 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrosslingual Reasoning through Test-Time Scaling
May 08, 2025Reasoning capabilities of large language models are primarily studied for English, even when pretrained models are multilingual. In this work, we investigate to what extent English reasoning finetuning with long chain-of-thoughts (CoTs) can generalize across languages. First, we find that scaling up inference compute for English-centric reasoning language models (RLMs) improves multilingual mathematical reasoning across many languages including low-resource languages, to an extent where they outperform models twice their size. Second, we reveal that while English-centric RLM's CoTs are naturally predominantly English, they consistently follow a quote-and-think pattern to reason about quoted non-English inputs. Third, we discover an effective strategy to control the language of long CoT reasoning, and we observe that models reason better and more efficiently in high-resource languages. Finally, we observe poor out-of-domain reasoning generalization, in particular from STEM to cultural commonsense knowledge, even for English. Overall, we demonstrate the potentials, study the mechanisms and outline the limitations of crosslingual generalization of English reasoning test-time scaling. We conclude that practitioners should let English-centric RLMs reason in high-resource languages, while further work is needed to improve reasoning in low-resource languages and out-of-domain contexts.
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Qorgau: Evaluating LLM Safety in Kazakh-Russian Bilingual Contexts
Feb 19, 2025Large language models (LLMs) are known to have the potential to generate harmful content, posing risks to users. While significant progress has been made in developing taxonomies for LLM risks and safety evaluation prompts, most studies have focused on monolingual contexts, primarily in English. However, language- and region-specific risks in bilingual contexts are often overlooked, and core findings can diverge from those in monolingual settings. In this paper, we introduce Qorgau, a novel dataset specifically designed for safety evaluation in Kazakh and Russian, reflecting the unique bilingual context in Kazakhstan, where both Kazakh (a low-resource language) and Russian (a high-resource language) are spoken. Experiments with both multilingual and language-specific LLMs reveal notable differences in safety performance, emphasizing the need for tailored, region-specific datasets to ensure the responsible and safe deployment of LLMs in countries like Kazakhstan. Warning: this paper contains example data that may be offensive, harmful, or biased.
KazMMLU: Evaluating Language Models on Kazakh, Russian, and Regional Knowledge of Kazakhstan
Feb 18, 2025



Despite having a population of twenty million, Kazakhstan's culture and language remain underrepresented in the field of natural language processing. Although large language models (LLMs) continue to advance worldwide, progress in Kazakh language has been limited, as seen in the scarcity of dedicated models and benchmark evaluations. To address this gap, we introduce KazMMLU, the first MMLU-style dataset specifically designed for Kazakh language. KazMMLU comprises 23,000 questions that cover various educational levels, including STEM, humanities, and social sciences, sourced from authentic educational materials and manually validated by native speakers and educators. The dataset includes 10,969 Kazakh questions and 12,031 Russian questions, reflecting Kazakhstan's bilingual education system and rich local context. Our evaluation of several state-of-the-art multilingual models (Llama-3.1, Qwen-2.5, GPT-4, and DeepSeek V3) demonstrates substantial room for improvement, as even the best-performing models struggle to achieve competitive performance in Kazakh and Russian. These findings underscore significant performance gaps compared to high-resource languages. We hope that our dataset will enable further research and development of Kazakh-centric LLMs. Data and code will be made available upon acceptance.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
Data Laundering: Artificially Boosting Benchmark Results through Knowledge Distillation
Dec 15, 2024In this paper, we show that knowledge distillation can be subverted to manipulate language model benchmark scores, revealing a critical vulnerability in current evaluation practices. We introduce "Data Laundering," a three-phase process analogous to financial money laundering, that enables the covert transfer of benchmark-specific knowledge through seemingly legitimate intermediate training steps. Through extensive experiments with a 2-layer BERT student model, we show how this approach can achieve substantial improvements in benchmark accuracy (up to 75\% on GPQA) without developing genuine reasoning capabilities. Notably, this method can be exploited intentionally or even unintentionally, as researchers may inadvertently adopt this method that inflates scores using knowledge distillation without realizing the implications. While our findings demonstrate the effectiveness of this technique, we present them as a cautionary tale highlighting the urgent need for more robust evaluation methods in AI. This work aims to contribute to the ongoing discussion about evaluation integrity in AI development and the need for benchmarks that more accurately reflect true model capabilities. The code is available at \url{https://github.com/mbzuai-nlp/data_laundering}.
