 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodness-of-pronunciation without phoneme time alignment
Mar 26, 2026In speech evaluation, an Automatic Speech Recognition (ASR) model often computes time boundaries and phoneme posteriors for input features. However, limited data for ASR training hinders expansion of speech evaluation to low-resource languages. Open-source weakly-supervised models are capable of ASR over many languages, but they are frame-asynchronous and not phonemic, hindering feature extraction for speech evaluation. This paper proposes to overcome incompatibilities for feature extraction with weakly-supervised models, easing expansion of speech evaluation to low-resource languages. Phoneme posteriors are computed by mapping ASR hypotheses to a phoneme confusion network. Word instead of phoneme-level speaking rate and duration are used. Phoneme and frame-level features are combined using a cross-attention architecture, obviating phoneme time alignment. This performs comparably with standard frame-synchronous features on English speechocean762 and low-resource Tamil datasets.
LoASR-Bench: Evaluating Large Speech Language Models on Low-Resource Automatic Speech Recognition Across Language Families
Mar 20, 2026Large language models (LLMs) have driven substantial advances in speech language models (SpeechLMs), yielding strong performance in automatic speech recognition (ASR) under high-resource conditions. However, existing benchmarks predominantly focus on high-resource languages, leaving the ASR behavior of SpeechLMs in low-resource languages insufficiently understood. This gap is critical, as practical ASR systems must reliably support low-resource languages and generalize across diverse language families, and it directly hinders the deployment of SpeechLM-based ASR in real-world multilingual scenarios. As a result, it is essential to evaluate SpeechLMs on low-resource languages to ensure their generalizability across different language families. To address this problem, we propose \textbf{LoASR-Bench}, a comprehensive benchmark designed to evaluate \textbf{lo}w-resource \textbf{a}utomatic \textbf{s}peech \textbf{r}ecognition (\textbf{ASR}) of the latest SpeechLMs across diverse language families. LoASR-Bench comprises 25 languages from 9 language families, featuring both Latin and non-Latin scripts, enabling cross-linguistic and cross-script assessment of ASR performance of current SpeechLMs. Experimental results highlight the limitations of the latest SpeechLMs in handling real-world low-resource languages.
InfoDensity: Rewarding Information-Dense Traces for Efficient Reasoning
Mar 18, 2026Large Language Models (LLMs) with extended reasoning capabilities often generate verbose and redundant reasoning traces, incurring unnecessary computational cost. While existing reinforcement learning approaches address this by optimizing final response length, they neglect the quality of intermediate reasoning steps, leaving models vulnerable to reward hacking. We argue that verbosity is not merely a length problem, but a symptom of poor intermediate reasoning quality. To investigate this, we conduct an empirical study tracking the conditional entropy of the answer distribution across reasoning steps. We find that high-quality reasoning traces exhibit two consistent properties: low uncertainty convergence and monotonic progress. These findings suggest that high-quality reasoning traces are informationally dense, that is, each step contributes meaningful entropy reduction relative to the total reasoning length. Motivated by this, we propose InfoDensity, a reward framework for RL training that combines an AUC-based reward and a monotonicity reward as a unified measure of reasoning quality, weighted by a length scaling term that favors achieving equivalent quality more concisely. Experiments on mathematical reasoning benchmarks demonstrate that InfoDensity matches or surpasses state-of-the-art baselines in accuracy while significantly reducing token usage, achieving a strong accuracy-efficiency trade-off.
The Chicken and Egg Dilemma: Co-optimizing Data and Model Configurations for LLMs
Feb 09, 2026Co-optimizing data and model configurations for training LLMs presents a classic chicken-and-egg dilemma: The best training data configuration (e.g., data mixture) for a downstream task depends on the chosen model configuration (e.g., model architecture), and vice versa. However, jointly optimizing both data and model configurations is often deemed intractable, and existing methods focus on either data or model optimization without considering their interaction. We introduce JoBS, an approach that uses a scaling-law-inspired performance predictor to aid Bayesian optimization (BO) in jointly optimizing LLM training data and model configurations efficiently. JoBS allocates a portion of the optimization budget to learn an LLM performance predictor that predicts how promising a training configuration is from a small number of training steps. The remaining budget is used to perform BO entirely with the predictor, effectively amortizing the cost of running full-training runs. We study JoBS's average regret and devise the optimal budget allocation to minimize regret. JoBS outperforms existing multi-fidelity BO baselines, as well as data and model optimization approaches across diverse LLM tasks under the same optimization budget.
