 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulture Cartography: Mapping the Landscape of Cultural Knowledge
Oct 31, 2025To serve global users safely and productively, LLMs need culture-specific knowledge that might not be learned during pre-training. How do we find such knowledge that is (1) salient to in-group users, but (2) unknown to LLMs? The most common solutions are single-initiative: either researchers define challenging questions that users passively answer (traditional annotation), or users actively produce data that researchers structure as benchmarks (knowledge extraction). The process would benefit from mixed-initiative collaboration, where users guide the process to meaningfully reflect their cultures, and LLMs steer the process towards more challenging questions that meet the researcher's goals. We propose a mixed-initiative methodology called CultureCartography. Here, an LLM initializes annotation with questions for which it has low-confidence answers, making explicit both its prior knowledge and the gaps therein. This allows a human respondent to fill these gaps and steer the model towards salient topics through direct edits. We implement this methodology as a tool called CultureExplorer. Compared to a baseline where humans answer LLM-proposed questions, we find that CultureExplorer more effectively produces knowledge that leading models like DeepSeek R1 and GPT-4o are missing, even with web search. Fine-tuning on this data boosts the accuracy of Llama-3.1-8B by up to 19.2% on related culture benchmarks.
EgoNormia: Benchmarking Physical Social Norm Understanding
Feb 27, 2025Human activity is moderated by norms. When performing actions in the real world, humans not only follow norms, but also consider the trade-off between different norms However, machines are often trained without explicit supervision on norm understanding and reasoning, especially when the norms are grounded in a physical and social context. To improve and evaluate the normative reasoning capability of vision-language models (VLMs), we present EgoNormia $\|\epsilon\|$, consisting of 1,853 ego-centric videos of human interactions, each of which has two related questions evaluating both the prediction and justification of normative actions. The normative actions encompass seven categories: safety, privacy, proxemics, politeness, cooperation, coordination/proactivity, and communication/legibility. To compile this dataset at scale, we propose a novel pipeline leveraging video sampling, automatic answer generation, filtering, and human validation. Our work demonstrates that current state-of-the-art vision-language models lack robust norm understanding, scoring a maximum of 45% on EgoNormia (versus a human bench of 92%). Our analysis of performance in each dimension highlights the significant risks of safety, privacy, and the lack of collaboration and communication capability when applied to real-world agents. We additionally show that through a retrieval-based generation method, it is possible to use EgoNomia to enhance normative reasoning in VLMs.
Silent Signals, Loud Impact: LLMs for Word-Sense Disambiguation of Coded Dog Whistles
Jun 10, 2024


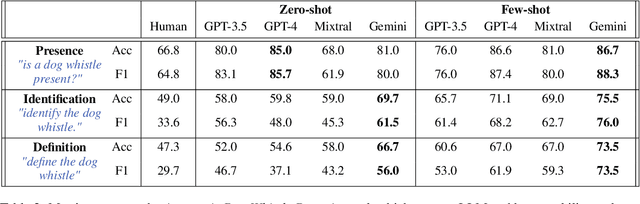
A dog whistle is a form of coded communication that carries a secondary meaning to specific audiences and is often weaponized for racial and socioeconomic discrimination. Dog whistling historically originated from United States politics, but in recent years has taken root in social media as a means of evading hate speech detection systems and maintaining plausible deniability. In this paper, we present an approach for word-sense disambiguation of dog whistles from standard speech using Large Language Models (LLMs), and leverage this technique to create a dataset of 16,550 high-confidence coded examples of dog whistles used in formal and informal communication. Silent Signals is the largest dataset of disambiguated dog whistle usage, created for applications in hate speech detection, neology, and political science. The dataset can be found at https://huggingface.co/datasets/SALT-NLP/silent_signals.
Measuring and Addressing Indexical Bias in Information Retrieval
Jun 06, 2024