LLM-DetectAIve: a Tool for Fine-Grained Machine-Generated Text Detection
Aug 08, 2024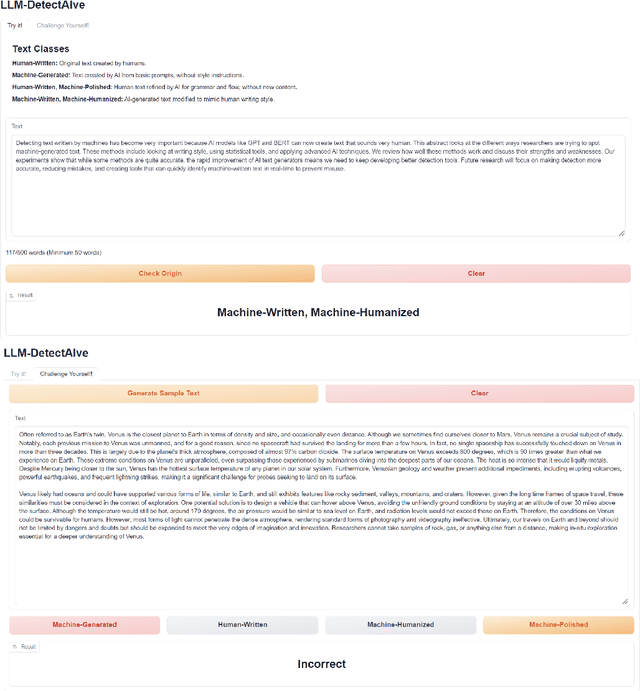
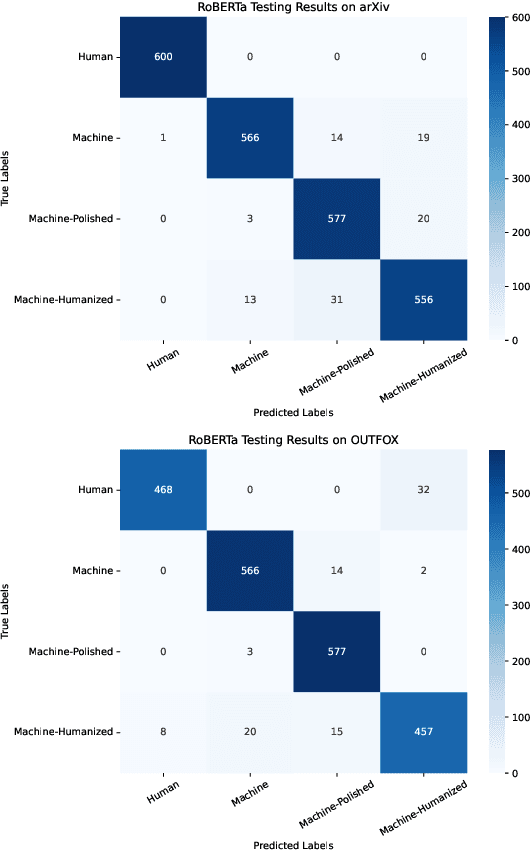
The widespread accessibility of large language models (LLMs) to the general public has significantly amplified the dissemination of machine-generated texts (MGTs). Advancements in prompt manipulation have exacerbated the difficulty in discerning the origin of a text (human-authored vs machinegenerated). This raises concerns regarding the potential misuse of MGTs, particularly within educational and academic domains. In this paper, we present $\textbf{LLM-DetectAIve}$ -- a system designed for fine-grained MGT detection. It is able to classify texts into four categories: human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Contrary to previous MGT detectors that perform binary classification, introducing two additional categories in LLM-DetectiAIve offers insights