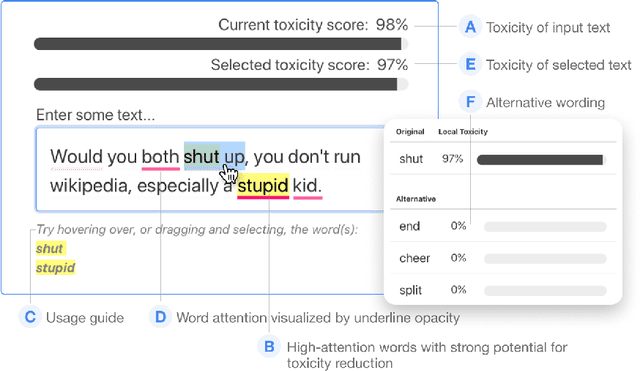

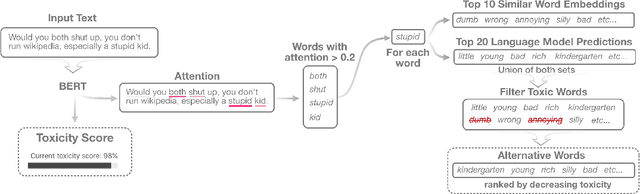

With the widespread use of toxic language online, platforms are increasingly using automated systems that leverage advances in natural language processing to automatically flag and remove toxic comments. However, most automated systems -- when detecting and moderating toxic language -- do not provide feedback to their users, let alone provide an avenue of recourse for these users to make actionable changes. We present our work, RECAST, an interactive, open-sourced web tool for visualizing these models' toxic predictions, while providing alternative suggestions for flagged toxic language. Our work also provides users with a new path of recourse when using these automated moderation tools. RECAST highlights text responsible for classifying toxicity, and allows users to interactively substitute potentially toxic phrases with neutral alternatives. We examined the effect of RECAST via two large-scale user evaluations, and found that RECAST was highly effective at helping users reduce toxicity as detected through the model. Users also gained a stronger understanding of the underlying toxicity criterion used by black-box models, enabling transparency and recourse. In addition, we found that when users focus on optimizing language for these models instead of their own judgement (which is the implied incentive and goal of deploying automated models), these models cease to be effective classifiers of toxicity compared to human annotations. This opens a discussion for how toxicity detection models work and should work, and their effect on the future of online discourse.