Programming over Thinking: Efficient and Robust Multi-Constraint Planning
Jan 14, 2026Multi-constraint planning involves identifying, evaluating, and refining candidate plans while satisfying multiple, potentially conflicting constraints. Existing large language model (LLM) approaches face fundamental limitations in this domain. Pure reasoning paradigms, which rely on long natural language chains, are prone to inconsistency, error accumulation, and prohibitive cost as constraints compound. Conversely, LLMs combined with coding- or solver-based strategies lack flexibility: they often generate problem-specific code from scratch or depend on fixed solvers, failing to capture generalizable logic across diverse problems. To address these challenges, we introduce the Scalable COde Planning Engine (SCOPE), a framework that disentangles query-specific reasoning from generic code execution. By separating reasoning from execution, SCOPE produces solver functions that are consistent, deterministic, and reusable across queries while requiring only minimal changes to input parameters. SCOPE achieves state-of-the-art performance while lowering cost and latency. For example, with GPT-4o, it reaches 93.1% success on TravelPlanner, a 61.6% gain over the best baseline (CoT) while cutting inference cost by 1.4x and time by ~4.67x. Code is available at https://github.com/DerrickGXD/SCOPE.
MORE: Multi-Objective Adversarial Attacks on Speech Recognition
Jan 05, 2026The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy degradation under adversarial attacks, robustness with respect to efficiency remains largely unexplored. This narrow focus provides only a partial understanding of ASR model vulnerabilities. To address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. We introduce MORE, a multi-objective repetitive doubling encouragement attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion-anchoring mechanism. Specifically, we reformulate multi-objective adversarial optimization into a hierarchical framework that sequentially achieves the dual objectives. To further amplify effectiveness, we propose a novel repetitive encouragement doubling objective (REDO) that induces duplicative text generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, triggered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effectiveness in multi-objective adversarial attack.
Minimal Clips, Maximum Salience: Long Video Summarization via Key Moment Extraction
Dec 12, 2025Vision-Language Models (VLMs) are able to process increasingly longer videos. Yet, important visual information is easily lost throughout the entire context and missed by VLMs. Also, it is important to design tools that enable cost-effective analysis of lengthy video content. In this paper, we propose a clip selection method that targets key video moments to be included in a multimodal summary. We divide the video into short clips and generate compact visual descriptions of each using a lightweight video captioning model. These are then passed to a large language model (LLM), which selects the K clips containing the most relevant visual information for a multimodal summary. We evaluate our approach on reference clips for the task, automatically derived from full human-annotated screenplays and summaries in the MovieSum dataset. We further show that these reference clips (less than 6% of the movie) are sufficient to build a complete multimodal summary of the movies in MovieSum. Using our clip selection method, we achieve a summarization performance close to that of these reference clips while capturing substantially more relevant video information than random clip selection. Importantly, we maintain low computational cost by relying on a lightweight captioning model.
The Imperfect Learner: Incorporating Developmental Trajectories in Memory-based Student Simulation
Nov 08, 2025
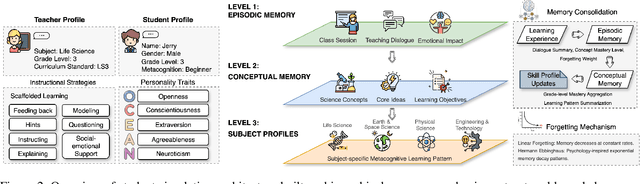
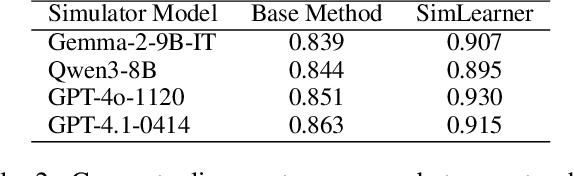
User simulation is important for developing and evaluating human-centered AI, yet current student simulation in educational applications has significant limitations. Existing approaches focus on single learning experiences and do not account for students' gradual knowledge construction and evolving skill sets. Moreover, large language models are optimized to produce direct and accurate responses, making it challenging to represent the incomplete understanding and developmental constraints that characterize real learners. In this paper, we introduce a novel framework for memory-based student simulation that incorporates developmental trajectories through a hierarchical memory mechanism with structured knowledge representation. The framework also integrates metacognitive processes and personality traits to enrich the individual learner profiling, through dynamical consolidation of both cognitive development and personal learning characteristics. In practice, we implement a curriculum-aligned simulator grounded on the Next Generation Science Standards. Experimental results show that our approach can effectively reflect the gradual nature of knowledge development and the characteristic difficulties students face, providing a more accurate representation of learning processes.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
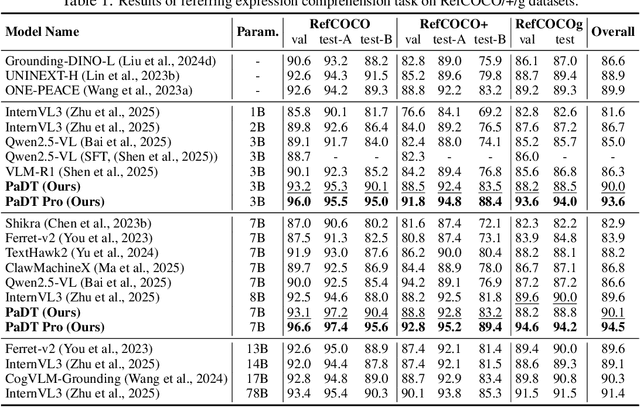

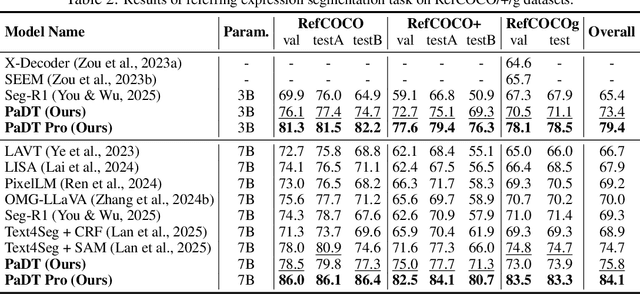
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
Persuasion Dynamics in LLMs: Investigating Robustness and Adaptability in Knowledge and Safety with DuET-PD
Aug 24, 2025Large Language Models (LLMs) can struggle to balance gullibility to misinformation and resistance to valid corrections in persuasive dialogues, a critical challenge for reliable deployment. We introduce DuET-PD (Dual Evaluation for Trust in Persuasive Dialogues), a framework evaluating multi-turn stance-change dynamics across dual dimensions: persuasion type (corrective/misleading) and domain (knowledge via MMLU-Pro, and safety via SALAD-Bench). We find that even a state-of-the-art model like GPT-4o achieves only 27.32% accuracy in MMLU-Pro under sustained misleading persuasions. Moreover, results reveal a concerning trend of increasing sycophancy in newer open-source models. To address this, we introduce Holistic DPO, a training approach balancing positive and negative persuasion examples. Unlike prompting or resist-only training, Holistic DPO enhances both robustness to misinformation and receptiveness to corrections, improving Llama-3.1-8B-Instruct's accuracy under misleading persuasion in safety contexts from 4.21% to 76.54%. These contributions offer a pathway to developing more reliable and adaptable LLMs for multi-turn dialogue. Code is available at https://github.com/Social-AI-Studio/DuET-PD.