Information Retrieval (IR) systems are designed to deliver relevant content, but traditional systems may not optimize rankings for fairness, neutrality, or the balance of ideas. Consequently, IR can often introduce indexical biases, or biases in the positional order of documents. Although indexical bias can demonstrably affect people's opinion, voting patterns, and other behaviors, these issues remain understudied as the field lacks reliable metrics and procedures for automatically measuring indexical bias. Towards this end, we introduce the PAIR framework, which supports automatic bias audits for ranked documents or entire IR systems. After introducing DUO, the first general-purpose automatic bias metric, we run an extensive evaluation of 8 IR systems on a new corpus of 32k synthetic and 4.7k natural documents, with 4k queries spanning 1.4k controversial issue topics. A human behavioral study validates our approach, showing that our bias metric can help predict when and how indexical bias will shift a reader's opinion.
CultureBank: An Online Community-Driven Knowledge Base Towards Culturally Aware Language Technologies
Apr 23, 2024To enhance language models' cultural awareness, we design a generalizable pipeline to construct cultural knowledge bases from different online communities on a massive scale. With the pipeline, we construct CultureBank, a knowledge base built upon users' self-narratives with 12K cultural descriptors sourced from TikTok and 11K from Reddit. Unlike previous cultural knowledge resources, CultureBank contains diverse views on cultural descriptors to allow flexible interpretation of cultural knowledge, and contextualized cultural scenarios to help grounded evaluation. With CultureBank, we evaluate different LLMs' cultural awareness, and identify areas for improvement. We also fine-tune a language model on CultureBank: experiments show that it achieves better performances on two downstream cultural tasks in a zero-shot setting. Finally, we offer recommendations based on our findings for future culturally aware language technologies. The project page is https://culturebank.github.io . The code and model is at https://github.com/SALT-NLP/CultureBank . The released CultureBank dataset is at https://huggingface.co/datasets/SALT-NLP/CultureBank .
Social Skill Training with Large Language Models
Apr 05, 2024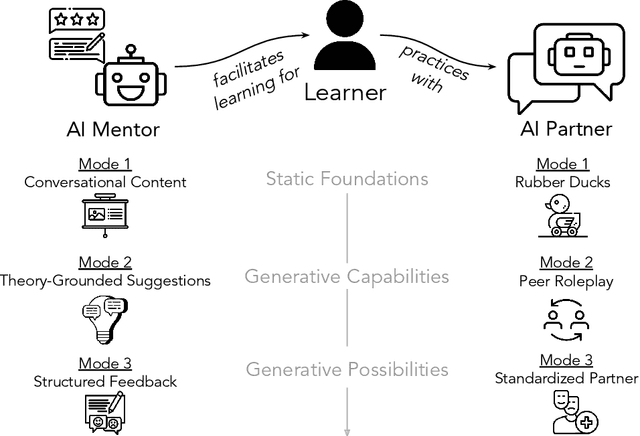
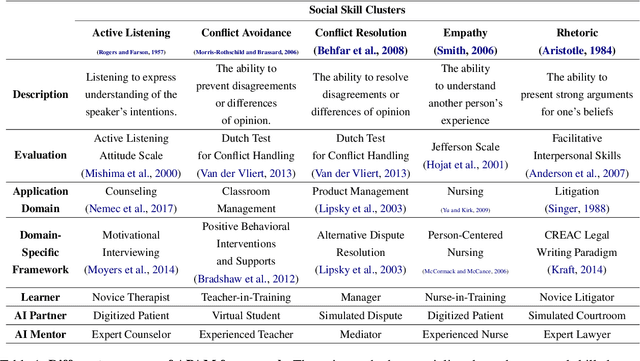
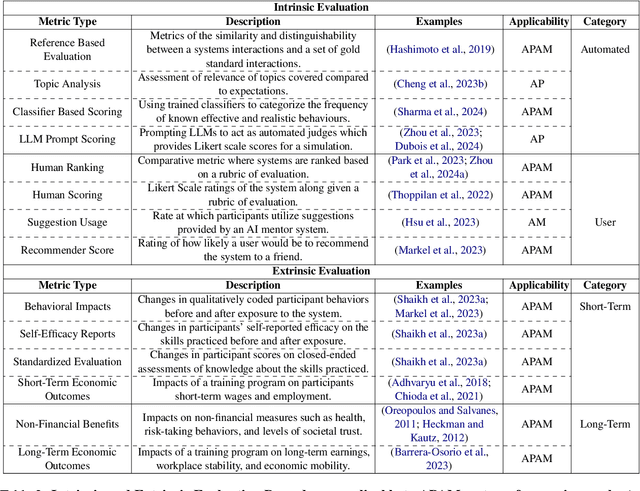
People rely on social skills like conflict resolution to communicate effectively and to thrive in both work and personal life. However, practice environments for social skills are typically out of reach for most people. How can we make social skill training more available, accessible, and inviting? Drawing upon interdisciplinary research from communication and psychology, this perspective paper identifies social skill barriers to enter specialized fields. Then we present a solution that leverages large language models for social skill training via a generic framework. Our AI Partner, AI Mentor framework merges experiential learning with realistic practice and tailored feedback. This work ultimately calls for cross-disciplinary innovation to address the broader implications for workforce development and social equality.
Impressions: Understanding Visual Semiotics and Aesthetic Impact
Oct 27, 2023



Is aesthetic impact different from beauty? Is visual salience a reflection of its capacity for effective communication? We present Impressions, a novel dataset through which to investigate the semiotics of images, and how specific visual features and design choices can elicit specific emotions, thoughts and beliefs. We posit that the impactfulness of an image extends beyond formal definitions of aesthetics, to its success as a communicative act, where style contributes as much to meaning formation as the subject matter. However, prior image captioning datasets are not designed to empower state-of-the-art architectures to model potential human impressions or interpretations of images. To fill this gap, we design an annotation task heavily inspired by image analysis techniques in the Visual Arts to collect 1,440 image-caption pairs and 4,320 unique annotations exploring impact, pragmatic image description, impressions, and aesthetic design choices. We show that existing multimodal image captioning and conditional generation models struggle to simulate plausible human responses to images. However, this dataset significantly improves their ability to model impressions and aesthetic evaluations of images through fine-tuning and few-shot adaptation.
CoAnnotating: Uncertainty-Guided Work Allocation between Human and Large Language Models for Data Annotation
Oct 24, 2023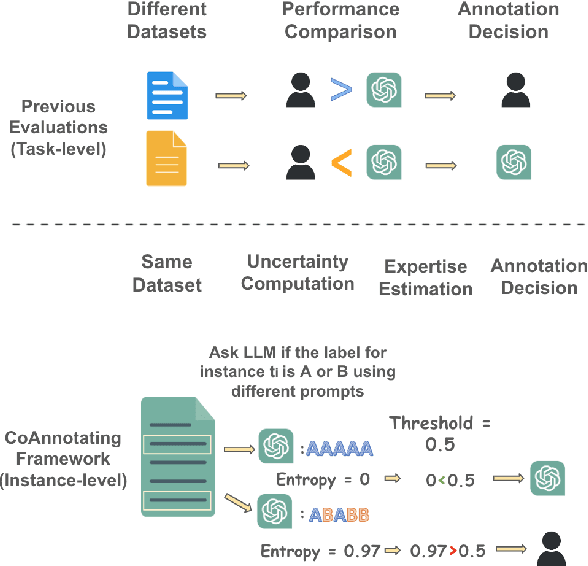

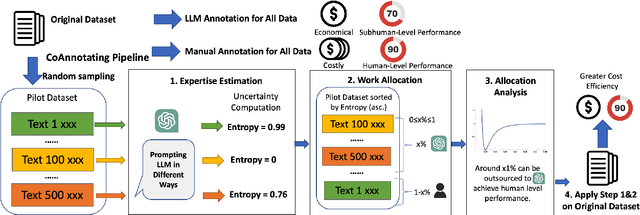
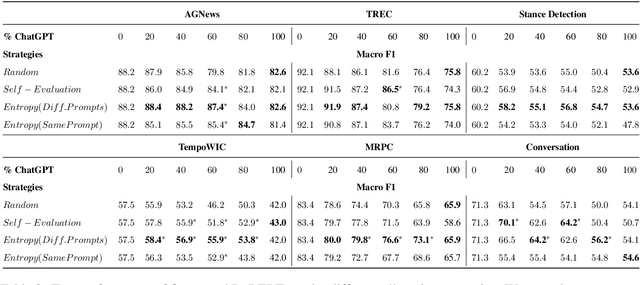
Annotated data plays a critical role in Natural Language Processing (NLP) in training models and evaluating their performance. Given recent developments in Large Language Models (LLMs), models such as ChatGPT demonstrate zero-shot capability on many text-annotation tasks, comparable with or even exceeding human annotators. Such LLMs can serve as alternatives for manual annotation, due to lower costs and higher scalability. However, limited work has leveraged LLMs as complementary annotators, nor explored how annotation work is best allocated among humans and LLMs to achieve both quality and cost objectives. We propose CoAnnotating, a novel paradigm for Human-LLM co-annotation of unstructured texts at scale. Under this framework, we utilize uncertainty to estimate LLMs' annotation capability. Our empirical study shows CoAnnotating to be an effective means to allocate work from results on different datasets, with up to 21% performance improvement over random baseline. For code implementation, see https://github.com/SALT-NLP/CoAnnotating.
Modeling Cross-Cultural Pragmatic Inference with Codenames Duet
Jun 04, 2023



Pragmatic reference enables efficient interpersonal communication. Prior work uses simple reference games to test models of pragmatic reasoning, often with unidentified speakers and listeners. In practice, however, speakers' sociocultural background shapes their pragmatic assumptions. For example, readers of this paper assume NLP refers to "Natural Language Processing," and not "Neuro-linguistic Programming." This work introduces the Cultural Codes dataset, which operationalizes sociocultural pragmatic inference in a simple word reference game. Cultural Codes is based on the multi-turn collaborative two-player game, Codenames Duet. Our dataset consists of 794 games with 7,703 turns, distributed across 153 unique players. Alongside gameplay, we collect information about players' personalities, values, and demographics. Utilizing theories of communication and pragmatics, we predict each player's actions via joint modeling of their sociocultural priors and the game context. Our experiments show that accounting for background characteristics significantly improves model performance for tasks related to both clue giving and guessing, indicating that sociocultural priors play a vital role in gameplay decisions.
TADA: Task-Agnostic Dialect Adapters for English
May 26, 2023Large Language Models, the dominant starting point for Natural Language Processing (NLP) applications, fail at a higher rate for speakers of English dialects other than Standard American English (SAE). Prior work addresses this using task-specific data or synthetic data augmentation, both of which require intervention for each dialect and task pair. This poses a scalability issue that prevents the broad adoption of robust dialectal English NLP. We introduce a simple yet effective method for task-agnostic dialect adaptation by aligning non-SAE dialects using adapters and composing them with task-specific adapters from SAE. Task-Agnostic Dialect Adapters (TADA) improve dialectal robustness on 4 dialectal variants of the GLUE benchmark without task-specific supervision.