 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSeal: Good, Fast, and Cheap Construction of an Open-Source Southeast Asian LLM via Parallel Data
Feb 02, 2026Large language models (LLMs) have proven to be effective tools for a wide range of natural language processing (NLP) applications. Although many LLMs are multilingual, most remain English-centric and perform poorly on low-resource languages. Recently, several Southeast Asia-focused LLMs have been developed, but none are truly open source, as they do not publicly disclose their training data. Truly open-source models are important for transparency and for enabling a deeper and more precise understanding of LLM internals and development, including biases, generalization, and multilinguality. Motivated by recent advances demonstrating the effectiveness of parallel data in improving multilingual performance, we conduct controlled and comprehensive experiments to study the effectiveness of parallel data in continual pretraining of LLMs. Our findings show that using only parallel data is the most effective way to extend an LLM to new languages. Using just 34.7B tokens of parallel data and 180 hours on 8x NVIDIA H200 GPUs, we built OpenSeal, the first truly open Southeast Asian LLM that rivals the performance of existing models of similar size.
Parametric Knowledge is Not All You Need: Toward Honest Large Language Models via Retrieval of Pretraining Data
Jan 29, 2026Large language models (LLMs) are highly capable of answering questions, but they are often unaware of their own knowledge boundary, i.e., knowing what they know and what they don't know. As a result, they can generate factually incorrect responses on topics they do not have enough knowledge of, commonly known as hallucination. Rather than hallucinating, a language model should be more honest and respond with "I don't know" when it does not have enough knowledge about a topic. Many methods have been proposed to improve LLM honesty, but their evaluations lack robustness, as they do not take into account the knowledge that the LLM has ingested during its pretraining. In this paper, we propose a more robust evaluation benchmark dataset for LLM honesty by utilizing Pythia, a truly open LLM with publicly available pretraining data. In addition, we also propose a novel method for harnessing the pretraining data to build a more honest LLM.
Just Go Parallel: Improving the Multilingual Capabilities of Large Language Models
Jun 16, 2025Large language models (LLMs) have demonstrated impressive translation capabilities even without being explicitly trained on parallel data. This remarkable property has led some to believe that parallel data is no longer necessary for building multilingual language models. While some attribute this to the emergent abilities of LLMs due to scale, recent work suggests that it is actually caused by incidental bilingual signals present in the training data. Various methods have been proposed to maximize the utility of parallel data to enhance the multilingual capabilities of multilingual encoder-based and encoder-decoder language models. However, some decoder-based LLMs opt to ignore parallel data instead. In this work, we conduct a systematic study on the impact of adding parallel data on LLMs' multilingual capabilities, focusing specifically on translation and multilingual common-sense reasoning. Through controlled experiments, we demonstrate that parallel data can significantly improve LLMs' multilingual capabilities.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Just What You Desire: Constrained Timeline Summarization with Self-Reflection for Enhanced Relevance
Dec 23, 2024



Given news articles about an entity, such as a public figure or organization, timeline summarization (TLS) involves generating a timeline that summarizes the key events about the entity. However, the TLS task is too underspecified, since what is of interest to each reader may vary, and hence there is not a single ideal or optimal timeline. In this paper, we introduce a novel task, called Constrained Timeline Summarization (CTLS), where a timeline is generated in which all events in the timeline meet some constraint. An example of a constrained timeline concerns the legal battles of Tiger Woods, where only events related to his legal problems are selected to appear in the timeline. We collected a new human-verified dataset of constrained timelines involving 47 entities and 5 constraints per entity. We propose an approach that employs a large language model (LLM) to summarize news articles according to a specified constraint and cluster them to identify key events to include in a constrained timeline. In addition, we propose a novel self-reflection method during summary generation, demonstrating that this approach successfully leads to improved performance.