into the varying degrees of LLM intervention during the text creation. This might be useful in some domains like education, where any LLM intervention is usually prohibited. Experiments show that LLM-DetectAIve can effectively identify the authorship of textual content, proving its usefulness in enhancing integrity in education, academia, and other domains. LLM-DetectAIve is publicly accessible at https://huggingface.co/spaces/raj-tomar001/MGT-New. The video describing our system is available at https://youtu.be/E8eT_bE7k8c.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024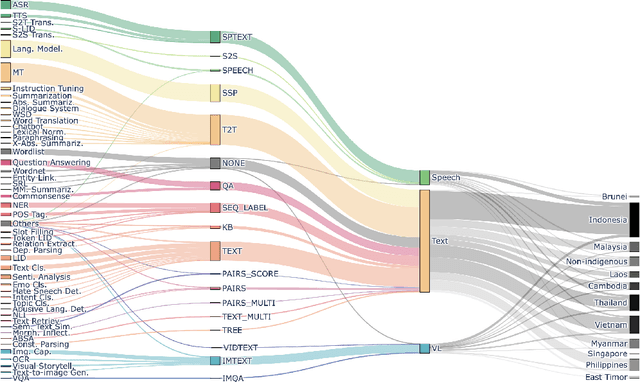
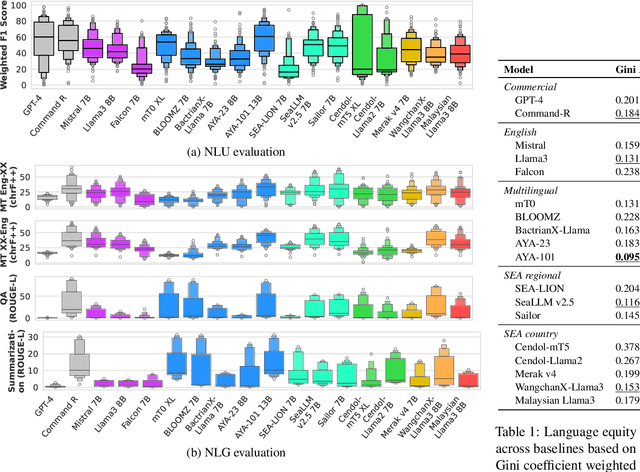
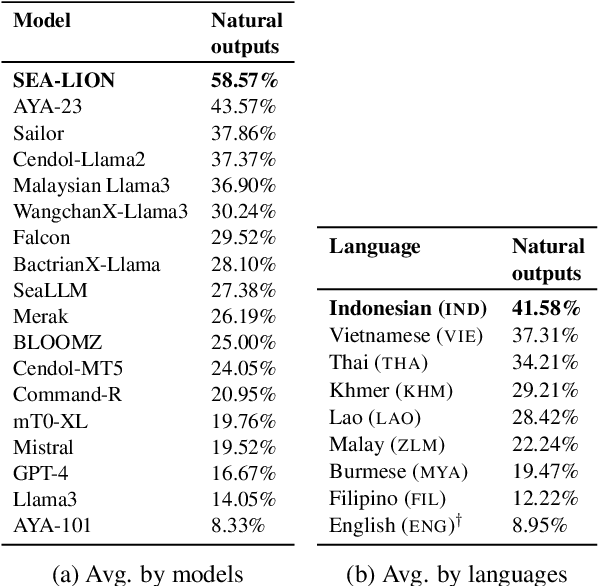
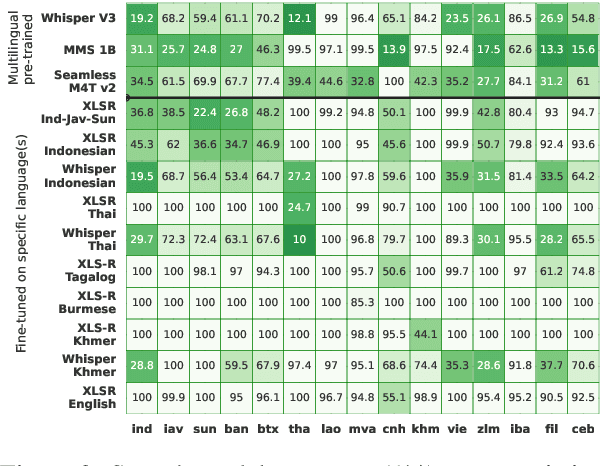
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024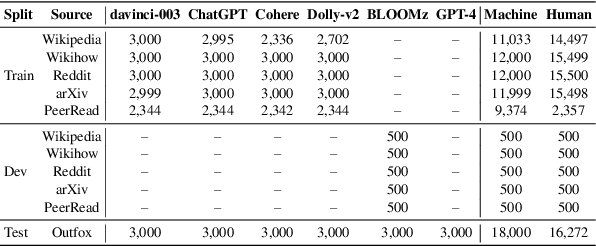

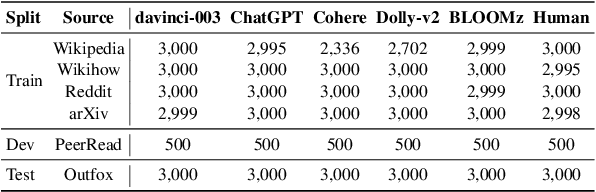

We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables