 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoDensity: Rewarding Information-Dense Traces for Efficient Reasoning
Mar 18, 2026Large Language Models (LLMs) with extended reasoning capabilities often generate verbose and redundant reasoning traces, incurring unnecessary computational cost. While existing reinforcement learning approaches address this by optimizing final response length, they neglect the quality of intermediate reasoning steps, leaving models vulnerable to reward hacking. We argue that verbosity is not merely a length problem, but a symptom of poor intermediate reasoning quality. To investigate this, we conduct an empirical study tracking the conditional entropy of the answer distribution across reasoning steps. We find that high-quality reasoning traces exhibit two consistent properties: low uncertainty convergence and monotonic progress. These findings suggest that high-quality reasoning traces are informationally dense, that is, each step contributes meaningful entropy reduction relative to the total reasoning length. Motivated by this, we propose InfoDensity, a reward framework for RL training that combines an AUC-based reward and a monotonicity reward as a unified measure of reasoning quality, weighted by a length scaling term that favors achieving equivalent quality more concisely. Experiments on mathematical reasoning benchmarks demonstrate that InfoDensity matches or surpasses state-of-the-art baselines in accuracy while significantly reducing token usage, achieving a strong accuracy-efficiency trade-off.
IFEval-Audio: Benchmarking Instruction-Following Capability in Audio-based Large Language Models
May 22, 2025Large language models (LLMs) have demonstrated strong instruction-following capabilities in text-based tasks. However, this ability often deteriorates in multimodal models after alignment with non-text modalities such as images or audio. While several recent efforts have investigated instruction-following performance in text and vision-language models, instruction-following in audio-based large language models remains largely unexplored. To bridge this gap, we introduce IFEval-Audio, a novel evaluation dataset designed to assess the ability to follow instructions in an audio LLM. IFEval-Audio contains 280 audio-instruction-answer triples across six diverse dimensions: Content, Capitalization, Symbol, List Structure, Length, and Format. Each example pairs an audio input with a text instruction, requiring the model to generate an output that follows a specified structure. We benchmark state-of-the-art audio LLMs on their ability to follow audio-involved instructions. The dataset is released publicly to support future research in this emerging area.
Towards Spoken Mathematical Reasoning: Benchmarking Speech-based Models over Multi-faceted Math Problems
May 21, 2025Recent advances in large language models (LLMs) and multimodal LLMs (MLLMs) have led to strong reasoning ability across a wide range of tasks. However, their ability to perform mathematical reasoning from spoken input remains underexplored. Prior studies on speech modality have mostly focused on factual speech understanding or simple audio reasoning tasks, providing limited insight into logical step-by-step reasoning, such as that required for mathematical problem solving. To address this gap, we introduce Spoken Math Question Answering (Spoken-MQA), a new benchmark designed to evaluate the mathematical reasoning capabilities of speech-based models, including both cascade models (ASR + LLMs) and end-to-end speech LLMs. Spoken-MQA covers a diverse set of math problems, including pure arithmetic, single-step and multi-step contextual reasoning, and knowledge-oriented reasoning problems, all presented in unambiguous natural spoken language. Through extensive experiments, we find that: (1) while some speech LLMs perform competitively on contextual reasoning tasks involving basic arithmetic, they still struggle with direct arithmetic problems; (2) current LLMs exhibit a strong bias toward symbolic mathematical expressions written in LaTex and have difficulty interpreting verbalized mathematical expressions; and (3) mathematical knowledge reasoning abilities are significantly degraded in current speech LLMs.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
Jan 02, 2025



Singlish, a Creole language rooted in English, is a key focus in linguistic research within multilingual and multicultural contexts. However, its spoken form remains underexplored, limiting insights into its linguistic structure and applications. To address this gap, we standardize and annotate the largest spoken Singlish corpus, introducing the Multitask National Speech Corpus (MNSC). These datasets support diverse tasks, including Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), and Paralinguistic Question Answering (PQA). We release standardized splits and a human-verified test set to facilitate further research. Additionally, we propose SingAudioLLM, a multi-task multimodal model leveraging multimodal large language models to handle these tasks concurrently. Experiments reveal our models adaptability to Singlish context, achieving state-of-the-art performance and outperforming prior models by 10-30% in comparison with other AudioLLMs and cascaded solutions.
CoinMath: Harnessing the Power of Coding Instruction for Math LLMs
Dec 16, 2024



Large Language Models (LLMs) have shown strong performance in solving mathematical problems, with code-based solutions proving particularly effective. However, the best practice to leverage coding instruction data to enhance mathematical reasoning remains underexplored. This study investigates three key questions: (1) How do different coding styles of mathematical code-based rationales impact LLMs' learning performance? (2) Can general-domain coding instructions improve performance? (3) How does integrating textual rationales with code-based ones during training enhance mathematical reasoning abilities? Our findings reveal that code-based rationales with concise comments, descriptive naming, and hardcoded solutions are beneficial, while improvements from general-domain coding instructions and textual rationales are relatively minor. Based on these insights, we propose CoinMath, a learning strategy designed to enhance mathematical reasoning by diversifying the coding styles of code-based rationales. CoinMath generates a variety of code-based rationales incorporating concise comments, descriptive naming conventions, and hardcoded solutions. Experimental results demonstrate that CoinMath significantly outperforms its baseline model, MAmmoTH, one of the SOTA math LLMs.
Efficient Human-Object-Interaction (EHOI) Detection via Interaction Label Coding and Conditional Decision
Aug 13, 2024Human-Object Interaction (HOI) detection is a fundamental task in image understanding. While deep-learning-based HOI methods provide high performance in terms of mean Average Precision (mAP), they are computationally expensive and opaque in training and inference processes. An Efficient HOI (EHOI) detector is proposed in this work to strike a good balance between detection performance, inference complexity, and mathematical transparency. EHOI is a two-stage method. In the first stage, it leverages a frozen object detector to localize the objects and extract various features as intermediate outputs. In the second stage, the first-stage outputs predict the interaction type using the XGBoost classifier. Our contributions include the application of error correction codes (ECCs) to encode rare interaction cases, which reduces the model size and the complexity of the XGBoost classifier in the second stage. Additionally, we provide a mathematical formulation of the relabeling and decision-making process. Apart from the architecture, we present qualitative results to explain the functionalities of the feedforward modules. Experimental results demonstrate the advantages of ECC-coded interaction labels and the excellent balance of detection performance and complexity of the proposed EHOI method.
Word Embedding Dimension Reduction via Weakly-Supervised Feature Selection
Jul 17, 2024



As a fundamental task in natural language processing, word embedding converts each word into a representation in a vector space. A challenge with word embedding is that as the vocabulary grows, the vector space's dimension increases and it can lead to a vast model size. Storing and processing word vectors are resource-demanding, especially for mobile edge-devices applications. This paper explores word embedding dimension reduction. To balance computational costs and performance, we propose an efficient and effective weakly-supervised feature selection method, named WordFS. It has two variants, each utilizing novel criteria for feature selection. Experiments conducted on various tasks (e.g., word and sentence similarity and binary and multi-class classification) indicate that the proposed WordFS model outperforms other dimension reduction methods at lower computational costs.
Confidence-Aware Sub-Structure Beam Search (CABS): Mitigating Hallucination in Structured Data Generation with Large Language Models
May 30, 2024



Large Language Models (LLMs) have facilitated structured data generation, with applications in domains like tabular data, document databases, product catalogs, etc. However, concerns persist about generation veracity due to incorrect references or hallucinations, necessitating the incorporation of some form of model confidence for mitigation. Existing confidence estimation methods on LLM generations primarily focus on the confidence at the individual token level or the entire output sequence level, limiting their applicability to structured data generation, which consists of an intricate mix of both independent and correlated entries at the sub-structure level. In this paper, we first investigate confidence estimation methods for generated sub-structure-level data. We introduce the concept of Confidence Network that applies on the hidden state of the LLM transformer, as a more targeted estimate than the traditional token conditional probability. We further propose Confidence-Aware sub-structure Beam Search (CABS), a novel decoding method operating at the sub-structure level in structured data generation. CABS enhances the faithfulness of structured data generation by considering confidence scores from the Confidence Network for each sub-structure-level data and iteratively refining the prompts. Results show that CABS outperforms traditional token-level beam search for structured data generation by 16.7% Recall at 90% precision averagely on the problem of product attribute generation.
CRAFT: Extracting and Tuning Cultural Instructions from the Wild
May 06, 2024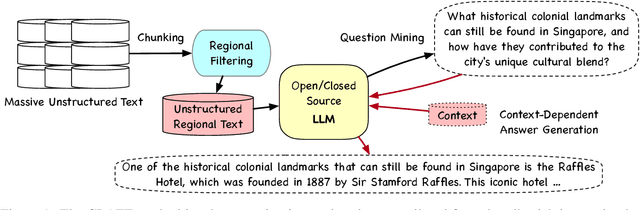
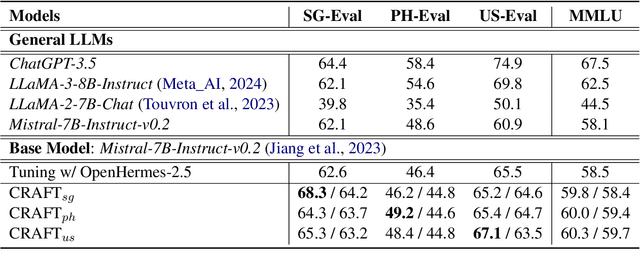

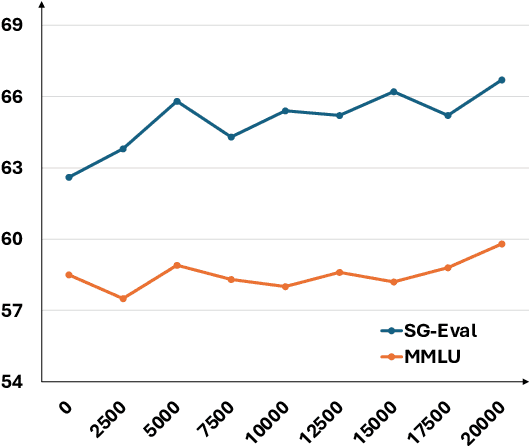
Large language models (LLMs) have rapidly evolved as the foundation of various natural language processing (NLP) applications. Despite their wide use cases, their understanding of culturally-related concepts and reasoning remains limited. Meantime, there is a significant need to enhance these models' cultural reasoning capabilities, especially concerning underrepresented regions. This paper introduces a novel pipeline for extracting high-quality, culturally-related instruction tuning datasets from vast unstructured corpora. We utilize a self-instruction generation pipeline to identify cultural concepts and trigger instruction. By integrating with a general-purpose instruction tuning dataset, our model demonstrates enhanced capabilities in recognizing and understanding regional cultural nuances, thereby enhancing its reasoning capabilities. We conduct experiments across three regions: Singapore, the Philippines, and the United States, achieving performance improvement of up to 6%. Our research opens new avenues for extracting cultural instruction tuning sets directly from unstructured data, setting a precedent for future innovations in the field.