Efficient and Interpretable Grammatical Error Correction with Mixture of Experts
Oct 30, 2024Error type information has been widely used to improve the performance of grammatical error correction (GEC) models, whether for generating corrections, re-ranking them, or combining GEC models. Combining GEC models that have complementary strengths in correcting different error types is very effective in producing better corrections. However, system combination incurs a high computational cost due to the need to run inference on the base systems before running the combination method itself. Therefore, it would be more efficient to have a single model with multiple sub-networks that specialize in correcting different error types. In this paper, we propose a mixture-of-experts model, MoECE, for grammatical error correction. Our model successfully achieves the performance of T5-XL with three times fewer effective parameters. Additionally, our model produces interpretable corrections by also identifying the error type during inference.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024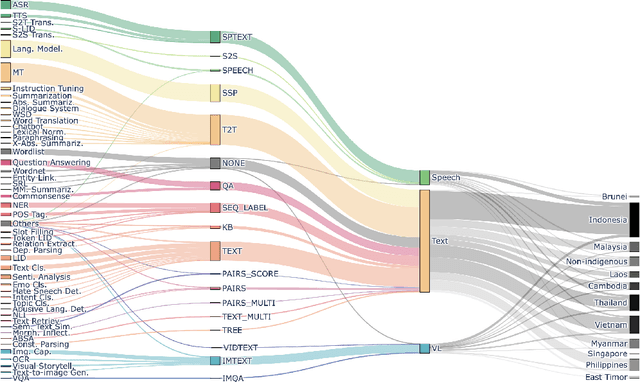
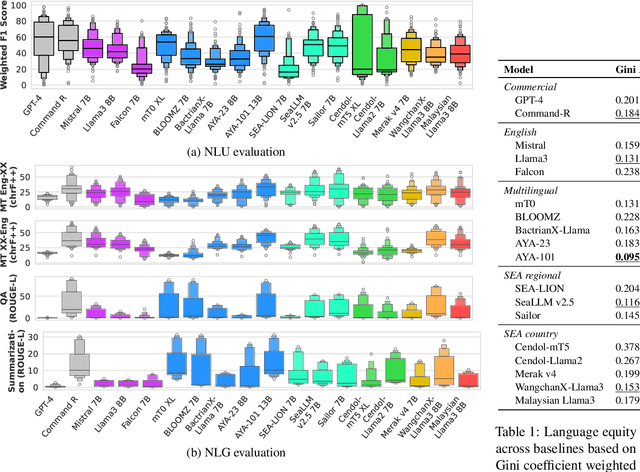
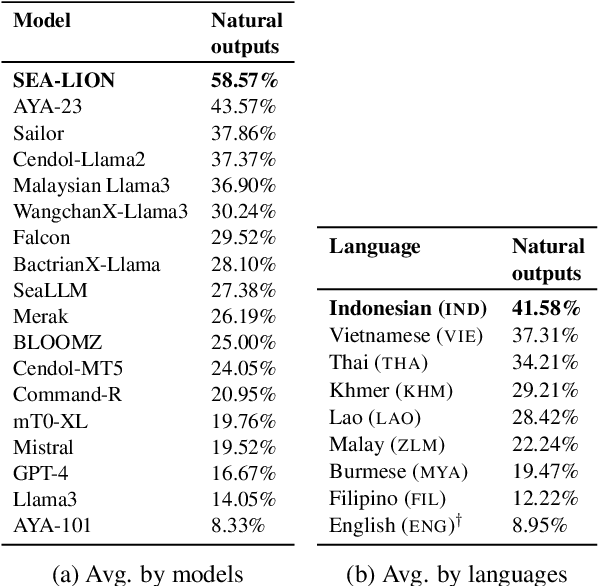
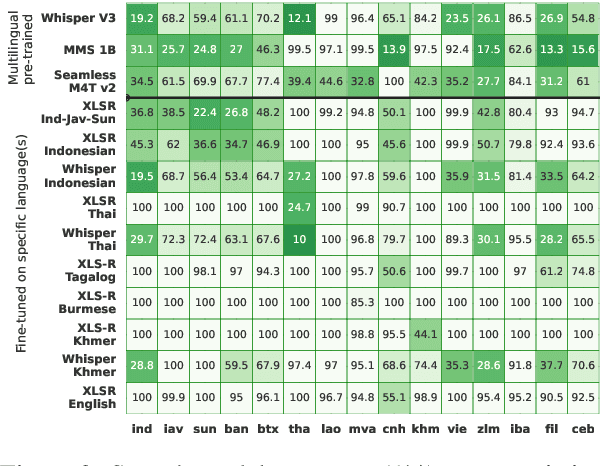
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
System Combination via Quality Estimation for Grammatical Error Correction
Oct 23, 2023



Quality estimation models have been developed to assess the corrections made by grammatical error correction (GEC) models when the reference or gold-standard corrections are not available. An ideal quality estimator can be utilized to combine the outputs of multiple GEC systems by choosing the best subset of edits from the union of all edits proposed by the GEC base systems. However, we found that existing GEC quality estimation models are not good enough in differentiating good corrections from bad ones, resulting in a low F0.5 score when used for system combination. In this paper, we propose GRECO, a new state-of-the-art quality estimation model that gives a better estimate of the quality of a corrected sentence, as indicated by having a higher correlation to the F0.5 score of a corrected sentence. It results in a combined GEC system with a higher F0.5 score. We also propose three methods for utilizing GEC quality estimation models for system combination with varying generality: model-agnostic, model-agnostic with voting bias, and model-dependent method. The combined GEC system outperforms the state of the art on the CoNLL-2014 test set and the BEA-2019 test set, achieving the highest F0.5 scores published to date.
Grammatical Error Correction: A Survey of the State of the Art
Nov 16, 2022Grammatical Error Correction (GEC) is the task of automatically detecting and correcting errors in text. The task not only includes the correction of grammatical errors, such as missing prepositions and mismatched subject-verb agreement, but also orthographic and semantic errors, such as misspellings and word choice errors respectively. The field has seen significant progress in the last decade, motivated in part by a series of five shared tasks, which drove the development of rule-based methods, statistical classifiers, statistical machine translation, and finally neural machine translation systems which represent the current dominant state of the art. In this survey paper, we condense the field into a single article and first outline some of the linguistic challenges of the task, introduce the most popular datasets that are available to researchers (for both English and other languages), and summarise the various methods and techniques that have been developed with a particular focus on artificial error generation. We next describe the many different approaches to evaluation as well as concerns surrounding metric reliability, especially in relation to subjective human judgements, before concluding with an overview of recent progress and suggestions for future work and remaining challenges. We hope that this survey will serve as comprehensive resource for researchers who are new to the field or who want to be kept apprised of recent developments.